

Beyond hill climbing: the path to superhuman scientific discovery
With Roberta Raileanu, Senior Staff Research Scientist and Open-Endedness Team Lead at Google DeepMind, at RAAIS 2026.


The most capable AI research agents can already nudge the state of the art. Give one an open problem, like optimizing a GPU kernel or fine-tuning a language model, and it will propose a hypothesis, run the experiment, read the result, and try again. What it still does not reliably do is make a conceptual leap. Over long horizons, these systems plateau exactly where human researchers keep climbing.
At this year’s RAAIS, Roberta Raileanu set out why that ceiling exists and what it would take to lift it. Raileanu leads the open-endedness team at Google DeepMind and was previously at Meta. Her talk laid out a recipe for superhuman scientific discovery: a general system that makes groundbreaking discoveries across domains faster than people can. Three ingredients hold it together, but underneath all three sits one problem. We are good at searching for anything we can measure. We do not yet know how to measure what makes a discovery good.
The plateau before the breakthrough
The past two years delivered a real proof of concept. In 2024, Sakana AI wired LLM agents into a loop that generates a hypothesis, implements it, runs an experiment, and iterates, producing its first machine-written papers. The bar has risen since: a fully AI-generated paper has passed peer review at a workshop attached to a top machine learning conference, and a wave of startups now aims to automate research outright.
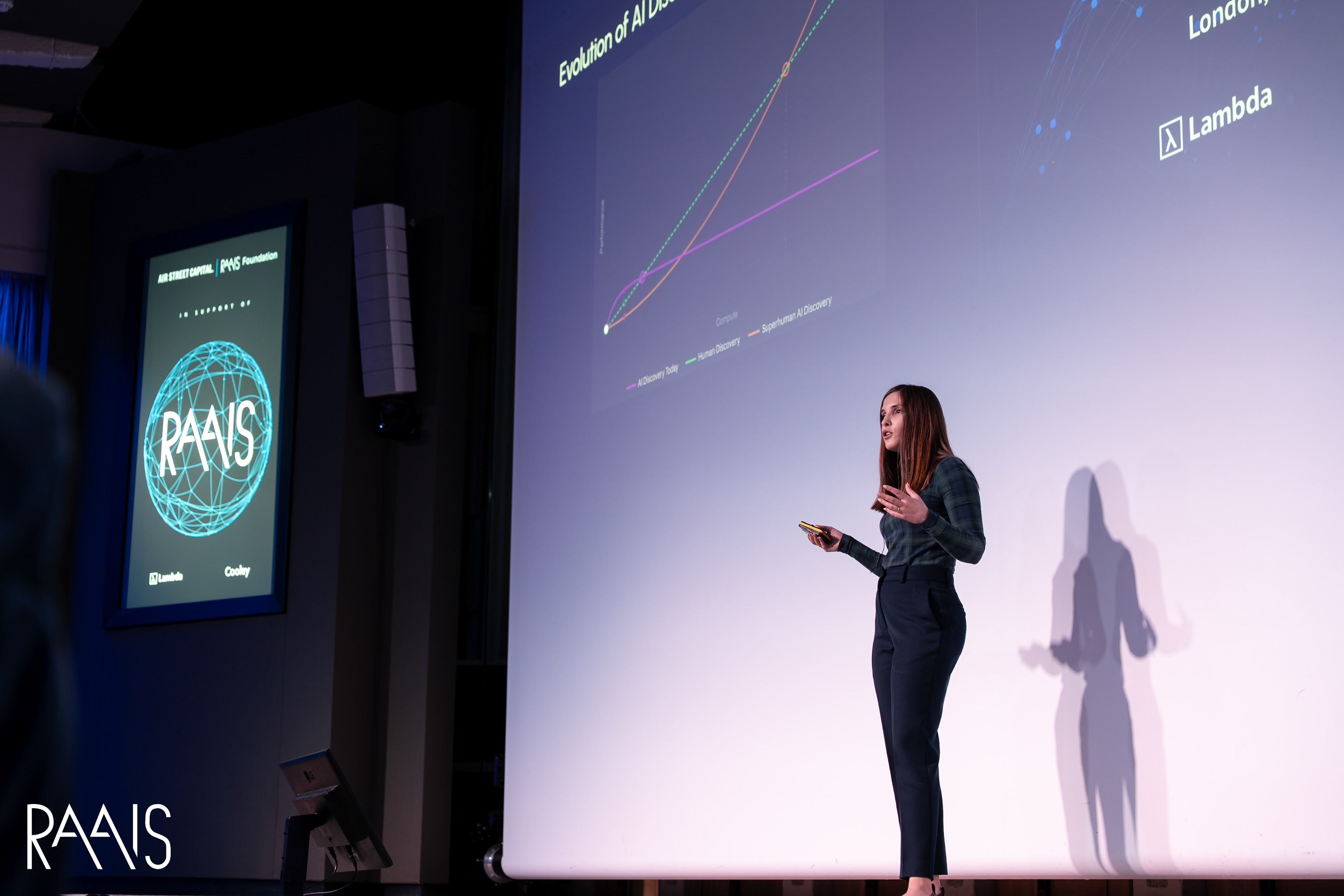
Proof of concept is not parity, however. Put the best agents head to head with human experts on the same open problems and the agents improve early, then stall. They are good at variations and combinations of known methods, and weak at what defines real research: exploring unfamiliar paths and making the conceptual leaps that change a field. Scale up compute and time and the human line keeps rising while the model line flattens.
The reason to think the ceiling can move is breadth. These models train on a far wider cross-domain corpus than any scientist can absorb, and can search for connections across more fields than any specialist holds in working memory.

The lesson of Move 37
Raileanu’s first ingredient is to treat discovery as a reinforcement learning problem. An agent acts in an environment, observes what happens, and learns from the feedback, which is not far from how a scientist forms an idea, tests it, and revises. The appeal is specific: as long as you can measure progress with a reward, the agent is free to find any solution that earns it, including one no human would think to try.
The proof is a decade old. When DeepMind’s AlphaGo played Lee Sedol, its move 37 was so counterintuitive that no human would have played it, and it won the game. But Go is a closed world with a clean reward: a move wins or it does not. Move 37 shows what optimization can do once the objective is given. In science the objective is not given. Deciding what counts as progress on an open question is the actual work, and it is the part no reward function hands you.
To study this inside AI research itself, her team built MLGym, a sandbox where an LLM agent runs shell commands, edits files, and runs experiments across tasks from language modeling to game theory. Even a year ago, simple setups could self-improve against a benchmark, but only by tuning hyperparameters and swapping architectures, not by inventing a method a human expert would adopt. That gap, between optimization and originality, is the rest of the talk.

Why greatness cannot be planned
Most breakthroughs, Raileanu argued, are not solutions to known problems. They involve finding the right problem, and “innovation is rarely this linear process from A to B.” Try to build a personal computer in the 1800s and you would not get there by scaling up the abacus; you would need the vacuum tube, which was invented to amplify radio signals.
She took the frame from Kenneth Stanley and Joel Lehman’s “Why Greatness Cannot Be Planned,” and put its claim on the screen: “No prerequisite to any major invention was invented with that invention in mind.” Optimize too narrowly for an objective and you skip the stepping stones that lead to it. Machine learning has won by hill climbing toward benchmarks, and that has carried the field far. But a hill climber only ever reaches the top of the hill it started on.
The fix is to widen the search. Borrowing from evolutionary methods, you hold a population of candidate solutions, mutate them, and select which to keep. The usual fitness function rewards performance alone. Raileanu’s argument is to score for what scientists actually value too: novelty, diversity, interestingness. This is where the signal problem surfaces in the open, because none of those is easy to measure. Her stopgap is to let an LLM judge what a person would find interesting, which at least keeps ideas that are not useful yet but might combine into something later.
Her team’s Rainbow Teaming did this for AI safety, generating diverse jailbreak prompts across a grid of risk categories and attack styles, then reusing what worked in one cell to seed another. Train on the result and the model gets measurably harder to break. The same machinery, she suggested, should carry over to ideas and methods, where a solution built for one field can matter in a completely different one.

Optimizing discovery itself
The third ingredient is to stop optimizing discovery on a single task and optimize the process of discovery itself. DeepMind has trained RL agents across huge numbers of simulated environments and watched them adapt to new ones far faster than before, in some cases faster than humans. If that transfers to research, an agent could generate its own tasks and get better at discovering, not just at one discovery.
To make that studyable, her team built DiscoBench, a framework that procedurally generates AI research tasks: more than 400 million of them, across problems like language modeling and image classification, with an agent free to target a loss function, an optimizer, or an architecture. The early signal is encouraging, with more and more diverse training tasks improving performance on held-out problems the agent has never seen.
The complementary curve
Stack the three together and you have the recipe: reinforcement learning to discover better solutions where progress can be measured, divergent search to find new problems rather than climb known ones, and meta-learning to speed up the whole process on problems no one has posed yet.
The bet underneath it is complementarity. Humans go deep in one field; a model reaches across many at once. The line worth chasing is neither the human curve nor the machine curve, but the one above both, where the two discover what neither would alone. Yet all three ingredients run back into the same wall. We have good algorithms for search once we know what to reward, and we still cannot reward novelty, a promising dead end, or taste. “The key is, do you have the right signal?” Raileanu asked. The search is the easy part. The missing piece is the signal.
The stepping-stone point is the one that stuck. It makes discovery as much a memory problem as a search one a promising dead end only proves its worth later, when something recombines with it, so the signal that would justify keeping it doesn't exist yet at the moment you have to decide. Feels like the real question under "what's a good discovery?" might be "what do you retain when you can't yet score it?"