



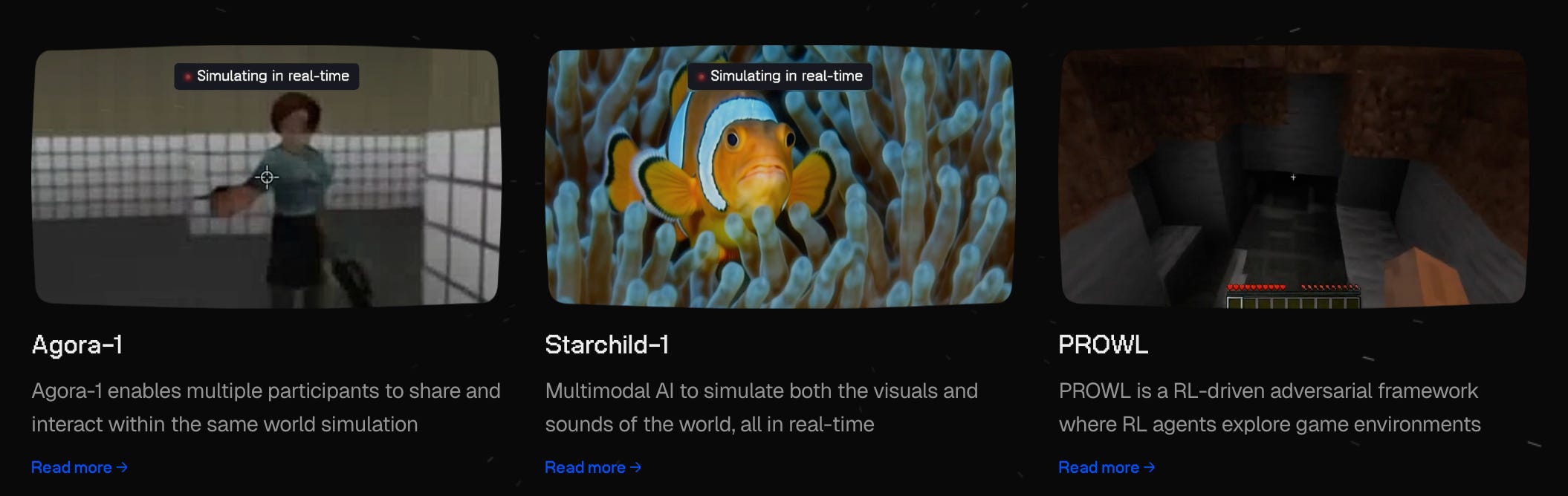
This week, Odyssey released two new world models. Starchild-1, billed by the team as the first multimodal world model, learns to generate synchronized audio and video in real time, responding continuously to streaming user input. Agora-1, released alongside it, is the team’s first multi-agent world model: up to four people share the same simulated environment as it is being generated, frame by frame.
From clip-generators to simulators
For most of the last three years, generative video has meant clip-makers: models that take a prompt and render a fixed-length, fixed-trajectory output video. Veo, Sora, Kling, and their successors have made the visual fidelity of generated video remarkable. They are also fundamentally offline systems. Once generation begins, the future of the clip is locked.
World models are a different flavor of system. First, they predict the next state of an environment given the past, conditioned on what a participant - such as a person, an agent, a robot - does next. Second, they accept streaming input mid-rollout, and the world responds. Third, they hold a persistent, manipulable state, which makes the model a simulator rather than a render.
So what’s changed more recently? Causal video distillation matured (CausVid, Self-Forcing), and bidirectional joint audio-visual foundation models arrived (Ovi, Veo 3). Odyssey has been heads-down expanding these threads into something interactive.
Two new frontier models
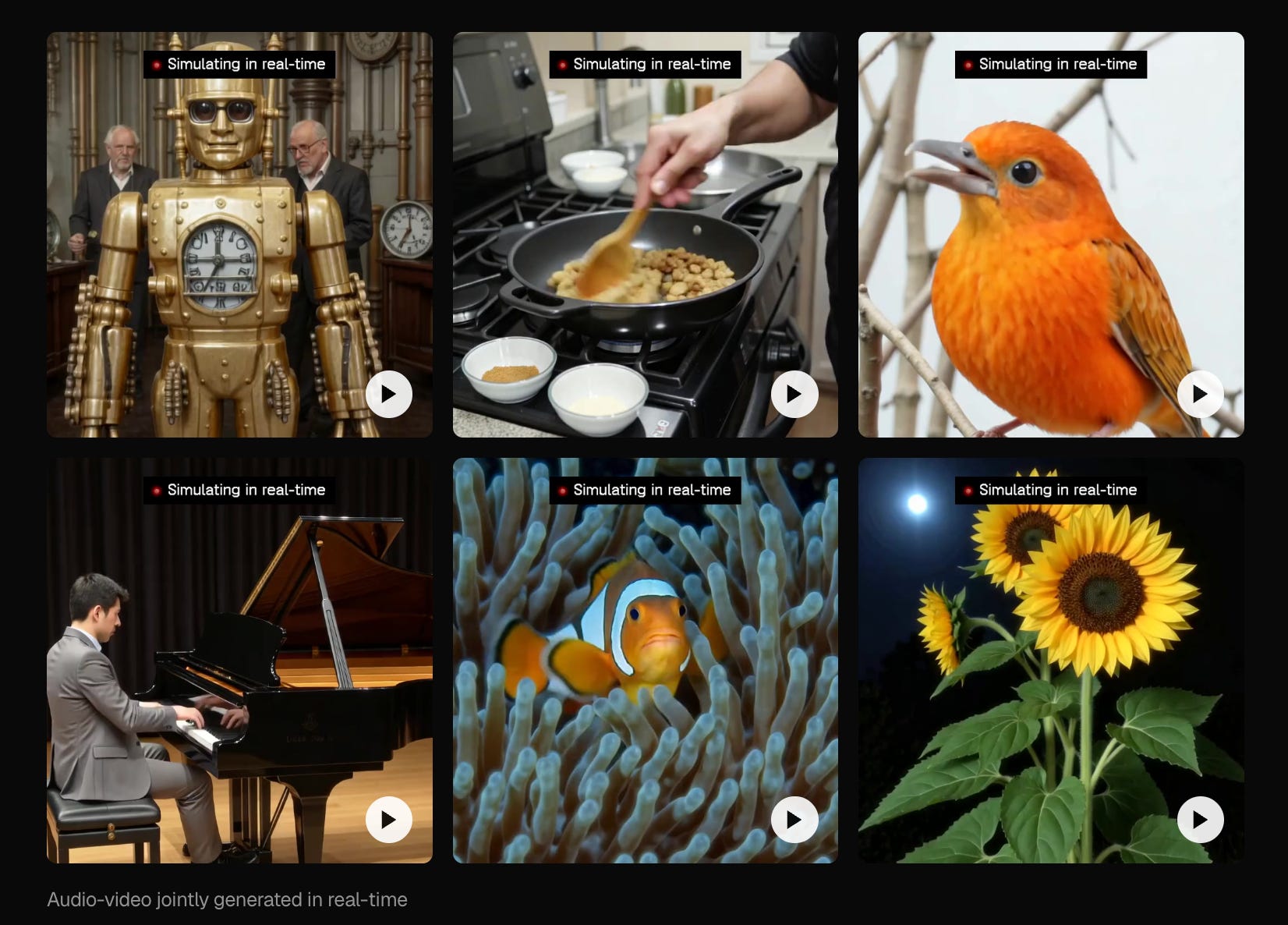
Starchild-1 jointly generates audio and video autoregressively at up to 24 fps, while continuously responding to streaming text, speech, or action input. Odyssey frames the case for sound through Aquinas: “nothing is in the intellect that was not first in the senses”. Pretending the world is silent leaves a large amount of signal - physics, dynamics, intent, emotion - out of the model. Audio and video also evolve at very different temporal resolutions, and small errors in either modality compound during long-horizon rollout.
Starchild-1’s answer is a causal distillation pipeline that adapts Ovi, a bidirectional audio-video foundation model, into a real-time autoregressive one, plus an asynchronous KV-cache architecture that lets the two modalities run on their own clocks without losing synchronization. A single model supports four interaction regimes: interactive world exploration, scripted dialogue control, conversational interaction, and narrator-style companionship. The team is candid about what’s left: scene and acoustic identity still drift over long horizons, and quantitative benchmarks for interactive causal audio-video generation don’t yet exist.
Agora-1 matches up to four players into a shared deathmatch - built on GoldenEye, a game many on the Odyssey team grew up playing (as did I) - and every frame each player sees is generated by Agora-1 while the model maintains a shared world state across all participants.
Prior multi-agent work has tried three paths. Multiverse concatenated player views into a single “split-screen” world. Solaris stacked agents along the sequence dimension of one autoregressive transformer - more robust, but context grows with the number of players, so the approach doesn’t scale linearly. MultiGen maintains an explicit shared world state but doesn’t separate simulation from rendering. Agora-1 decouples the two and learns each as a separate function. One model evolves a shared, manipulable world state from player actions; a second renders consistent views of that state from independent viewpoints. The closest analogue is a modern game engine, only with both halves of the engine learned from data rather than hand-authored.

Learning through discovery
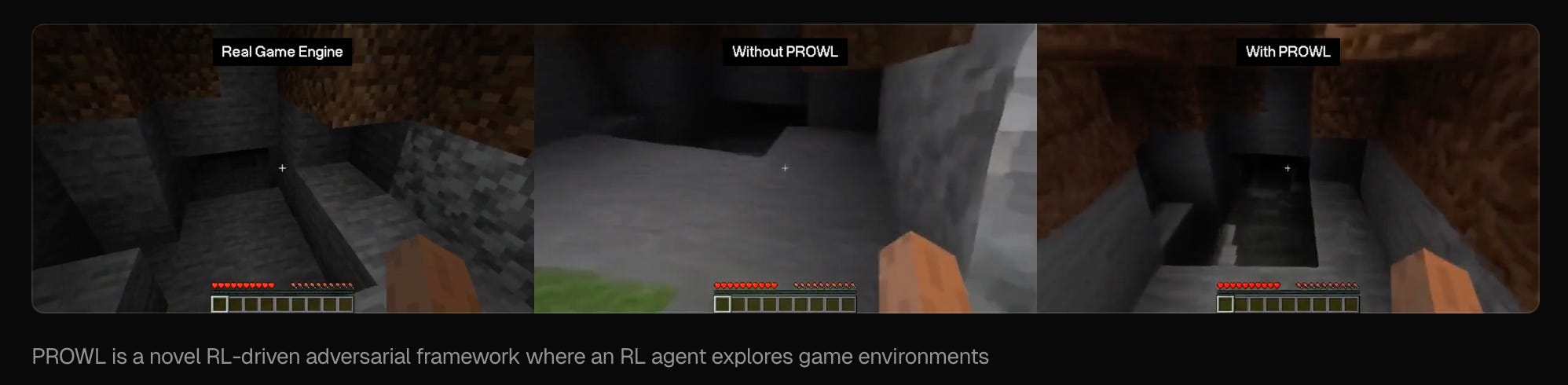
PROWL, released last week, gives world models a way to find their own failure modes and generate training data from them. None of these are products. They are the substrate for a class of interactive system that does not yet exist at scale: games that are generated rather than authored, robots that train in shared synthetic environments before they touch the real world, and foundation agents that grow up inside open-ended simulated worlds rather than on static datasets.
Learn more at RAAIS 2026!
Jeff Hawke, Odyssey’s co-founder and CTO, will go deep on this work at RAAIS 2026 in London on June 12.
Agora-1 can be played at agora.odyssey.ml. The Starchild-1 preview and technical report are live. Odyssey-2 is available via API at developer.odyssey.ml.
The bet behind world models is that the next leap in machine intelligence comes from interacting with a world, not from reading about one. Today, that world has sound and room for more than one.
Announcing Jeff Hawke (Odyssey) at RAAIS 2026

The Research and Applied AI Summit (RAAIS) is a community for entrepreneurs and researchers who accelerate the science and applications of AI technology. In the run up to our 10th annual event on June 12th 2026 in London, we’re running a series of speaker profiles to shed more light on what you can expect to learn on the day!