

State of AI Report Compute Index 2026
NVIDIA challengers are moving, but still not displacing it.


Today, we’ve refreshed our State of AI Report Compute Index, in collab w/Zeta Alpha.

You’ll now find updated data for AI research papers using NVIDIA, TPUs, Apple, Huawei, AMD, ASICs, FPGAs, and AI semi startups. We’ve also expanded the infrastructure side of the index to 1 July 2026: A100, Hopper, standalone Blackwell, Grace-Blackwell, and a new demand-side view of frontier-lab contracted compute in gigawatts. Each chart can now be downloaded, shared, and embedded.
A few notes upfront: The 2026 citation figures use real counts through June 1, 2026 plus a volume-adjusted projection for the rest of the year. Year-over-year deltas are calculated against final normalized 2025 counts, not last year's mid-year 2025 projection. GPU-count charts show NVIDIA data-center GPUs by owner/operator, split into Deployed, Installing, and Announced. Grace-Hopper and Grace-Blackwell parts are counted by GPU dies, so one NVL72 rack equals 72 GPUs. Tenants are not double-counted against the operators whose clusters they use.
The breather was short
Last year’s update asked whether 2025 was the first real slowdown in open AI compute citations after six years of growth. With final normalized 2025 counts now in hand, and 2026 projected from counts through June 1, the answer looks clearer: 2025 was a pause, not a rollover.
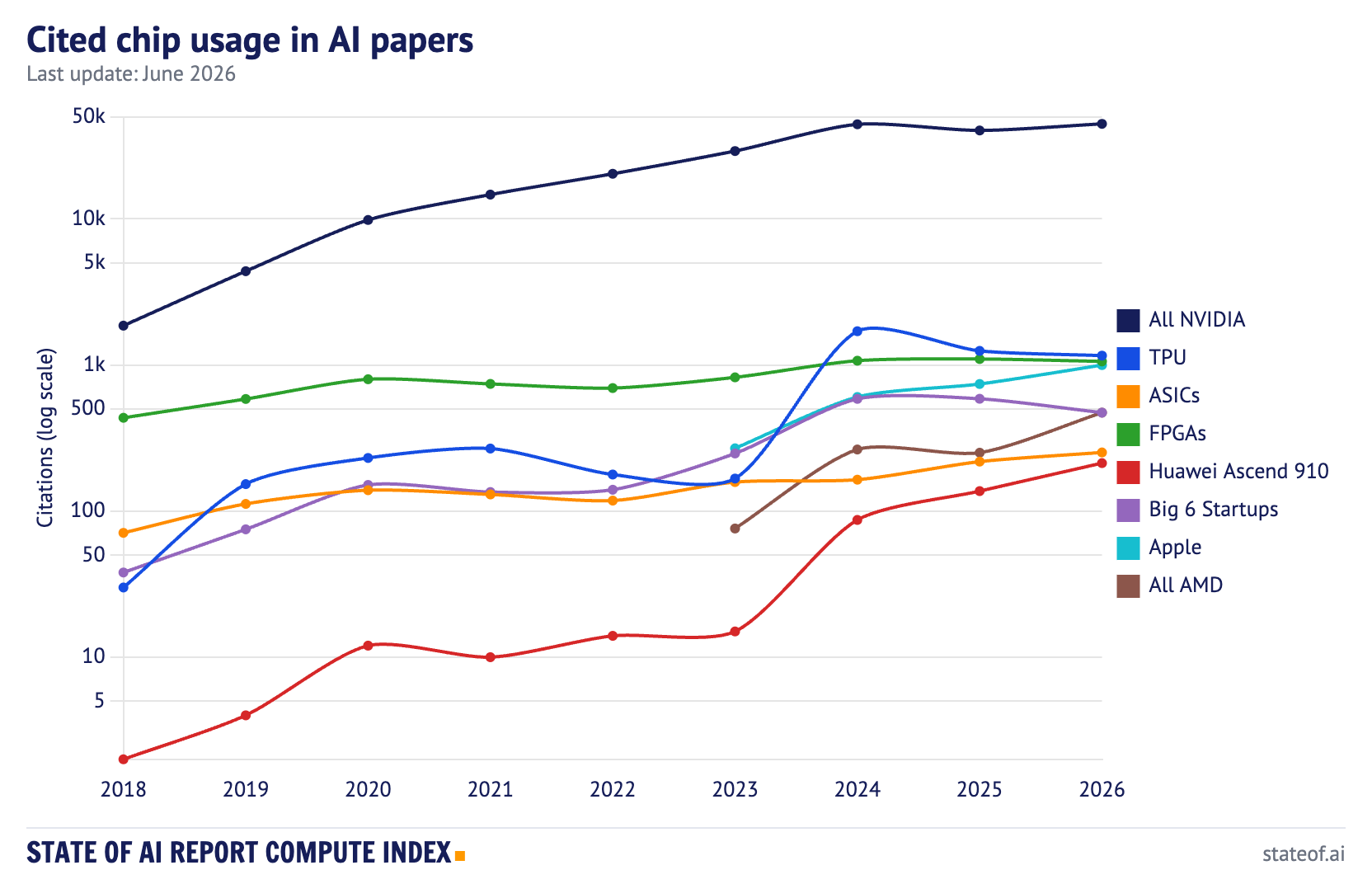
Across the tracked accelerator categories, the 2026 projection reaches 49,339 chip-citation counts, up 10.7% year-over-year and just above the 2024 peak. NVIDIA remains the default: its chips appear in 44,715 of those counts, up 10.9% year-over-year and about 91% of the tracked total.
That does not mean frontier labs have suddenly become more transparent. The largest model developers still publish less of their best work, and many papers built on managed APIs or shared cloud services do not specify the underlying silicon at all. But the open literature has not stopped reflecting hardware diffusion. The 2025 dip looks more like publication-cycle timing, API abstraction, and a quiet year between hardware waves than a collapse in compute usage.
The more interesting finding is the relative lack of upheaval. A lot of companies, labs, and governments are trying to challenge NVIDIA. In the open research literature, they are still mostly not succeeding. There is movement in AMD, Huawei, and Apple, but NVIDIA remains the language researchers use when they describe their compute.
Indeed, AMD citations nearly doubled, from 251 in 2025 to 472 in 2026. Huawei Ascend 910 rose 56%, from 137 to 213. Apple moved from 741 to 998, overtaking AMD to become the most-cited non-NVIDIA, non-Google accelerator in the open literature, which means consumer Macs now out-cite the leading silicon challenger. That likely reflects the spread of local inference and developer workflows rather than frontier training. TPUs, meanwhile, declined 7% in the open paper data, despite Google’s obvious importance to frontier AI compute. That tension is a useful reminder that paper citations are a leading indicator for some forms of adoption, but a poor measure of private, API-mediated, or closed-lab usage.
NVIDIA is still king, but the kingdom is changing shape
The NVIDIA chart now approximates their product-cycle chart.
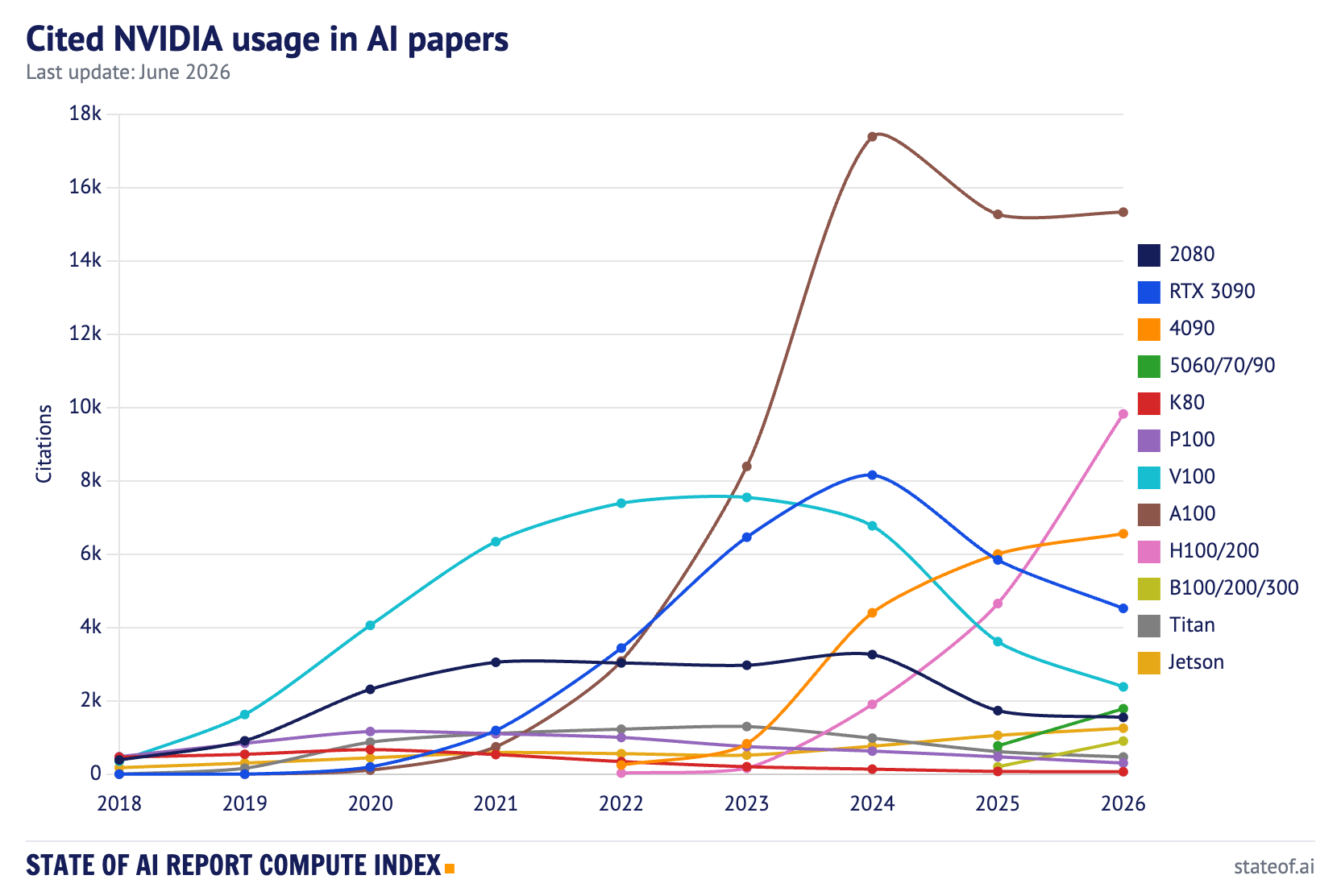
A100 citations are basically flat at 15,327, up 0.4% year-over-year. The A100 is no longer where the growth is. H100/H200 citations have more than doubled to 9,823, up 111% year-over-year, as the 2024 and 2025 Hopper build-out finally works its way into papers. Blackwell-family mentions, tracked as B100/B200/B300 in the Zeta Alpha data, are still small at 902, but are up 4.5x year-over-year.
Meanwhile the older stack continues to drain out: V100 citations are down 34%, RTX 3090 down 23%, P100 down 36%, and K80 is now barely visible. The RTX 4090 is still useful in the academic long tail, up 9% to 6,557 citations, while the new 50-series cards are appearing quickly from a small base.
Startup silicon is no longer one story
Groq is now the most-cited startup chip, up 49% to 264, and in December, NVIDIA acquired it. The fastest way to dent NVIDIA’s share turned out to be getting bought by NVIDIA. Cerebras is second at 242, up 8%. SambaNova rose to 52, Cambricon to 33, while Graphcore fell to 40 and Habana to 24.
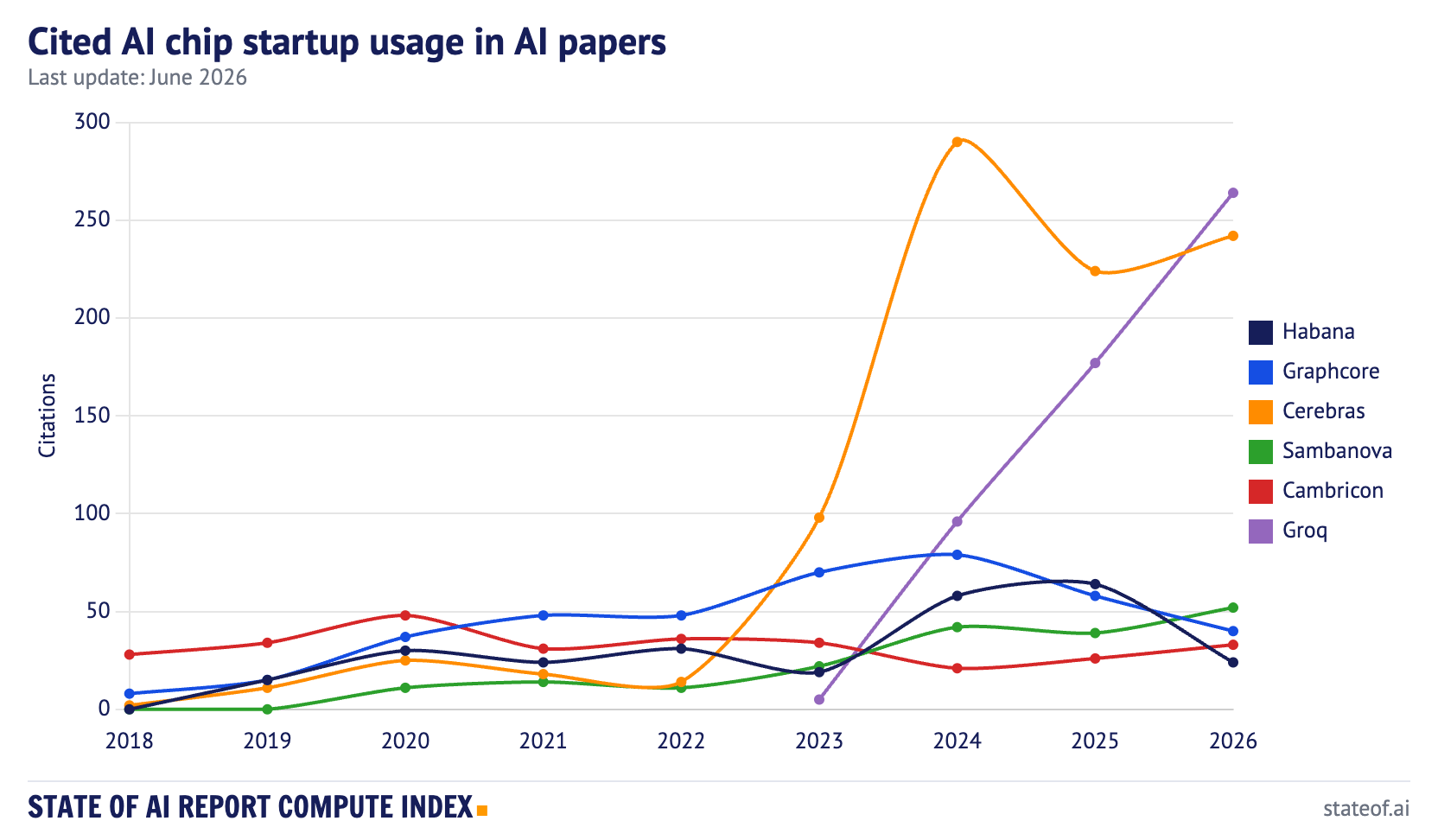
That is not yet a market-share story. Startup chip citations remain tiny next to NVIDIA, and papers using startup silicon still often include authors from the chip company itself. But it does show the category splitting into different jobs. Groq is showing up around low-latency inference, Cerebras around large-scale wafer-scale systems, and the older acquired or de-emphasized platforms are fading from view.
The right conclusion is not “startup chips are breaking CUDA.” They are not. It is that the category is specializing into niches, inference latency and wafer-scale, while NVIDIA keeps the general case.
Hopper is the installed base
The second half of the index is not a citation tracker at all. The cluster charts show how much of the AI build-out has already moved from research procurement into industrial infrastructure.
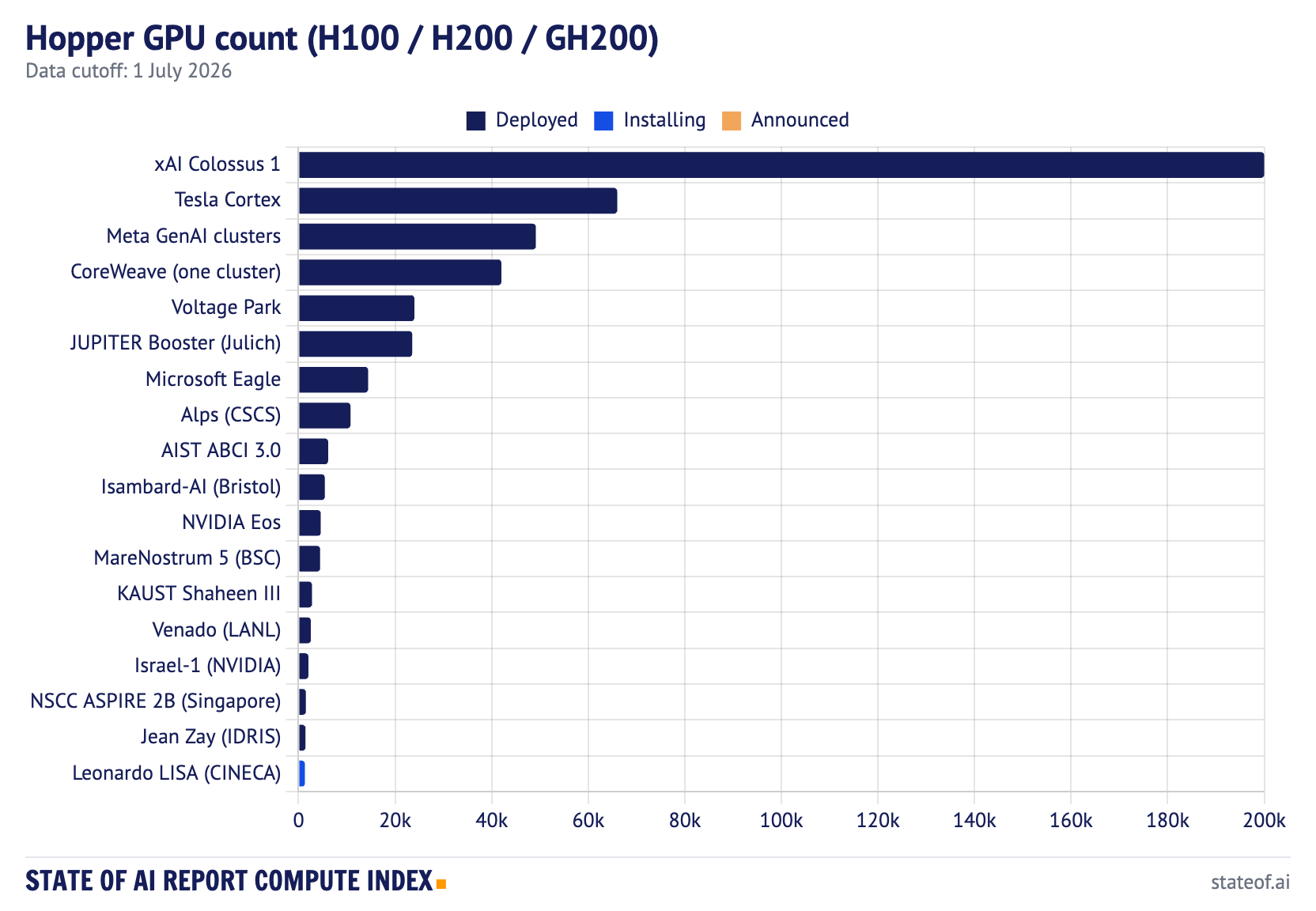
Across the tracked Hopper systems, we count 460,904 deployed H100, H200, and GH200 GPUs, plus 1,328 installing. That is more than 11x the tracked A100 total of 41,208. The A100 chart now reads like a legacy fleet chart; Hopper is the live installed base.
xAI Colossus 1 is the largest tracked Hopper deployment at 200,000 GPUs, and by itself is almost five times the entire tracked A100 set. Tesla Cortex follows at roughly 66,000 H100-equivalent GPUs, then Meta’s GenAI clusters at 49,152, a CoreWeave H200 cluster at 42,000, Voltage Park at 24,000, and Germany’s JUPITER Booster at 23,536 GH200.
There is a geopolitical point hiding in the table. National HPC systems are exact and visible, which makes them easy to count. Private fleets are estimated, harder to observe, and much larger. Europe now has serious machines in JUPITER, Alps, Isambard-AI, Leonardo, MareNostrum 5, and Jean Zay. But the largest private AI clusters are operating at a scale national supercomputing programs mostly do not match.
Blackwell is mostly pipeline
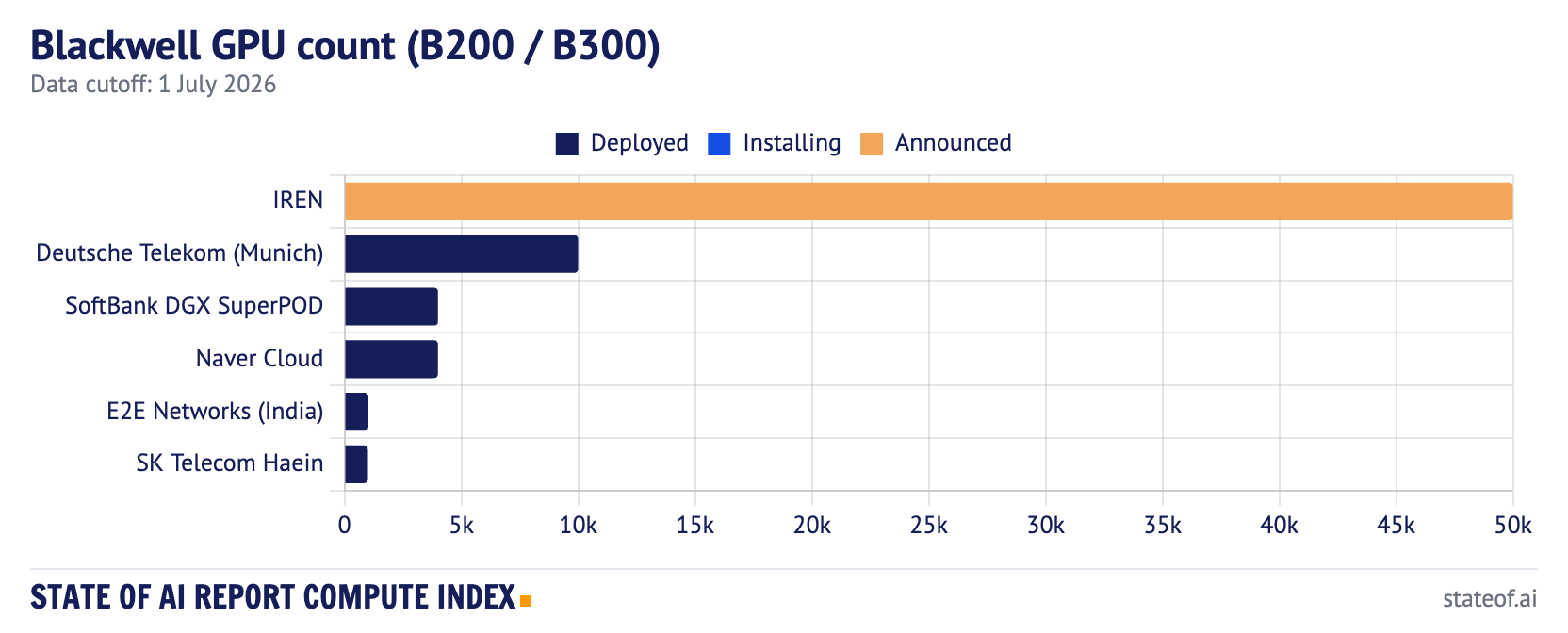
Standalone B200/B300 deployments in the index total 20,024 GPUs, led by Deutsche Telekom’s Munich Industrial AI Cloud at 10,000, then SoftBank’s DGX SuperPOD and Korea’s Naver Cloud at 4,000 each, E2E Networks in India at 1,024, and SK Telecom’s Haein cluster at around 1,000. IREN’s 50,000 B300 order sits in Announced.
Grace-Blackwell is where the real pipeline sits. The index tracks 100,128 deployed GB200/GB300 GPUs, 308,640 installing, and 1.66 million announced. In other words, just under 5% of the tracked Grace-Blackwell pipeline is deployed, and roughly 80% is still announced. The deployed number crossed 100,000 this month as the first sizable GB300 systems came online, including CoreWeave’s 8,192-GPU cluster, which posted MLPerf training results in June, and Mistral’s 13,800-GPU Bruno in France moving from installing to live. It is a small share of the pipeline, but it is the first month the deployed bar moved on the strength of Grace-Blackwell rather than Grace-Hopper.
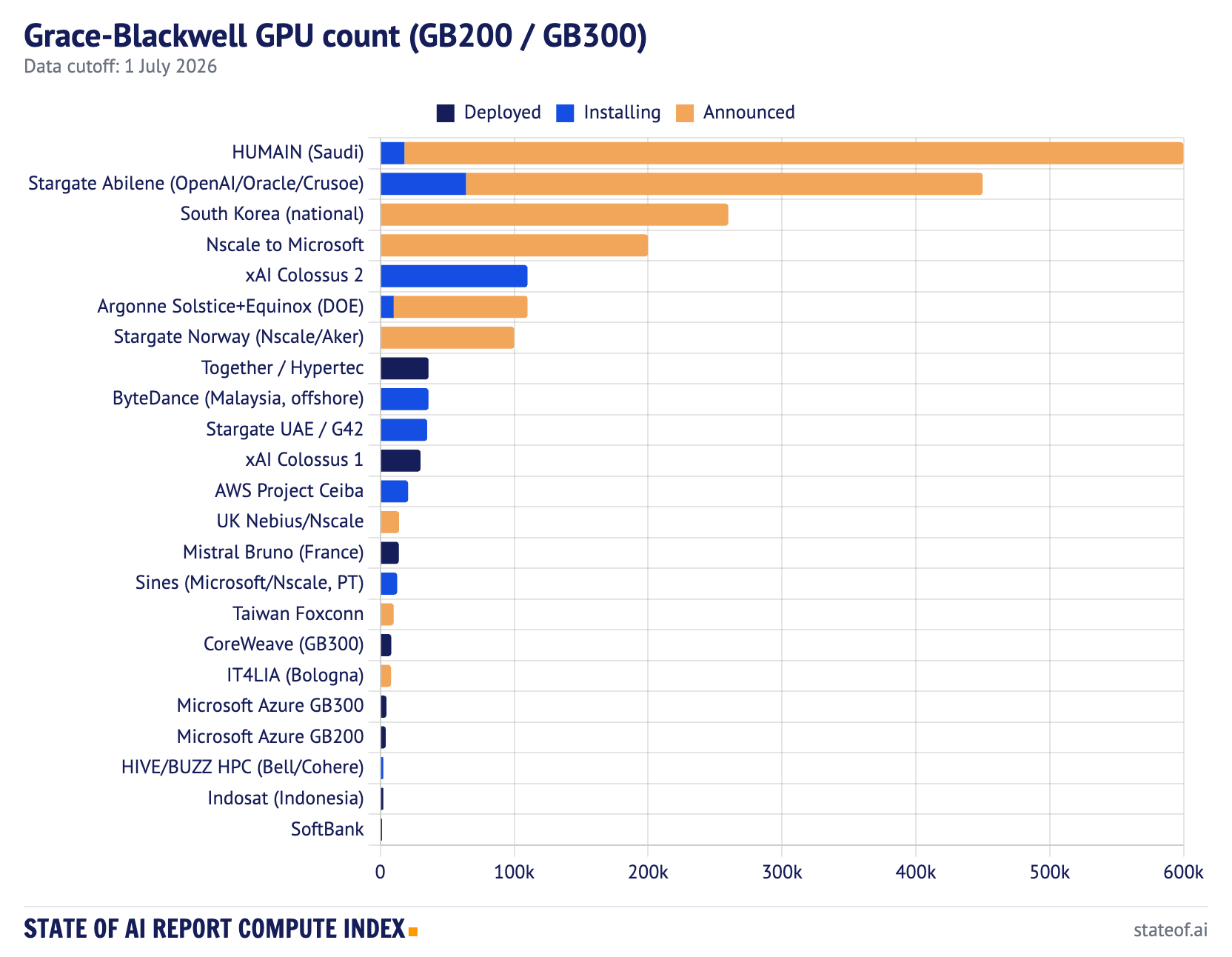
The largest announced and installing programs still look more like sovereign or hyperscale industrial projects than normal data-center procurement: HUMAIN in Saudi Arabia at up to 600,000 GB300, Stargate Abilene at a 450,000 GPU target, South Korea’s national 260,000 Blackwell program, Nscale’s 200,000 GB300 commitment to Microsoft, xAI Colossus 2 at roughly 110,000 installing, Argonne Solstice and Equinox at 110,000 combined, and Stargate Norway at 100,000 announced.
This is why “GPU count” is becoming an incomplete question. The constraint has moved outward to power, land, cooling, interconnect, permitting, debt, and offtake. A GPU order is not a cluster. A cluster is not always available capacity. And contracted capacity is not the same as a model training run.
The demand side is now measured in gigawatts
The frontier-lab contracted compute chart looks at the other side of the market: not who owns a cluster, but which labs have contracted capacity in disclosed gigawatt terms.
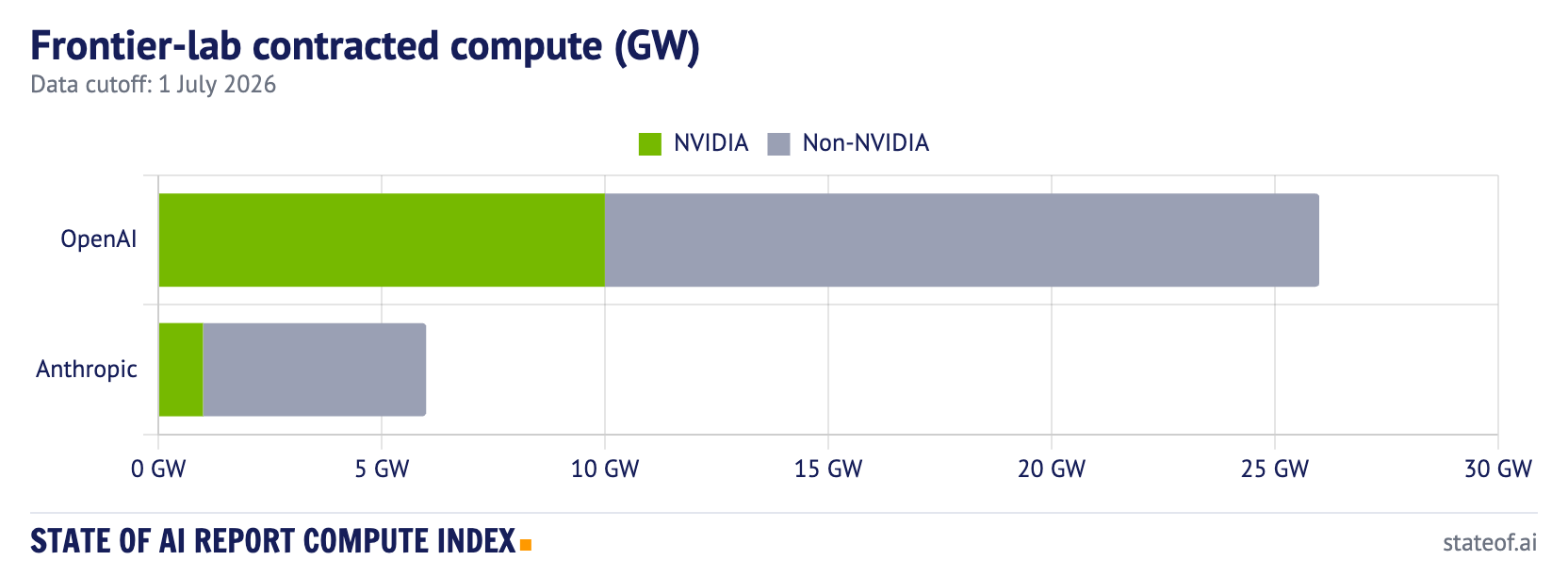
For GW-disclosed deals, OpenAI is now at 26 GW of contracted compute: 10 GW of NVIDIA systems and 16 GW of non-NVIDIA, the latter split between a 6 GW AMD MI450 commitment and 10 GW of Broadcom custom silicon. Anthropic is at 6 GW total, split between 1 GW of NVIDIA and 5 GW of non-NVIDIA capacity.
On disclosed gigawatts, then, OpenAI’s non-NVIDIA book is now larger than its NVIDIA book, and larger than Anthropic’s entire portfolio. It is worth being careful about what that does and does not say. NVIDIA is still OpenAI’s largest single-vendor commitment and its fastest path to scale; the non-NVIDIA figure is spread across AMD and a custom Broadcom part that has not yet shipped at volume. Anthropic’s non-NVIDIA number is, if anything, understated, because its AWS Trainium and Google TPU commitments are only partly disclosed in gigawatts and are therefore not fully charted.
Still, the direction is clear. Frontier labs are no longer choosing a single chip vendor. They are assembling compute portfolios: NVIDIA for the broadest software ecosystem and fastest path to scale, TPUs and Trainium for strategic supply and cost control, custom silicon for future leverage, and neoclouds or sovereign projects when hyperscaler capacity is not enough.
“CUDA is still king” remains true in the papers. But in frontier-lab procurement, the question is becoming broader: who can turn contracted gigawatts into reliable, liquid-cooled, networked, usable intelligence infrastructure?
Looking ahead
Several known unknowns will shape the next Compute Index update:
How quickly announced Grace-Blackwell projects become deployed clusters rather than press releases, now that the deployed bar has finally started to move.
Whether OpenAI’s Stargate program, HUMAIN, South Korea’s national Blackwell program, and Nscale’s Microsoft commitments hit their published timelines.
Whether AMD MI300/MI350, Huawei Ascend, TPUs, and Trainium show up more visibly in open paper metadata, or remain hidden behind closed-lab and cloud-abstraction layers.
Whether Blackwell appears in the literature in late 2026 the way Hopper appears in the 2026 data now.
Whether OpenAI’s and Anthropic’s non-NVIDIA books convert from contracted gigawatts into deployed, usable capacity, or stay on paper the way the Grace-Blackwell pipeline mostly has.
Whether national AI factories can close any of the gap with private frontier-lab infrastructure.
The headline from v7 is simple: the open literature has rebounded and NVIDIA remains the default; the challenger story is real but still small in the papers; Hopper is the installed base while Grace-Blackwell has only just begun to land; and on the demand side, even OpenAI’s disclosed book is now majority non-NVIDIA, even as most of that capacity is still a contract rather than a cluster.
See the live charts here: www.stateof.ai/compute.
A few notes
We take the view that usage of chips in AI research papers by early adopters is a leading indicator of broader industry usage, but not a complete measure of closed-lab or API-mediated compute.
Paper-citation counts are unchanged from v6. Zeta Alpha’s open-source AI paper index refreshes annually; 2026 figures are real counts through June 1, 2026 plus volume-adjusted full-year forecasts, and year-over-year comparisons use final normalized 2025 counts as the baseline. This update refreshes the infrastructure charts to July 1, 2026.
GPU-count charts use public disclosures, operator materials, EuroHPC, Top500, SemiAnalysis, The Next Platform, Data Center Dynamics, company filings, and NVIDIA materials. Large private-company figures are best-available estimates; national HPC figures are exact where published.
Announced capacity is labeled separately from deployed and installing capacity. We do not invent cloud instance counts where vendors do not disclose them.