


AI-first biology: five years on
AI-first biology: five years on
Revisiting my 2019 lecture on why biology was experiencing its AI moment.


Introduction
Five years ago, I was invited to give a talk at the Francis Crick Institute in London for the Image and Data Conference. I spoke about how biology was experiencing its “AI moment”. I argued that traditional scientific exploration, where we discover the intrinsic rules of a system via trial and error-based exploration, was being displaced by an AI-first approach. In this paradigm, we build AI models using data generated by a biological system (e.g. mutations in cancer), and learn the rules of that system by using the model to generate predictions about the biology (e.g. is this mutation associated with cancer).
A few days before we published the 2024 edition of our State of AI Report, the Nobel Prize for Chemistry was awarded to Demis Hassabis and John Jumper for protein structure prediction and to David Baker for computational protein design. Further, the Nobel Prize for Physics was awarded to Geoff Hinton and John Hopfield for foundational discoveries and inventions that enable machine learning with artificial neural networks.
Almost every major AI lab now has at least one research team working on this intersection, some of which have spawned exciting spin-out companies. They’re even beginning to team up with big pharma - Google DeepMind’s Isomorphic Labs has unveiled strategic collaborations with both Eli Lilly and Novartis, which include sizable upfront payments.
In 2019, there were 12 AI-discovered molecules in clinical trials. By the end of 2023, this had jumped to 67.
I’ve had a front-row seat on this journey. Before starting Air Street, I completed a PhD in experimental and computational cancer research. Some of my first investments at Air Street, including Allcyte (since acquired by Exscientia, which is now in a proposed business combination with Recursion) and Valence Discovery (now part of Recursion and operating as Valence Labs), were focused on pushing the boundaries of AI in precision medicine and drug discovery.
As is always the case with science, the journey hasn’t been entirely smooth. Before moving into an evaluation of progress and why I remain optimistic - it’s worth engaging with these views.
The backlash
Over the past 18 months, we’ve seen a chorus of skeptical voices cast doubt on the near-term viability of applying AI to a range of biological questions.
There are certainly setbacks that critics can point to. For example:
Exscientia’s cancer drug candidate EXS-21546 was discontinued in a Phase 1/2 study, after modeling suggested that its likelihood of success was low. An earlier candidate for OCD, developed in partnership with Sumitomo Pharma, was abandoned in 2022 after failing to meet study criteria.
BenevolentAI was forced to lay off staff after BEN-2293, its eczema drug, was found to be no better than the placebo at alleviating symptoms. It also shelved the development of its SaaS offering.
Toronto-based Deep Genomics shuttered its apparently promising Wilson disease program, cut a large number of AI workstreams, and is now up for sale.
Despite being founded close to a decade ago, Atomwise is yet to advance any of its drug candidates to clinical trials and announced a 30% cut in its head count.
As my friend Daniel Cohen, the President of Valence Labs, put it recently: “If you rewind the clock 10 years, there was a lot of hubris, a lot of hype and a lot of big claims that were made that have perhaps not played out in reality”.
In the past, I’ve also warned about people approaching AI as if it’s magic. Back in 2020, I was upfront about the failure of AI-based solutions to have a significant impact during the early phases of the coronavirus pandemic.
This has led some to write off TechBio altogether. Dennis Gong and Ron Boger, PhD students at Harvard-MIT and Berkeley respectively, wrote an influential piece arguing that “biology is not a playing field conducive to systematization” and that while “machine learning can be useful in certain spots such as imaging … its utility past curve fitting and simple linear regression can be unclear for other applications simply because an algorithm cannot learn adequately when the underlying data does not represent the complexity of the problem”.
In my view, the anti-TechBio case overreaches. Listing failures in domains that by definition have high failure rates only tells us so much. While the industry was likely overly-optimistic about how quickly its work would translate into real-world clinical impact, this ignores the significant successes we’ve seen elsewhere.
Progress
Progress in automating or significantly improving lower to mid-level tasks in the lab has been immense, namely in liquid and material handling (e.g. cell culture). These processes provide much-needed data or improve otherwise painstakingly-slow decision making. A recent piece from Nathan Frey at Prescient Design and Eric Dai at Dimension makes a similar argument. Too much has happened in the last half a decade to allow for a comprehensive write-up, but advances in a handful of fields illustrate this nicely.
Protein therapeutics
It’s impossible not to start any account of AI and biology with AlphaFold. Google DeepMind were not content with solving a 50-year old grand challenge in biology and accelerating research across drug discovery and synthetic biology, so upped the ambition levels for AlphaFold 3.
The technical details of AlphaFold 3 have been summarized elsewhere, so we won’t recap them in full here. But in brief, AlphaFold moves beyond protein structure prediction to predict the structure of complexes created by proteins, such as DNA, RNA, and certain ligands - reporting impressive benchmark scores across the board. The team have also switched to a diffusion model into AlphaFold 3, versus the graph equivariance-based AlphaFold 2.
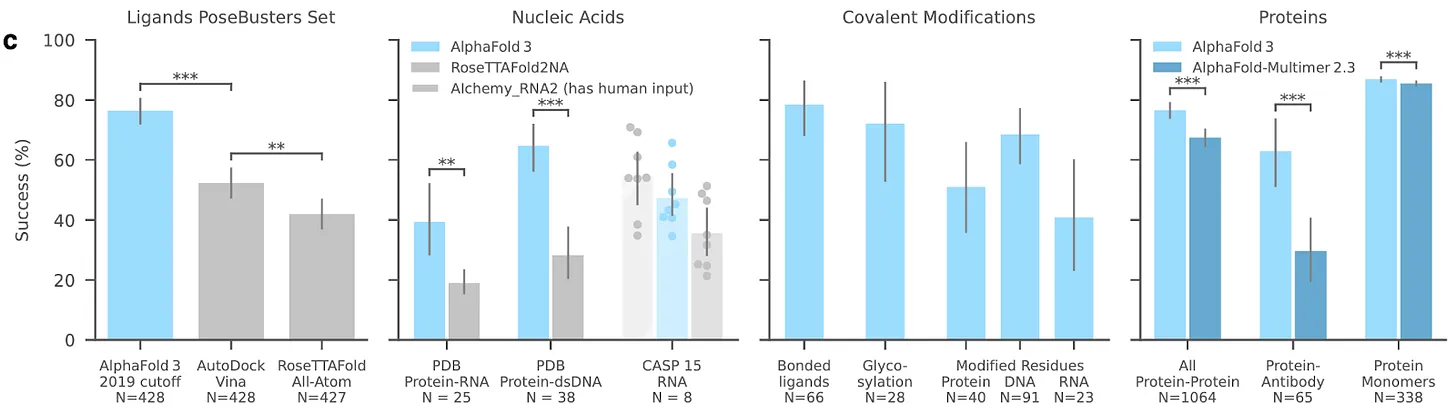
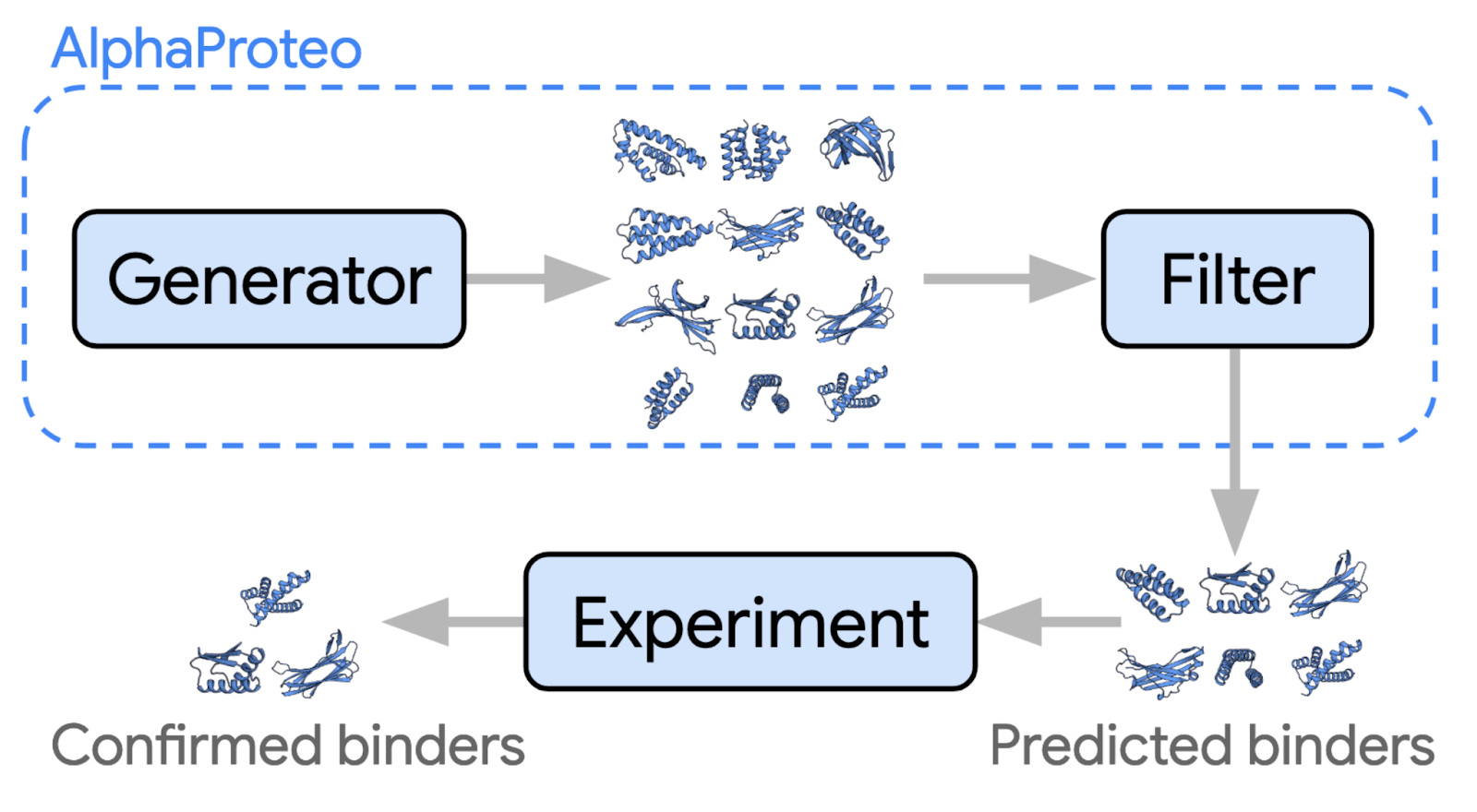
The new model even beats out certain specialist models. For example, it outperforms the Baker Lab’s highly capable RoseTTAFoldNA on protein-DNA complexes. There are signs that the work is already being put to use, via AlphaProteo, which can generate novel, high-strength protein binders.
Google DeepMind is no longer uncontested. AlphaFold 1 and 2 swept all before them when they first launched. These models were launched 2 years apart, and no team was able to catch up in the intervening period. But today there are already multiple convincing replication efforts for AlphaFold 3 underway. These include Baidu’s HelixFold3 and Chai-1’s molecular structure prediction model. Unlike AlphaFold 3, their code is open sourced.
EvolutionaryScale, which spun out of Meta, launched this summer with a $142M seed round. The team was known for creating the highly capable ESM family. These models, trained on vast quantities of protein sequence data, learn patterns of amino acid co-occurrence that reflect evolutionary constraints. By learning the general principles of protein evolution, it becomes possible to make accurate predictions, even for rare variants that have yet to be observed.
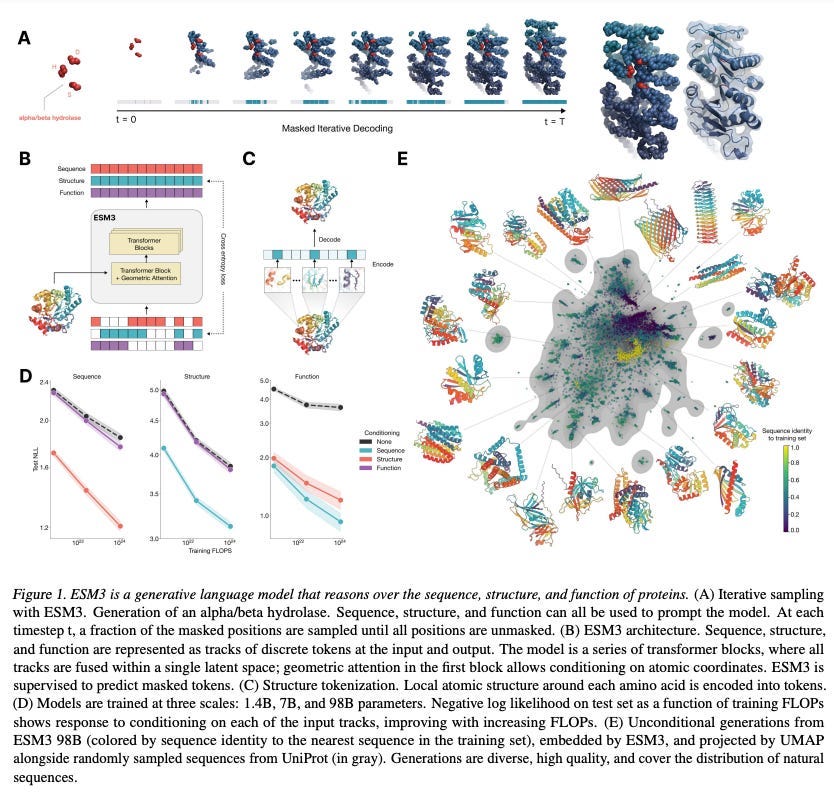
More recently, EvolutionaryScale launched ESM3, the latest iteration of their model. Unlike ESM2, which was trained solely on amino acid data, ESM3 incorporates multiscale data (e.g. protein structure information and function data), unlocking improved generative capabilities.
The team tested it at different scales, with the largest model hitting 98B parameters. While a model of this size is impressive, I was more encouraged by how little it outperformed ESM2, including the version with 650M parameters, on sequence-only tasks. This suggests specialization, rather than scale at all costs, might still have a place.
The approaches above tackle structural and evolutionary information about proteins, respectively. Our friends at Profluent created ProseLM, a method for adapting their protein language models to combine evolutionary and structural information. In practice, this means integrating the inferred natural rules for what makes for a good protein sequence, with the structure-inspired design guide for specific 3D shape and function.
Gene editing
On the subject of Profluent, the team has enjoyed success beyond the world of small molecules. CRISPR editors allow for the targeted modification of disease-causing genes, enabling personalized treatments based on an individual's genetic profile.
CRISPRs are a particularly exciting tool for the treatment of genetic disorders, such as cystic fibrosis, sickle cell anemia, and Huntington's disease. The world’s first CRISPR therapeutic - for sickle cell anemia - received regulatory approval in the UK and US at the end of last year.
However, the R&D process for CRISPR editors is expensive. As well as the lab space, equipment, and staff - teams have to navigate an arcane web of patents that have already triggered years of legal disputes. This usually involves paying out license fees upfront. Considering the high failure rate for medical R&D, this just isn’t possible for most teams.
Profluent used their proprietary protein language models, trained on a curated dataset of over 1M CRISPR operons (gene editing systems), mined from 26 terabases of assembled microbial genomes and metagenomes, to generate thousands of diverse CRISPR proteins. Not only did they generate 4.8x the number of protein clusters across CRISPR-Cas families that are found in nature, these included some that are over 400 mutations away from any known natural protein. A number of the gene editors’ performance was comparable to SpCas9, the prototypical CRISPR gene editor.
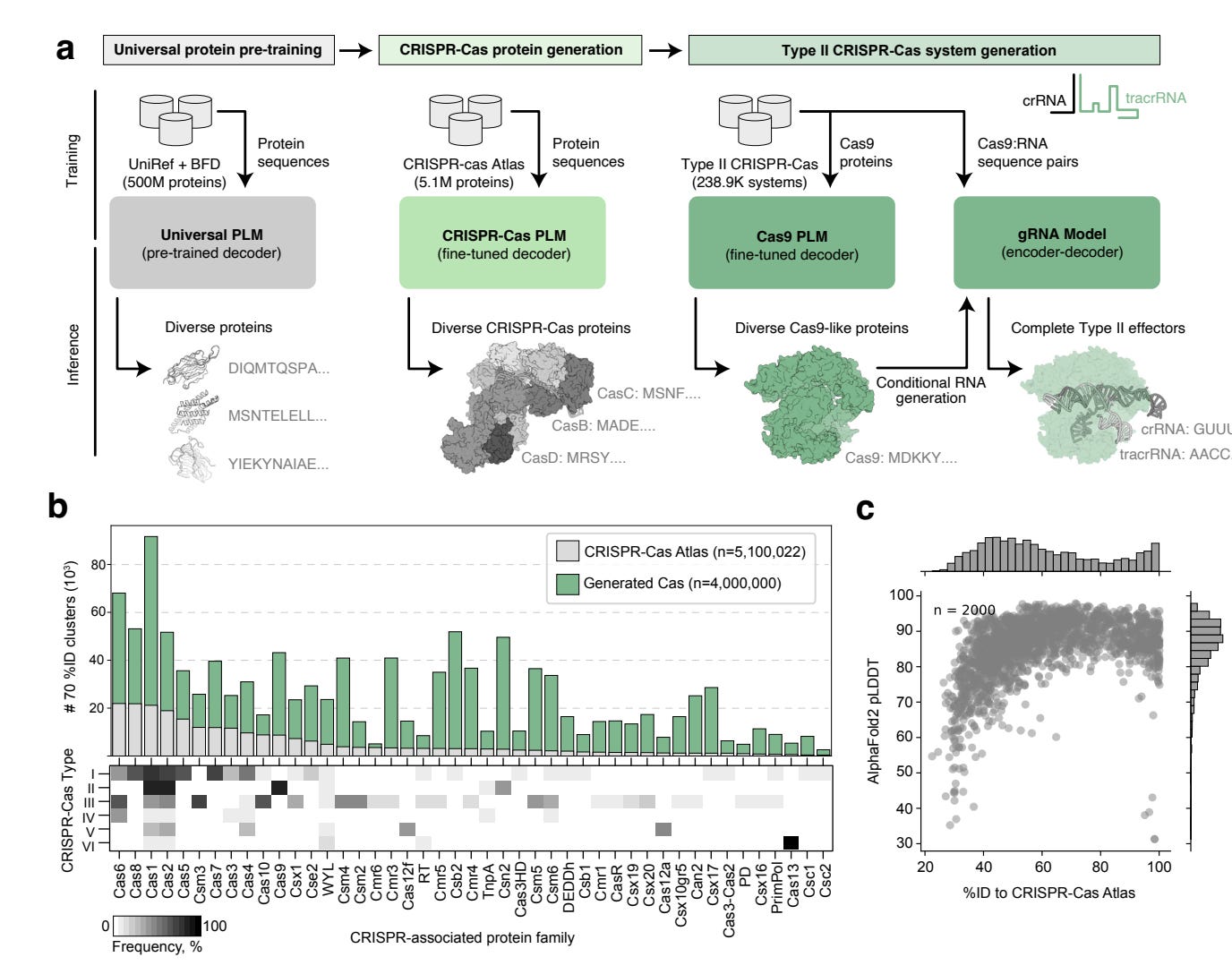
OpenCRISPR-1, Profluent’s top hit, exhibited up to 95% editing efficiency across cell types, with a low off-target rate, and is compatible with base editing. This latter point is critical - it means the editor has the precision required to change a single DNA base pair without fully cutting the DNA double helix. This significantly reduces the possibility of unwanted insertions or deletions.
Profluent has made OpenCRISPR-1 available for free, which has driven uptake by all major pharma companies and labs. This is possibly one of the single most impactful real-world applications of LLMs in science that I am yet to see. If you want to see the full story, do check out the New York Times write-up.
Single-cell omics
Single-cell omics allows researchers to analyze the molecular profiles of individual cells rather than averaging from a population. Single-cell resolution unlocks new insights into disease mechanisms, gives us a more comprehensive understanding of how different cell types interact within complex biological systems, and helps us to identify new drug targets by getting closer to the root cause of disease.
As a field, single-cell omics has grappled with a number of challenges, such as noise and technical variability, the integration of diverse data sets, batch effects, and generalization. The ability to handle large, unlabeled, multimodal, high-dimensional datasets is perfect for the transformer architecture.
While applications of AI here are significantly less mature than something like AlphaFold, which is delivering measurable real-world impact, it’s a promising indicator of the direction of travel.
A great example of this is scGPT, a foundation model for single-cell multi-omics data produced by a team at the University of Toronto. The group leveraged large-scale pretraining on over 33M cells to create a unified framework that demonstrates strong performance across cell type annotation, perturbation response prediction, batch integration, and gene regulatory network inference.
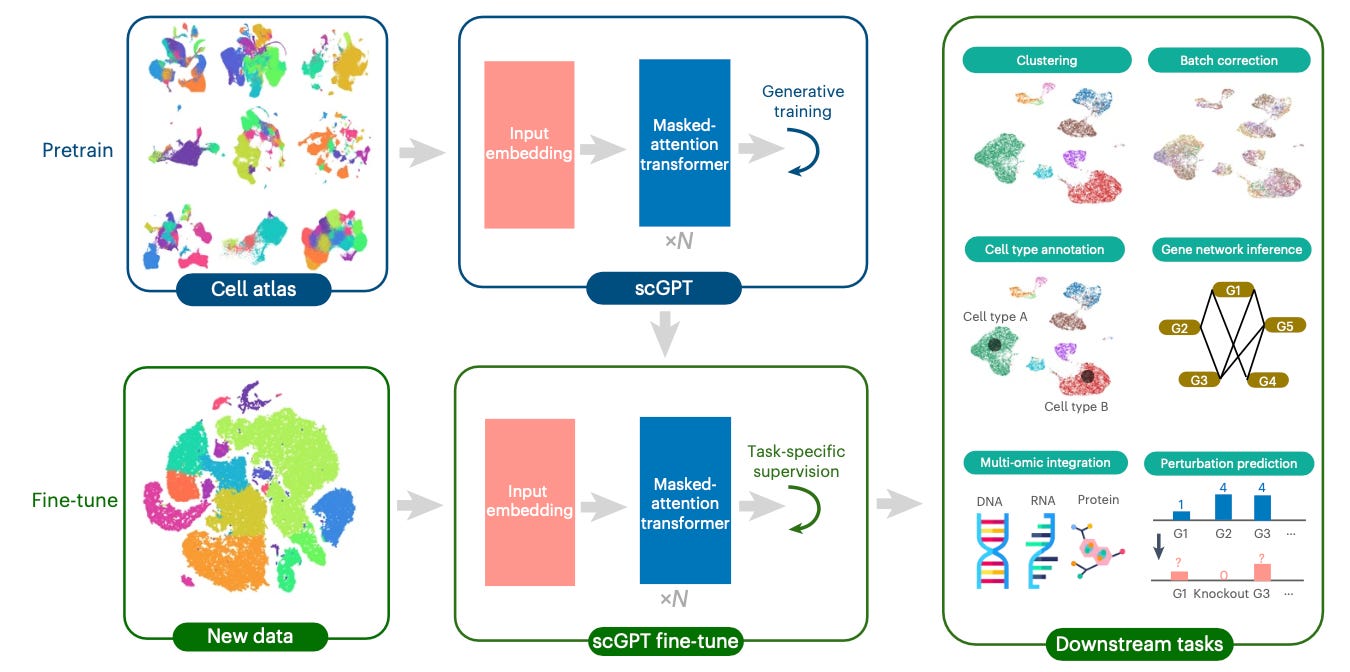
The model also showed promise at integrating multi-omic data, RNA-seq, ATAC-seq, and protein abundance measurements. These collectively provide insight into gene expression patterns and regulatory activity and protein levels - allowing for a more holistic analysis of cellular processes.
scGPT is a good example of a piece of work that spans multiple levels. It automates a bunch of low level tasks in computational biology, such as normalizing and integrating data from different experimental batches and clustering cells based on their expression levels. It tackles mid-level ones, like annotating cell types in complex tissues.
At the same time, it has clear higher-level potential, including generating new hypotheses about gene function and cellular behavior. Meanwhile, its learned embeddings and attention patterns potentially reveal previously unknown relationships between genes and cellular processes.
Another piece of work in this domain is Geneformer, produced by the Broad Institute and a range of collaborators. Geneformer was trained on 30M single-cell transcriptomes to understand network dynamics and predict gene behavior in a range of contexts, including disease modeling. Thanks to transfer learning, it allows for predictions in gene regulatory networks, with relatively limited data, which is especially significant for the study of both rare diseases and conditions that are hard to sample.
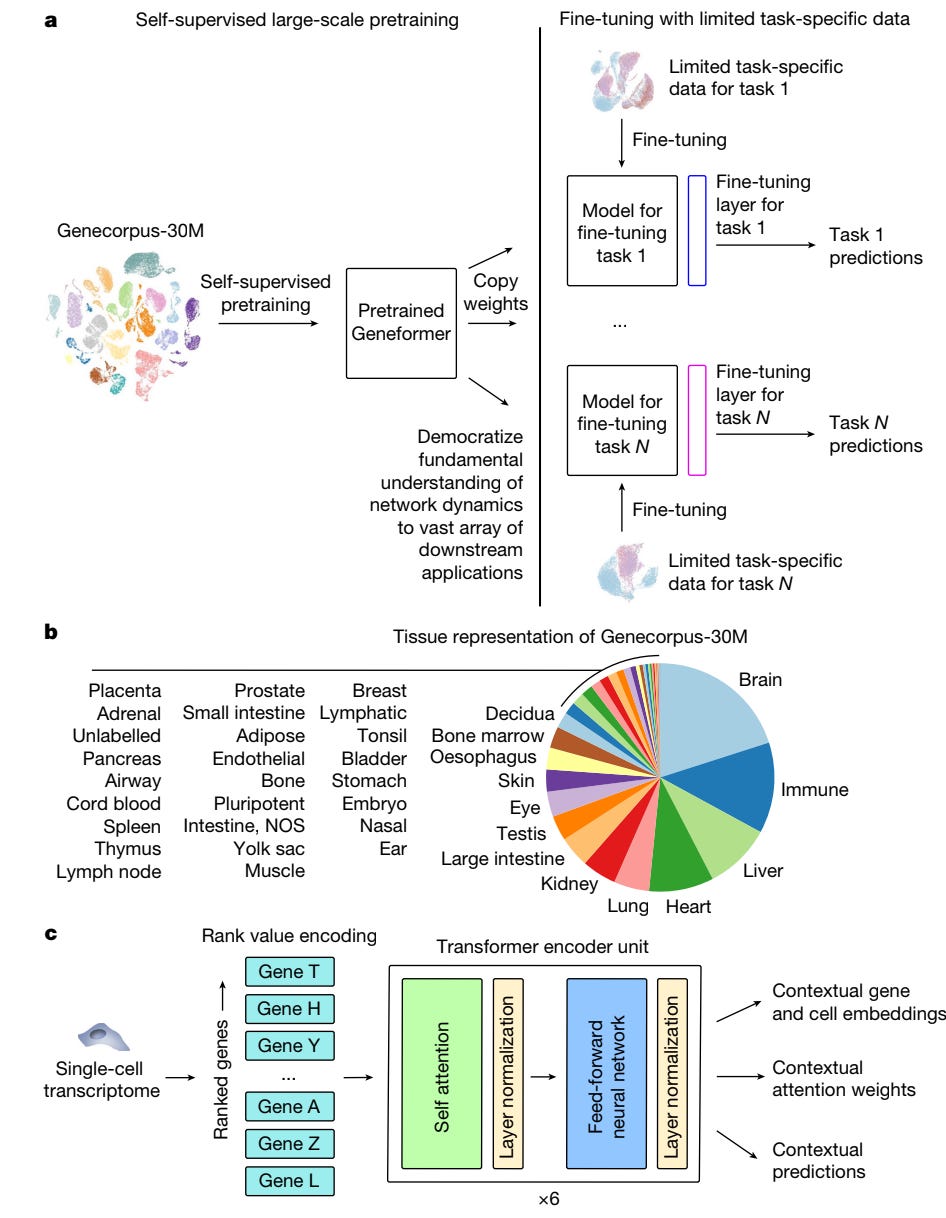
It also helps with certain higher-level tasks, such as predicting which genes in disease networks should be targeted for treatment, as well as running in silico experiments (e.g. gene deletions) to predict how modifications might shift disease states. This can help with the prioritization of candidate treatments.
Ways ahead
If we’re making healthy progress on lower to mid-level tasks, what will unlock gains on higher-level ones?
Firstly, we need to put the bio back into TechBio. While aspects of biology can resemble the types of search-problem that we see elsewhere in technology, it’s not nearly as conducive to brute-forcing.
Understanding the biology of a specific disease is crucial for modeling it effectively. Many complex diseases require a multi-omics approach and the relevant omics layers differ. Individual variants of cancer, for example, are easier to segment when one has access to genomics, transcriptomics, and epigenomics. Whereas, in other settings proteomics may be more informative. There’s no guarantee that building a huge single cell-omics dataset and bombarding it with compute will enable us to completely model a disease in silico.
To make things even more complicated, we often don’t have clean ground truth data to work with. In most image analysis, an picture of a car or a house is usually unambiguous to its human observer. However, when pathologists look at a scan, there's not always agreement on what cancer they’re looking at. This isn’t because they’re bad pathologists, it’s because nature is rarely black and white. This isn’t a reason to believe the world is unknowable or scale is impossible, it just underlines the importance of epistemic humility.
Secondly, a reset in economics. Many TechBio companies had the (mis)fortune of beginning to scale during a boom in venture funding. While easy access to capital is usually a good thing, the best entrepreneurs accompany it with iron discipline. In the pursuit of ‘one model to rule them all’, companies have invested hundreds of millions of dollars in their platform and underinvested in their pipeline. Platforms also come with immense compute demands. BioHive-2, Recursion’s NVIDIA-powered supercomputer, was the 35th biggest supercomputer in the world at the time of its completion.
Unfortunately, biology can remain hard longer than you can remain solvent. To obtain short-term revenue, companies have increasingly explored partnerships with large pharma companies. While this brings in cash, this approach can store up problems.
The more a company becomes dependent on pharma partnerships to keep the lights on, the more resources will be drawn away from the internal pipeline, which is the real prize. As I’ve written about before, the most exciting AI companies take a ‘full stack’ approach - owning both the platform and the assets it creates. Acting as a subcontractor to pharma is a considerably less lucrative business.
The solution to this lies in focus and specialization, in the first instance. Not only is it likelier to succeed, it’s also a lot cheaper.
Finally, evolutions in architecture and data. While transformers have significantly accelerated AI-driven advancements in biology, they are primarily designed for sequential data. Given the hierarchical nature of many biological systems, there's a risk that these models may overlook certain biological subtleties.
Both quantity and quality of data is critical. If we jump back to AlphaFold 3, part of its success comes from essentially swapping out architectural subtlety in favor of raw scale. Our friend Charlie Harris, a PhD student at Cambridge, dives into this in more detail in his analysis. In his view, much of the innovation lies in the sophistication of the team’s data engineering platform.
Even small amounts of high-quality data can make a significant difference. For example, Valence Labs found that introducing a small amount of Recursion’s proprietary phenomics data into the training of MolGPS, their foundation model for molecular property prediction, led to a performance increase comparable to a 50x increase in model size.
The other consideration here is that much of the data we work with is static - such as one-time measurements of gene expression or isolated snapshots of medical images - and often generated in controlled lab environments, like cell lines. While current approaches have been effective enough to drive progress, there's still work to be done to better capture and model the dynamic nature of biological systems.
Finally, unlike the human language domain where both the inputs and outputs to a generative model are perfectly observable and understandable to humans, this is not the case in biological systems. So much can (and has!) to happen for a given amino acid sequence to give rise to a protein that exerts its biological function in a living system. It is truly a miracle that generative models can - to some large extent - skip over all of this…for now.
Closing thoughts
This only captures some of the great work we’ve seen in the past couple of years. With a number of teams making impressive headway on all three of the above, I remain unashamedly optimistic about this space and where it’s headed. If you’re working on an idea at the intersection of AI and biology, don’t hesitate to get in touch, no matter where you are on your journey. It’s never too early!
Need to dig in. Q: How are you creating the voice over? Is that a new substack feature I’ve missed?