



The State of State of AI Report


Introduction
The State of AI Report is our comprehensive round-up of the most important developments of the year in AI research, industry, safety, and politics. I started co-producing the report in 2018 with fellow investor Ian Hogarth. After he took on the important role of leading the UK Government’s AI Safety Taskforce, it was a Team Air Street production in 2023.
The report is driven by the belief that if you want to be part of the AI community, then you have to be an active contributor. Dedicated researchers and practitioners don’t usually have the time to follow breakthroughs in every discipline or use case, so our aim is to provide an opinionated analysis to serve as a practical field guide.
Looking back over the past five years, the report serves as a historical document. It shows both how the capabilities of the field have advanced at a dizzying pace, as well as the impact this has had on industry and politics.
You can find all the past reports on the State of AI Report website, but to mark five years since our first edition, we’ve gone back through 934 slides (without LLM assistance), and compiled some of the major storylines and where our predictions did (and didn’t) hit the mark.
Charting a half-decade overnight success: from transfer learning to the scaling of transformers into large language models (LLMs).
In our early reports, the research sections were dominated by reinforcement learning as DeepMind took an ax to seemingly every gaming benchmark it could find. This started with Go, then StarCraft II, then Quake II Arena Capture the Flag, followed by OpenAI entering the ring to crush Dota 2.

Having started its life in games, DeepMind didn’t stay in the simulated world alone for long. In just a few years, they’d moved from StarCraft to controlling the core of a nuclear reactor.

Nevertheless, the generative AI boom won’t have come as a surprise to loyal State of AI readers. We may not have been calling them LLMs, but the precursors to the current generation of models were starting to show impressive results as early as 2018.
Back then, what we called transfer learning was enabling models trained on one natural language processing (NLP) task to work great on other NLP tasks by virtue of learning generally useful representations.

It was soon clear that attention was indeed all you needed, and by 2020, transformers had surged from passing mention status to the MVP of the research section.

As a result, NLP was essentially ‘solved’ by 2021…

OpenAI realized you could represent your data as a sequence of tokens, so a transformer could learn it, driving impressive results in image completion.

So transformers then expanded from vision into several other domains such as audio and 3D point clouds.

It also quickly became apparent that OpenAI was putting the pedal to the model scaling metal after seeing early success with GPT-2 (“Language Models are Unsupervised Multitask Learners”, 2019), leaving the rest of the field playing catch-up with GPT-3 (“Language Models are Few-Shot Learners”, 2020):
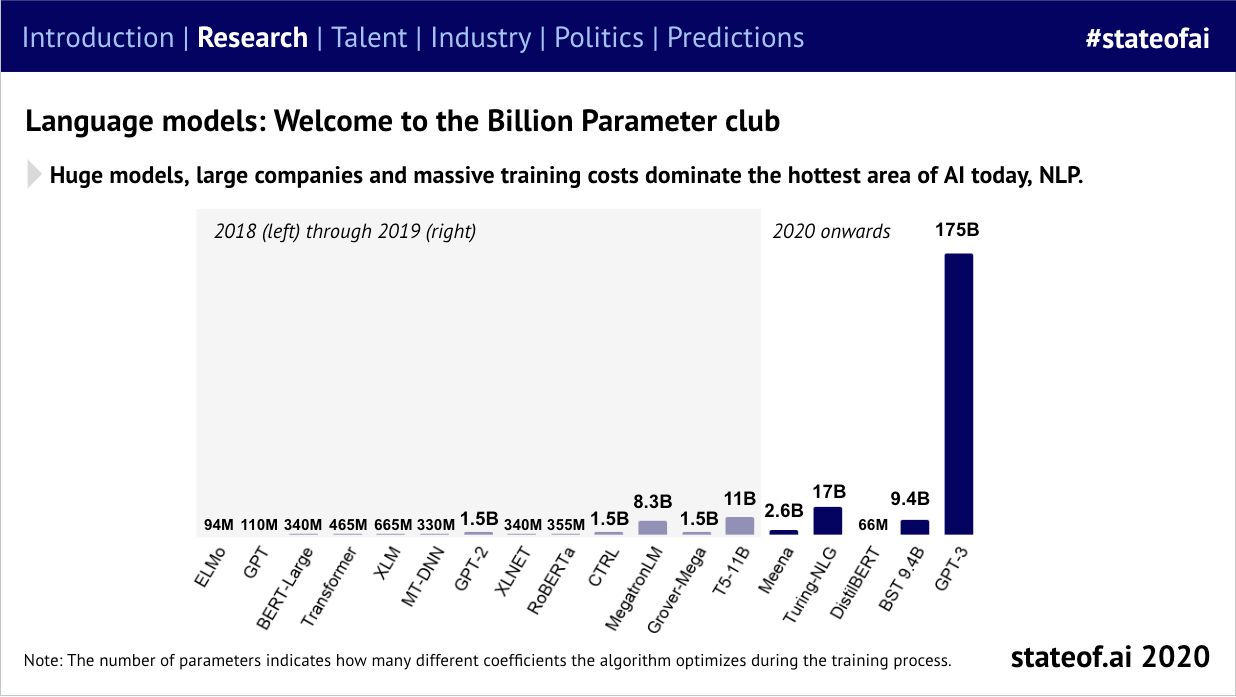
This was crucial, as we’d seen evidence of the power of scaling laws as far back as 2015:

From the first days of the report, we were tracking research showing the clear connection between compute, model size and data scale, and ultimate model performance.

This prompted concerns about model training costs running into the millions of dollars for multi-billion parameter models…
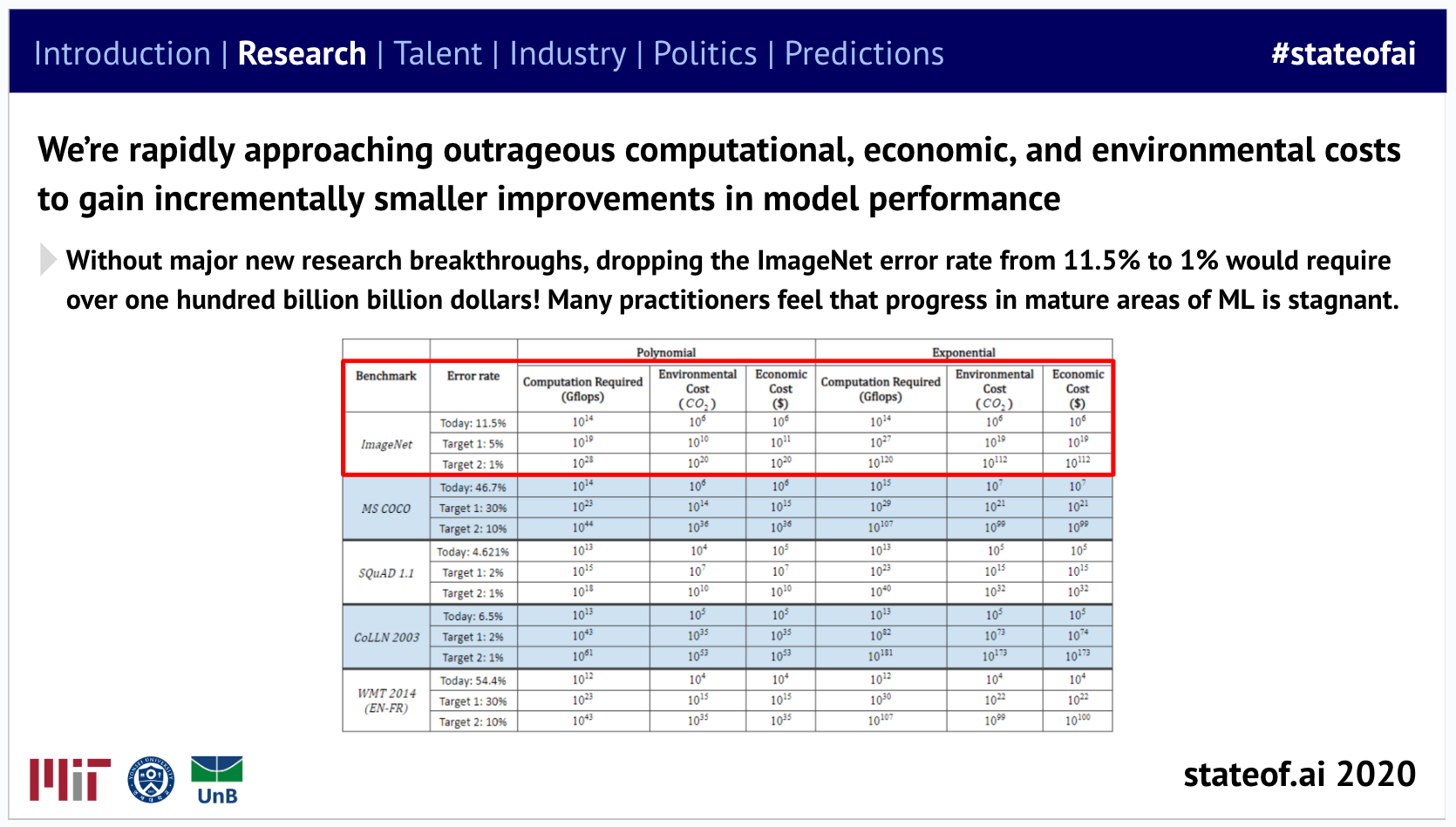
…before the industry shrugged its shoulders and scaled even more aggressively, while governments slowly began to get out their cheque books.

As LLMs became larger and more powerful, the impact of prompting on model performance became more apparent. We were learning how to coax them into generating desired behaviors…

This only deepened as we entered the era of rapid and consistent updates to LLMs.

As scale drove model performance, we began to see an interesting trend from 2022 onwards: models began to exhibit capabilities that had not been explicitly programmed by their developers. This was termed “emergence”. And while it is exciting from a capabilities point of view, this phenomenon led to understandable safety fears.

In terms of other modalities, we started to chart the leaps forward in image generation, which were still a long way from reaching public consciousness in 2019.
This initially started with Generative Adversarial Networks…

Powered by transformers, diffusion models were able to surpass GANs, drawing on their more stable training and superior ability to model the full image distribution in an ordered, step-by-step denoising process. This unlocked stable diffusion and the summer 2022 boom in image generation techniques.

We’ve also seen parallel moves forward in scene recognition and world modeling. In the early days of the report, AI’s ability to analyze and describe scenes left something to be desired. Labs were countering this by attempting to develop a common sense world model of objects and behaviors.
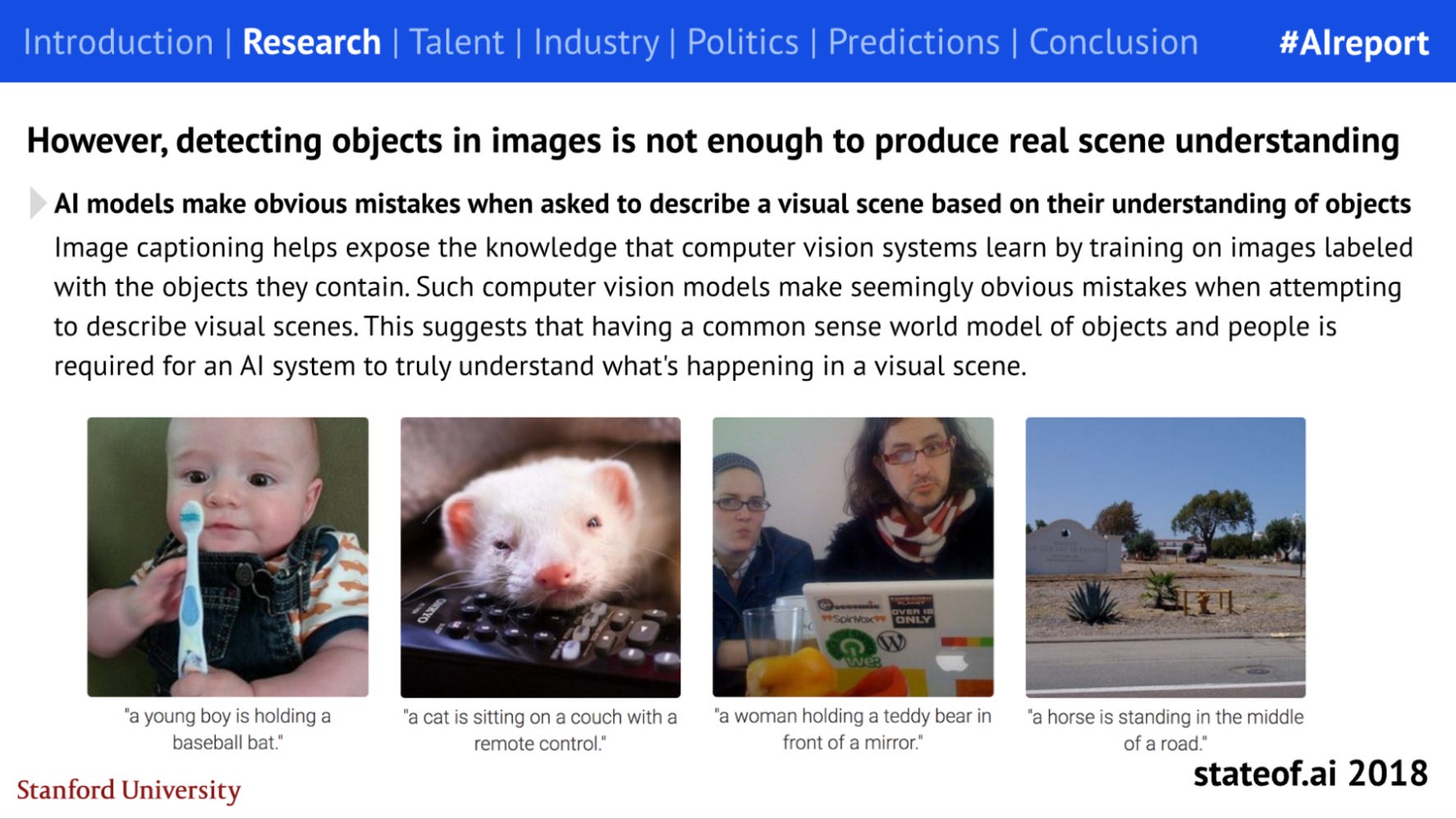
Labeled videos directly depict causal relationships (e.g. how pushing or lifting affect objects) or how objects interact and relate to each other in space and time. This helps form generalized concepts of objects, properties, and dynamics, sometimes termed “intuitive physics”

OpenAI effectively ‘solved’ this challenge in two stages.
CLIP used 400M image-text pairs - orders of magnitude more than any previous model - and was trained via self-supervised learning to predict which text matched an image without manual annotations.This was also in OpenAI’s more open era and the model was open sourced. GPT-4V now is able to analyze image inputs provided by a user to a high degree of accuracy, as the next frontier in large models becomes multimodality.

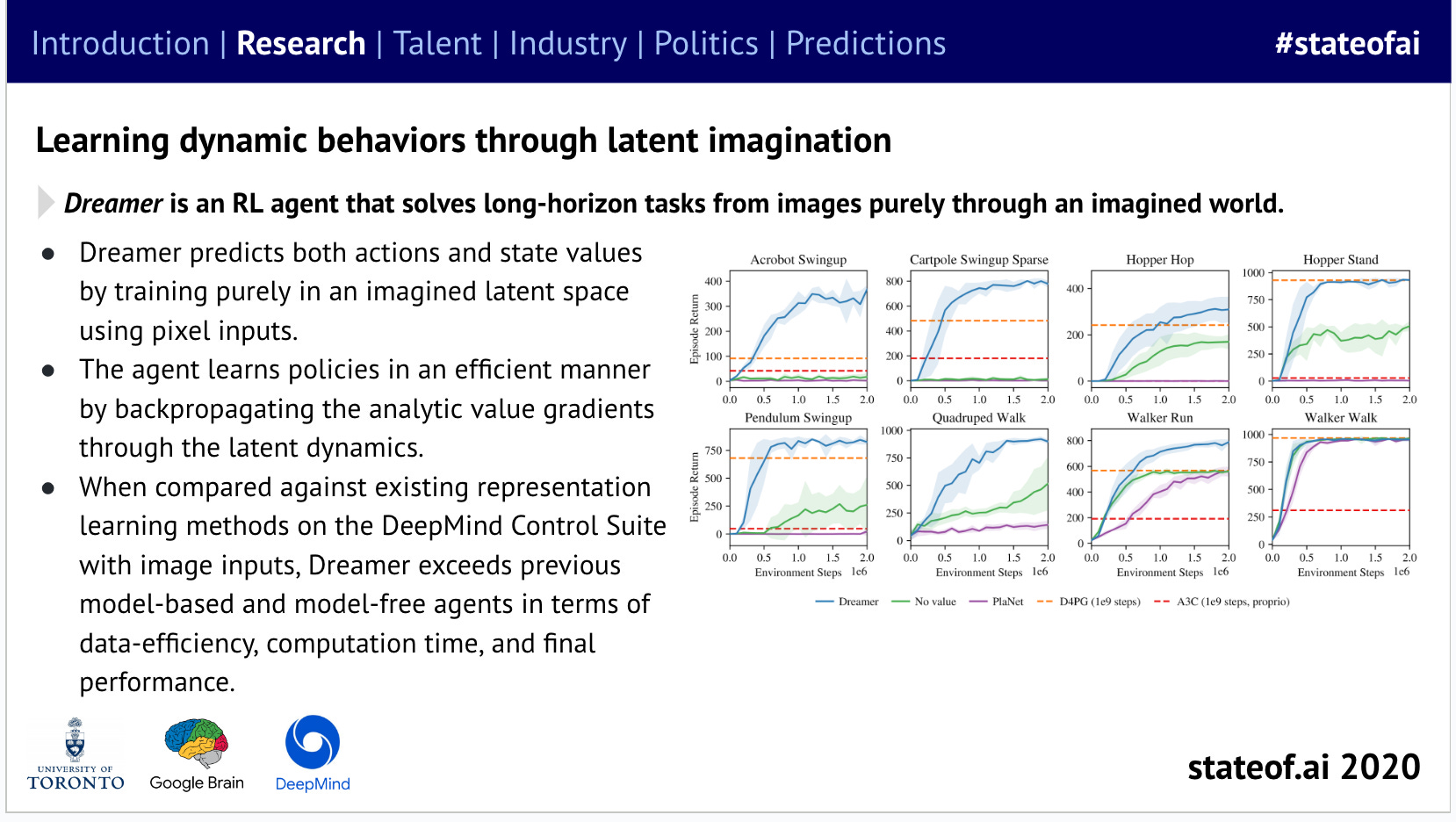
In the "agentic world", we saw the emergence of models like Dreamer, DreamerV2, DreamerV3, and PlaNet. They represented a shift towards model-based reinforcement learning, where agents not only learn a policy but also construct a world model that can be used for planning and decision-making. This allows the creation of agents that can generalize from past experience to achieve goals in complex environments.
This had obvious applications in self-driving, where the ability to predict future states is valuable for safety, efficiency, and anomaly detection. Wayve found it was possible to drive significant improvements in speed and steering.

Wayve then went on to build a powerful generative world-model, with impressive generalization abilities.

Large-scale AI progress was only possible because fierce competition between labs drove progress
When we first started to produce the report, AI research sometimes felt like a one-horse race, with Google and DeepMind sweeping all before them. Our first report referenced just one paper from OpenAI, while Microsoft was the only other corporate research lab to make it into the league tables.
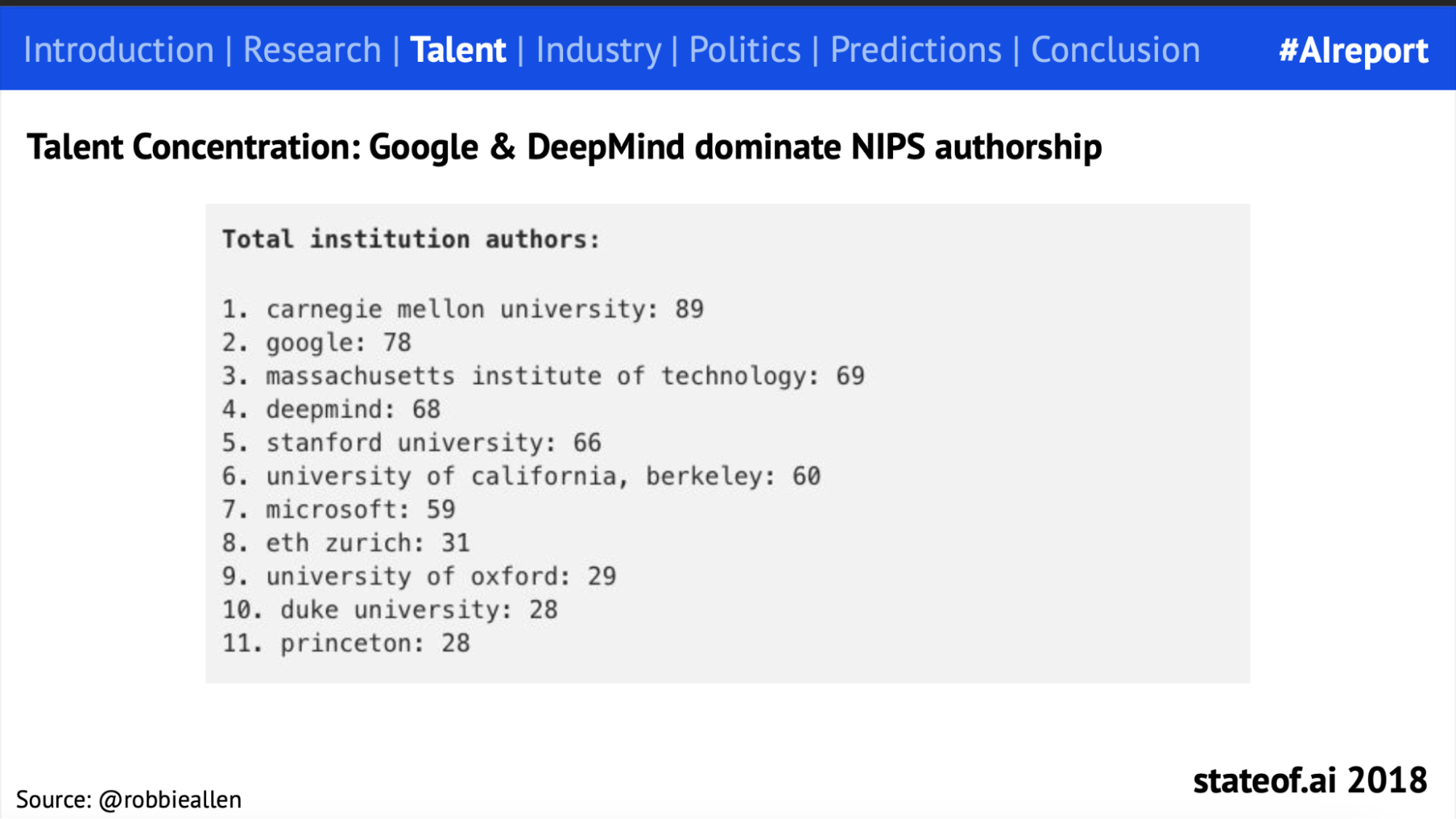
However, an increasingly aggressive talent war played out as other labs began to significantly up their output. Good for industry, less good for university faculties.

As the LLM boom began to pick up steam, a diffusion that many had previously dubbed impossible began to take shape. As research groups found that more and more massive online scraping unlocked better performance, they began to make the investment. They also had the advantage of pre-training and fine-tuning being separate steps, meaning they could pick up a pre-trained base model and fine-tune it themselves.

We also saw a boom in open source, which the push towards closedness from Big Tech for commercial safety reasons has done nothing to slow down.
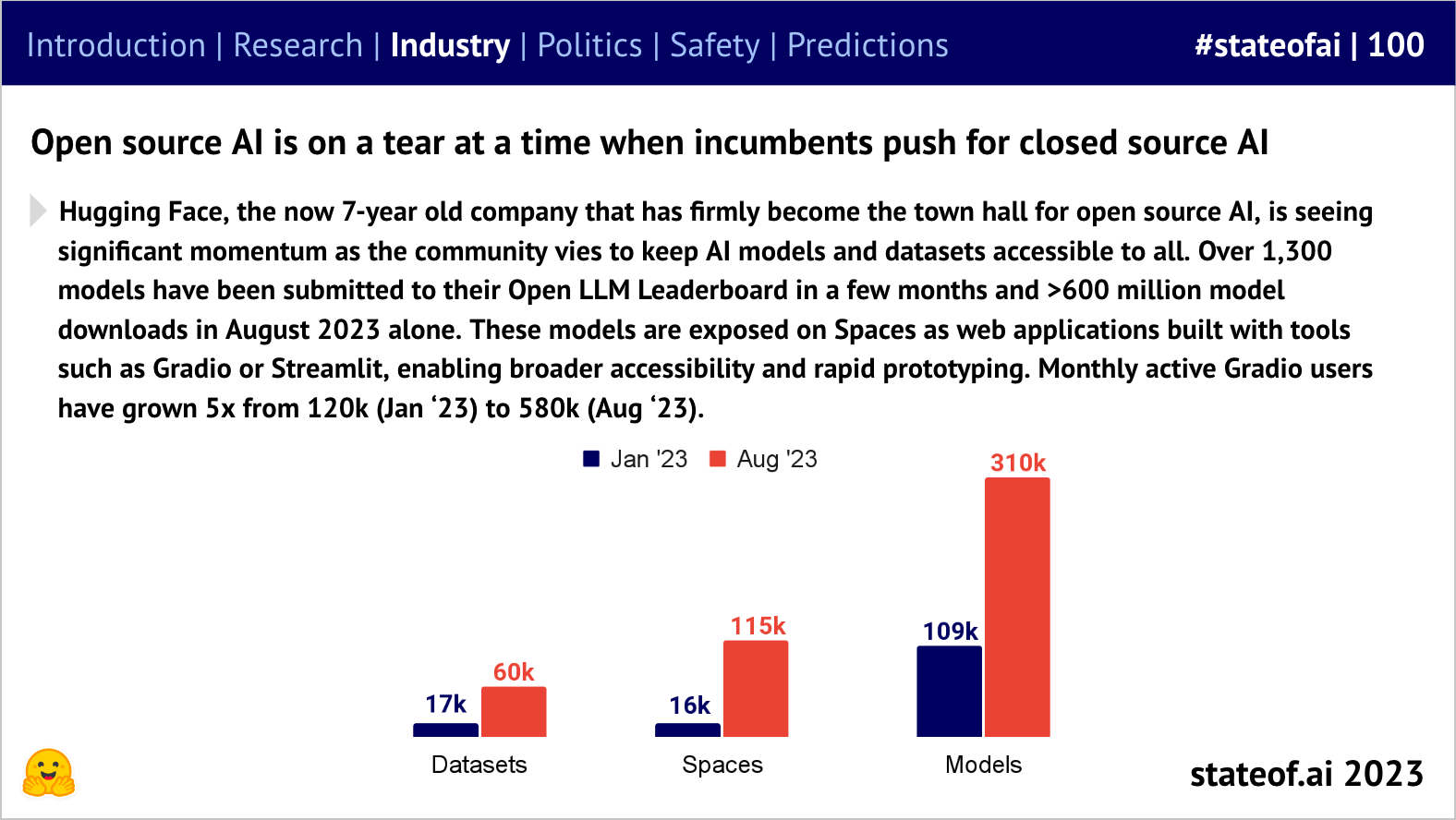
Competition didn’t just produce fundamental research, but useful tools
ML frameworks stripped out the need for researchers to spend their time stitching together low-level linear algebra and gradient calculations, enabling quick prototyping and iteration.
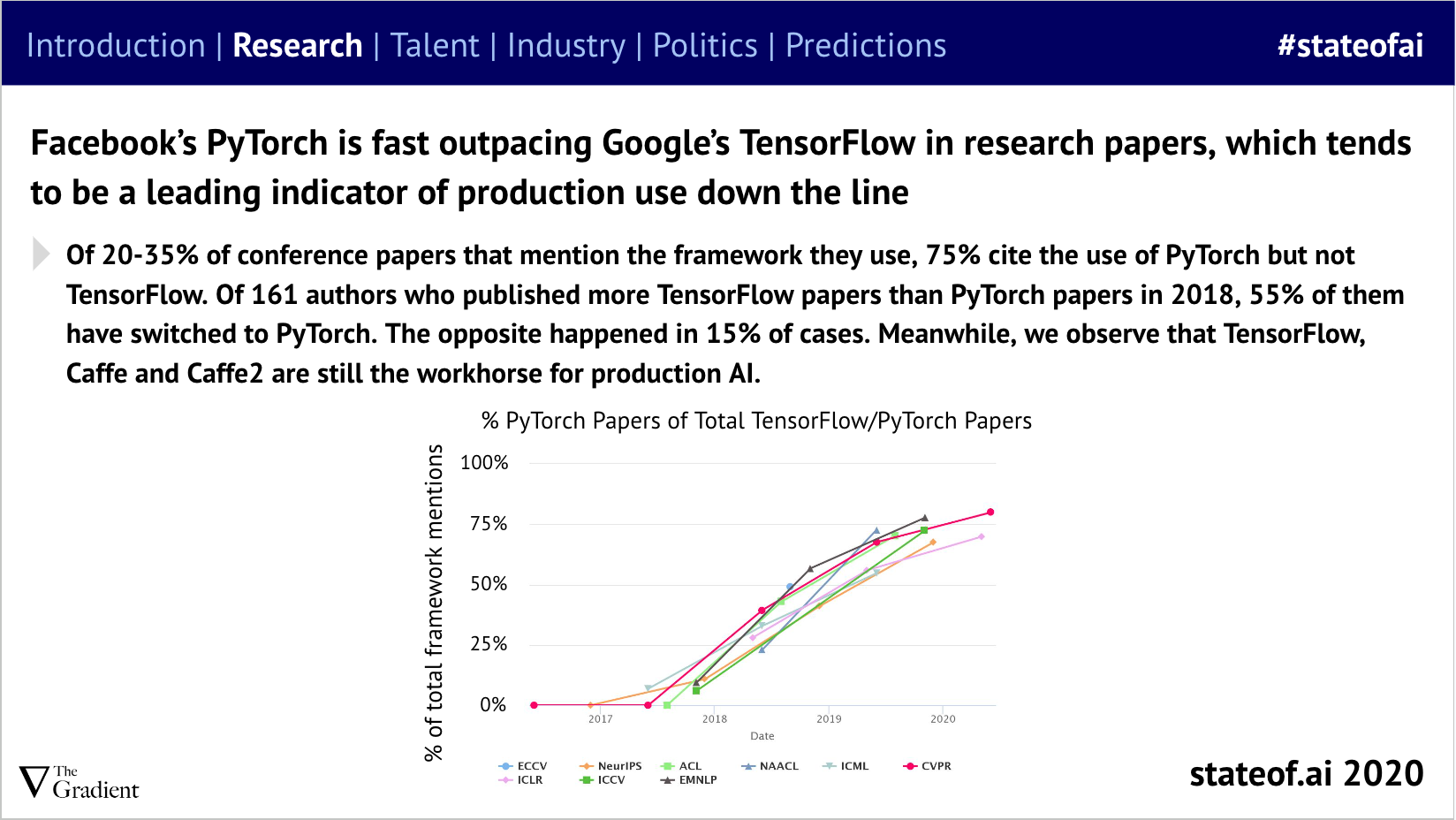
In the report’s first installment, Google’s TensorFlow appeared to be the master of all it surveyed…

But this lead was transient, with Meta’s PyTorch Python-native design, flexibility, and ease-of-use meant that within a couple of years, it had become the most popular framework by far. So far, no one has successfully challenged it.
But a new challenger is picking up steam in JAX, which has been used for both Grok and Gemini. We highlighted the potential of this framework back in 2021:

AI accelerates foundational scientific research
As a biologist by training, the pace of progress in AI for science has been dizzying. Our first report in 2018, for example, didn’t have huge amounts to say on fundamental scientific breakthroughs driven by the use of AI, but this started to change pretty quickly in 2020.

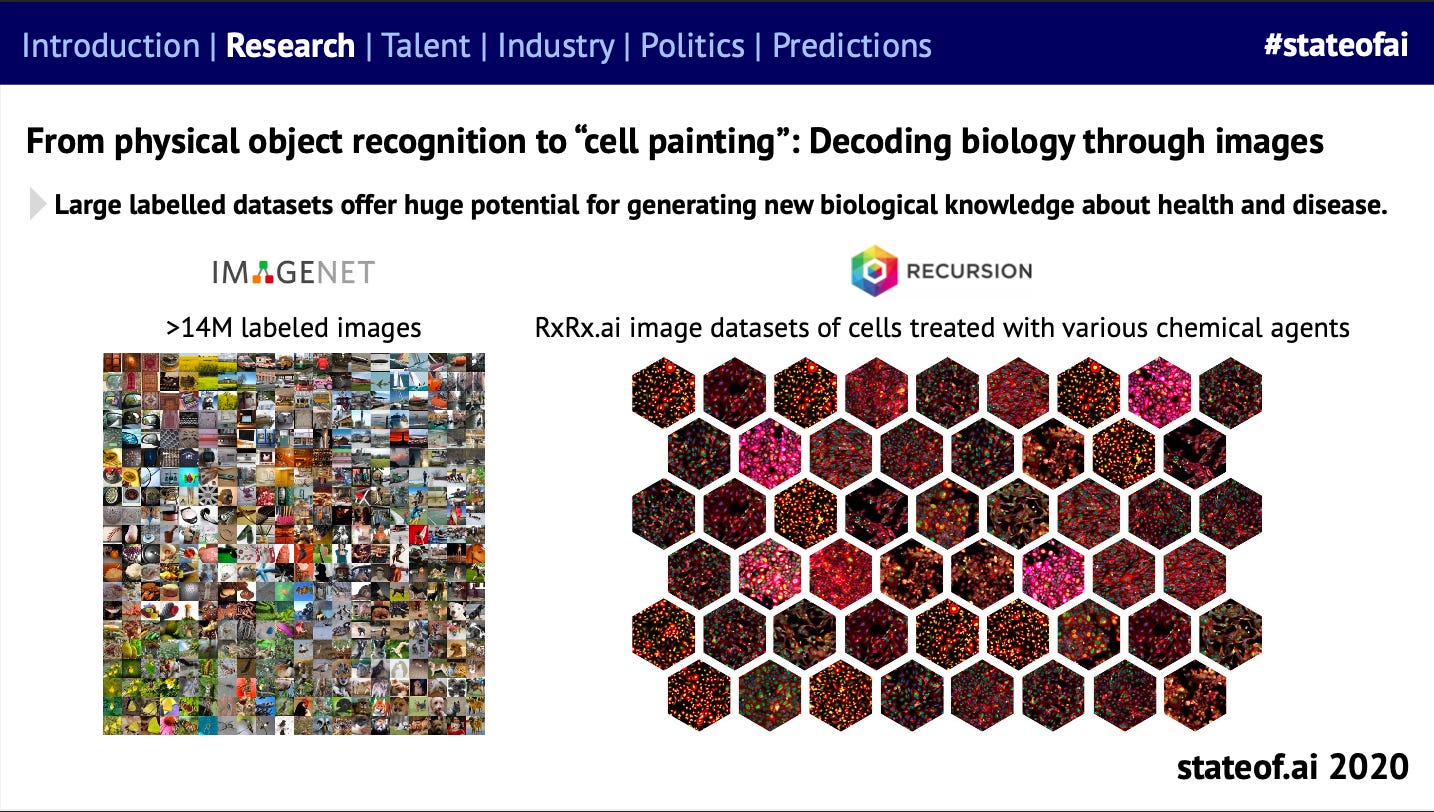
We saw deep learning-based computer vision begin to retool traditional image analysis methods in microscopy - pioneered in the industrial setting by our friends at Recursion.
While Ali Madani, who would go on to found Profluent several years later, was ahead of the curve, in using LLMs for de novo protein design - this was an extension of the CodeGen (code generation) models he helped develop at Salesforce Research. Indeed, code turns out to be code - whether for silicon or biological computers.
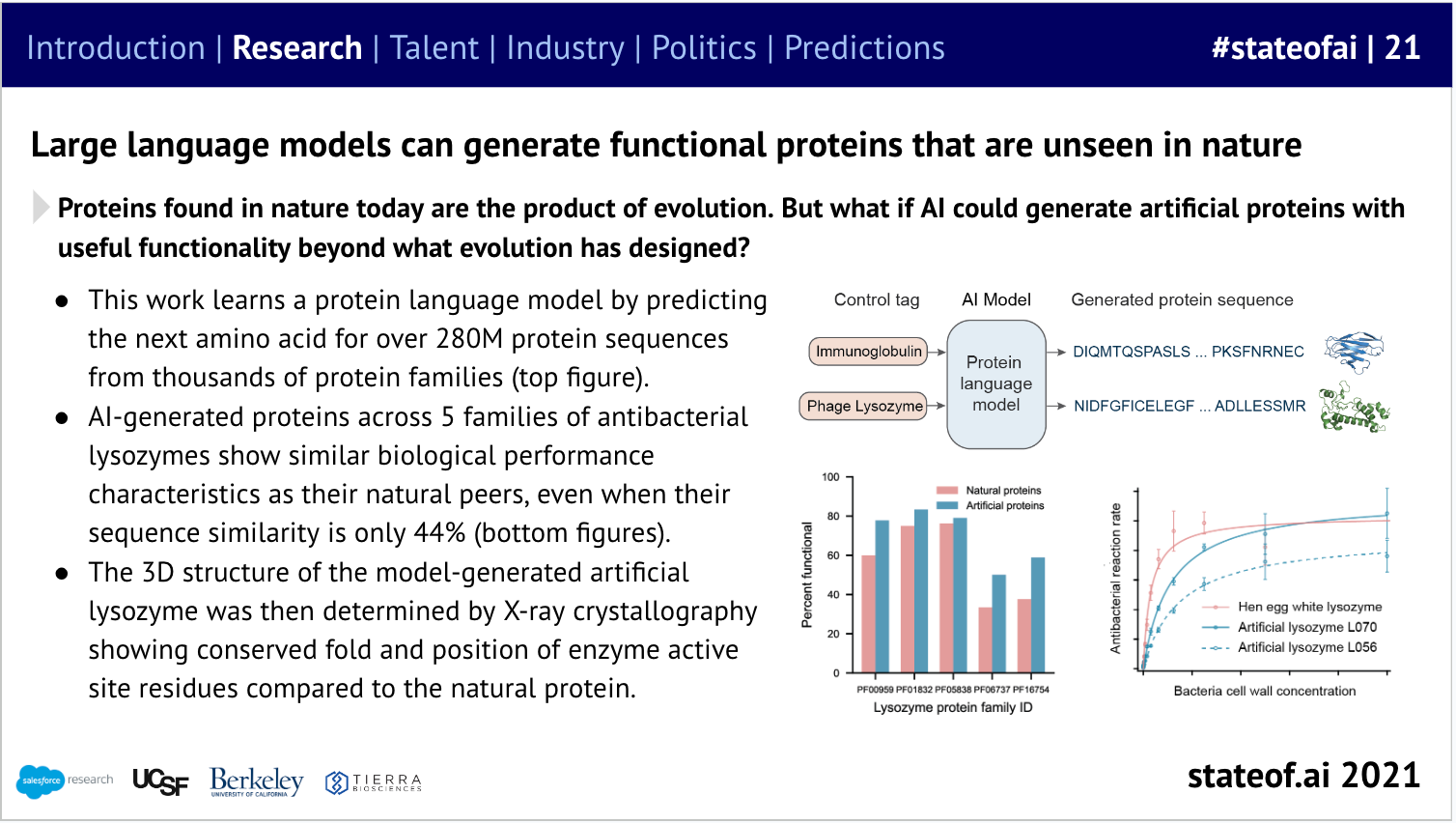
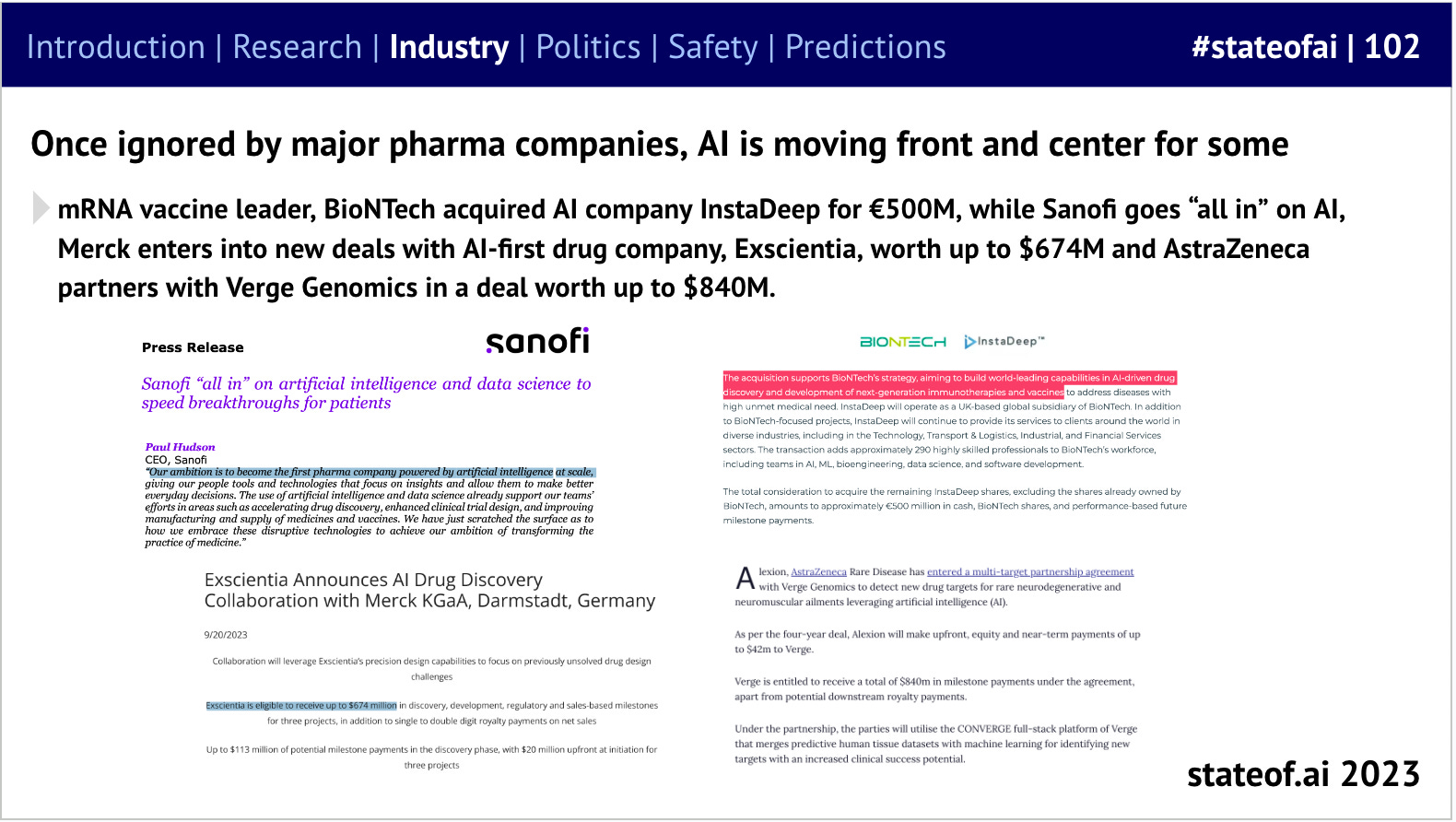
Start-ups forged ahead on these applications, traditional pharma stayed on the sidelines. Early experiments in AI-powered drug discovery had yielded disappointing results and AI was largely on the sidelines of the Covid response. However, big pharma entered the arena properly in 2023.
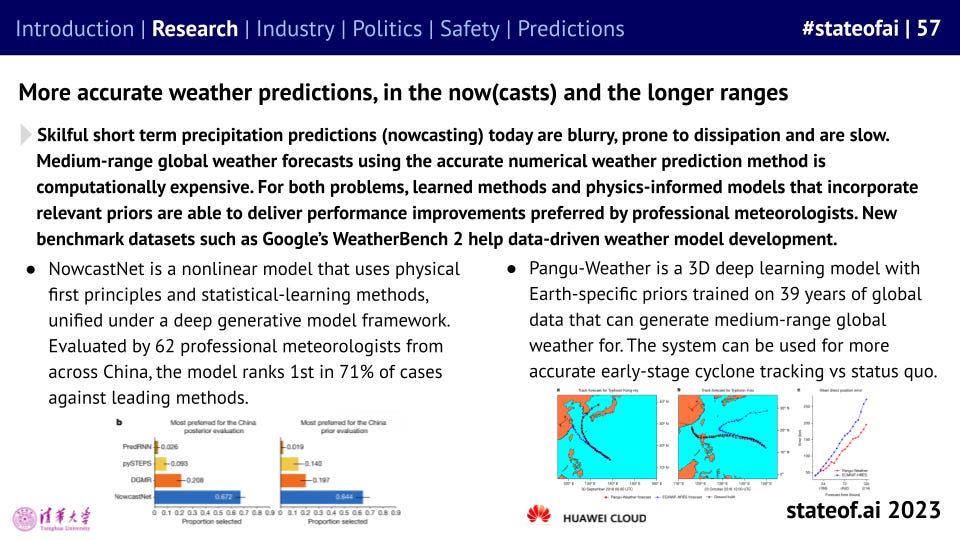
Progress wasn’t limited to biology, the volume of research across a range of scientific disciplines employing AI has increased steeply over the past few years.
Real-world applications accelerate rapidly
The use case for AI in the real (consumer) world that grabbed everyone's attention was self-driving. For years, many in the ecosystem would claim fast progress, then lament the lack of results on public roads, and then almost lose hope.


Today, things are starting to change…

Unfortunately, within a fortnight of the 2023 report being published, a Cruise vehicle was involved in a serious accident in San Francisco, resulting in the company losing its license to operate. Despite progress, the industry still faces an uphill battle.
Back in the digital world, 2020 saw the first attempts to build workflow tools based on LLMs. The first results that focused on code generation and language understanding were significant steps forward, but not yet earth-shattering…

And early forays into code generation could generate snippets of code reliably, but little more.

… and none of us predicted the sheer intensity of the disruption to incumbents that started to unfold within a couple of years.
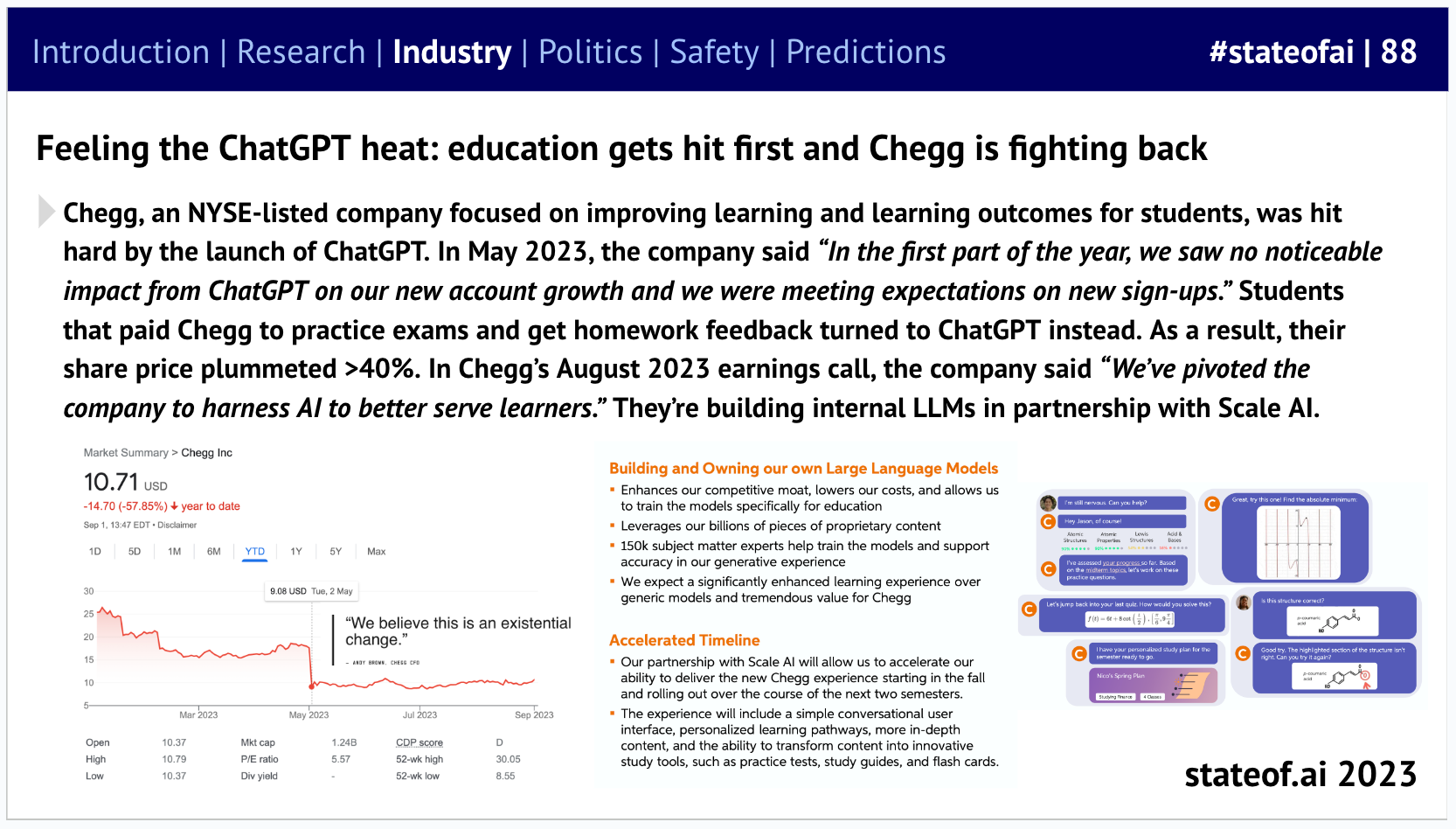
The challenge for these tools will be longer-term traction, something future State of AI editions will no doubt be tracking. So far, the jury’s out.

Defense, a previously untouchable application, is seeing disruption take off in earnest
In the early days of the report, defense was a taboo subject in much of the AI community. Early ventures from big tech sparked employee backlashes and western governments were slow to grasp its significance.
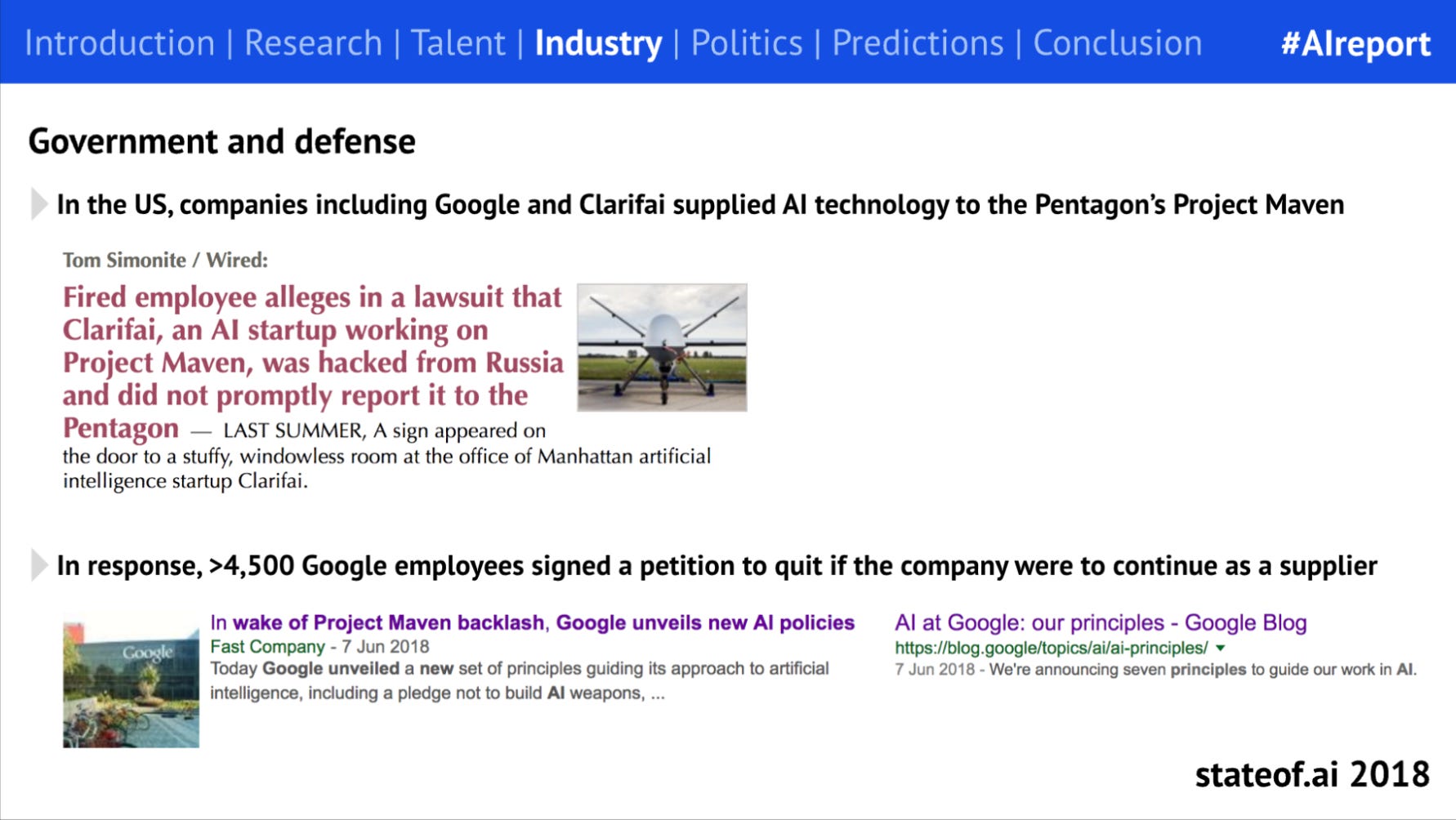
As China’s investments in capabilities increased sharply, western governments began to react and unveil dedicated defense AI investment packages. By this stage, Anduril had raised a $450M Series D and Palantir had IPO-ed, while big tech had resumed working on defense (very quietly).

Following Russia’s invasion of Ukraine, investors (largely in the US) plowed record sums of money into defense tech companies and governments established dedicated investment vehicles. However, as a sector where governments are the only legitimate customer, the meeting of new technology and old processes has run into difficulties.

The transition from the lab to the real world has been enabled by growing volumes of private capital
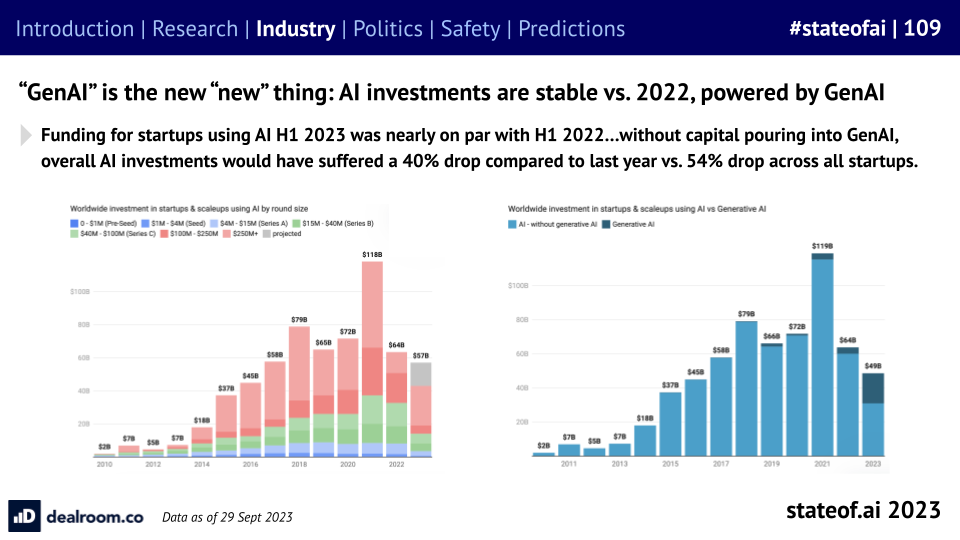
The boom in AI venture funding was picking up steam by the time we started writing the report. The Covid pandemic did nothing to slow this down.

Acceleration in progress and low interest rates fuelled investment in 2021, to the benefit of foundation model challengers.

As the macro picture worsened, generative AI held the market up like Atlas.
None of this would’ve been possible without hardware and there’s been one clear winner
Our first report documented the remarkable rise of NVIDIA as the deep learning revolution got underway…

…but back then, the race appeared competitive, with a range of start-ups focusing on AI-specific chips.

That said, as NVIDIA plowed on with R&D dedicated to this new wave of compute - as it has done several times in its history - and Big Tech explored developing its own hardware, we quickly concluded these start-ups faced an uphill battle. NVIDIA installed CUDA, its GPU programming framework, and its GPUs were too great to unseat. We repeatedly predicted the demise of some of these start-ups. While there have been downrounds, the consolidation we anticipated in 2021-2023 has not happened … yet.

As labs fought tooth-and-nail for every GPU they could lay their hands on, we began tracking HPC clusters.
By 2023, with compute fully established as the “new oil”, start-ups wielding their clusters in their marketing material:

That said, NVIDIA didn’t get its way on everything. In 2020, NVIDIA planned to acquire Arm, a leading provider of processor IP.
Amid fears that the UK would lose a crown jewel and that Arm would become part of the intensifying US/China trade war, we predicted that the acquisition would not complete. We were vindicated, with NVIDIA first announcing a delay, before abandoning the deal altogether.

Politics: moving from a subplot to the main story arc
AI had already seen its Sputnik Moment with the AlphaGo/Lee Sedol challenge match in 2016 and governments were taking note.
The report documented the emergence of the first national AI strategies in 2018 and 2019, before the tsunami that followed in later years. At the same time, Ian was documenting the trend in more detail in his well-received essay on AI Nationalism. With the exception of China’s, these largely lacked ambition. China had pledged a single $2.1 billion on a single line item, whereas the UK’s AI Sector Deal was worth £603 million. Some things never change.

By this point, the US had blocked a handful of semiconductor acquisitions by Chinese companies, but these seemed to be a minor part of a broader trade war. We predicted that this would escalate quickly and start to involve the US’s allies…

… but it took us a few years to be proven right.

After years of neglect, the safety debate comes to life
Until 2022, the report didn’t have a dedicated safety section. This reflected how, beyond a small cadre of dedicated researchers, the industry was by and large uninterested in these questions.
When we started the report, we were very much in the era of internal ethics boards, which often didn’t inspire much confidence internally, let alone externally.

The focus of these debates was also different, with the conversation dominated by important challenges, like automated decision making and algorithmic bias.

We had started to track the concern among researchers that AI labs had been focusing on capabilities while treating alignment as something as an after-thought.

When we published our estimated alignment headcounts, our inbox made it clear that we’d managed to upset a few tech companies. That said, none of them wanted to provide us with an accurate higher number…
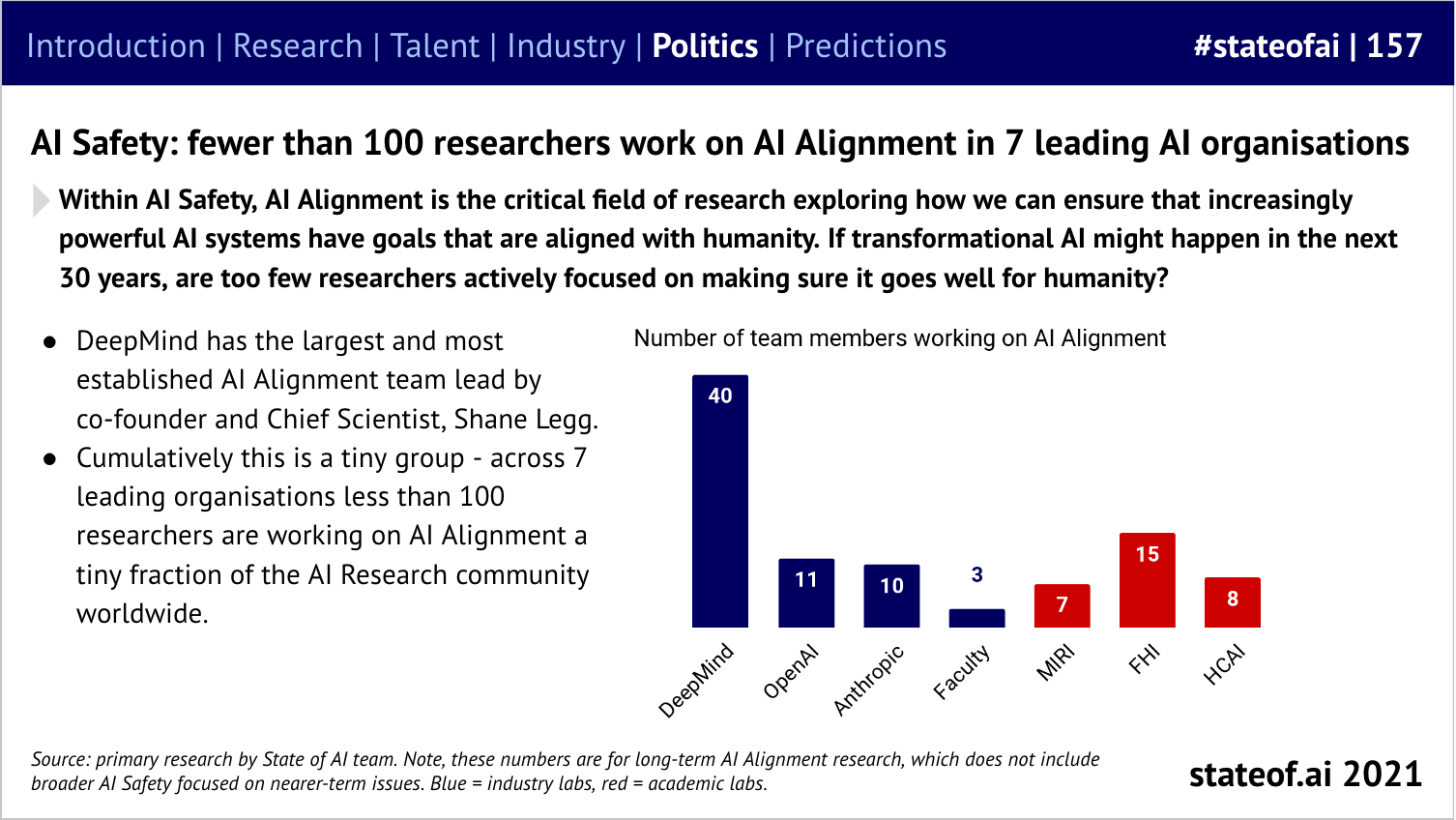
Safety then became ‘the’ conversation in 2023, as an increasingly acrimonious dispute broke out amongst prominent figures in the AI world about existential risk.
While we still don’t know for sure, it appears that some of these issues were at the heart of the chaotic boardroom politics at OpenAI towards the end of the year.

Concern about AI and elections deepens
One application with obvious political implications is video generation. Our first report charted early improvements in AI-generated synthetic video, but only a handful of people took the idea seriously 6 years ago.
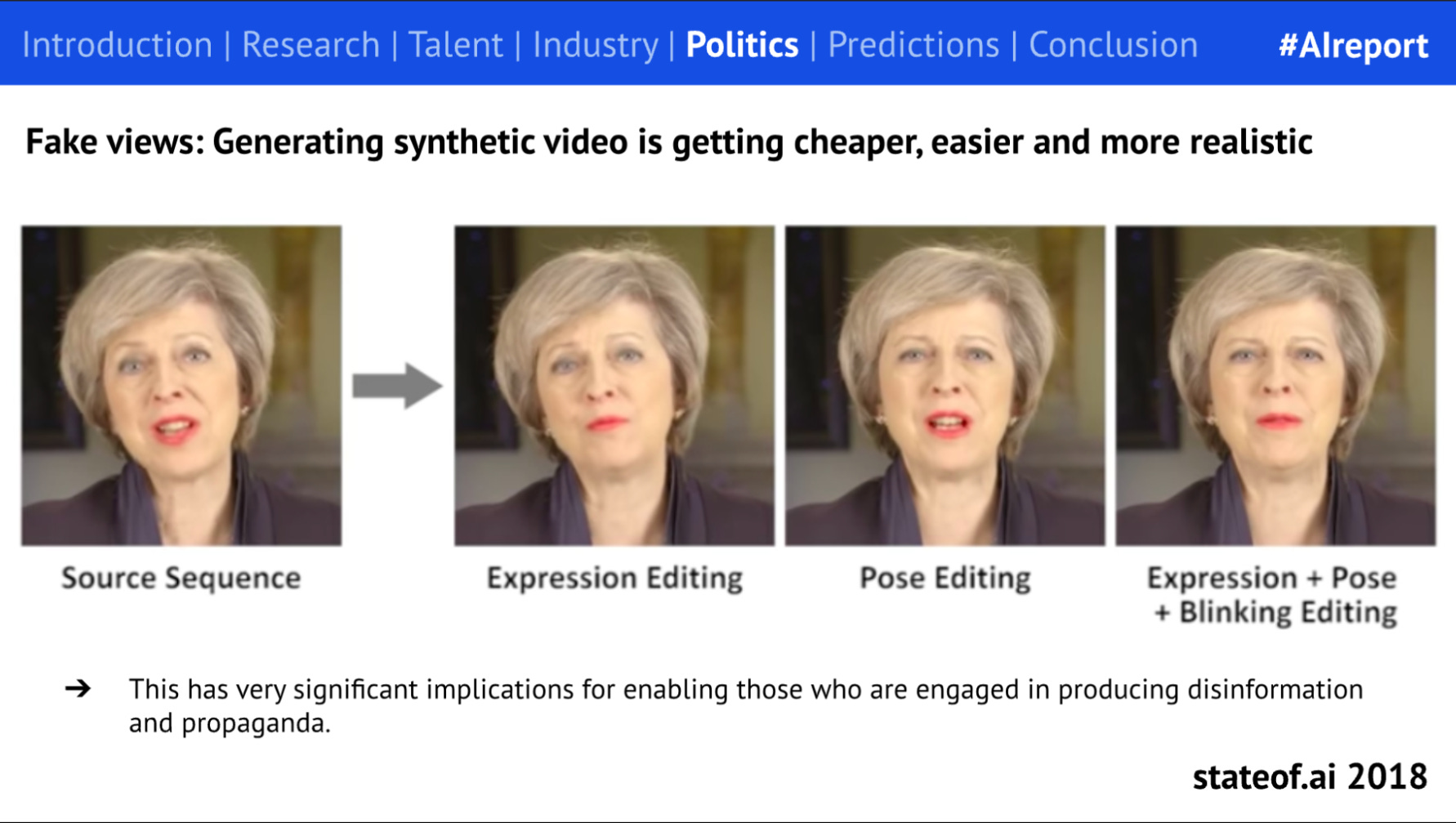
One exception was the team behind Synthesia, who anticipated the wave back in 2017 and became a surprise GenAI smash-hit.

While there has been understandable concern about the potential of this technology to be misused in a political context, efforts so far have been patchy. Raw video generation capabilities might be impressive, but manipulating them effectively is much harder, especially versus more traditional misinformation techniques. That said, 2023’s report predicts that there will be a spike in usage in the run up to the 2024 US Presidential election, prompting political and regulatory fall-out.

The EU emerges as a first-mover on AI regulation
These kinds of AI risks are central to some of the calls for regulation. High on the ‘success’ of the GDPR, the EU moved early on AI regulation, drafting the AI Act over the course of 2019-2020 and introducing it in April 2021.

Illustrating the challenge of static legislation in the face of fast-changing technology, frantic last minute rewrites were required as the boom in LLMs took off. This prompted a series of chaotic negotiations in December, the fall-out of which is still being resolved.

And some things fell by the wayside
We’ve been interested in the potential of AI as a driver of progress in material sciences. While there have been some interesting results, it hasn’t captured the imagination in the same way as other potential use cases.

People were excited about AutoML for architecture search, but it turns out that one general architecture, the transformer, with great data is what you need.
Similarly, the first edition of the report had a significant section on automation, but a few years on, it feels little has changed. Drastic warnings about the coming ‘jobocalypse’, reassurance about technology creating new jobs, and then little real-world evidence suggesting much change.
Compare 2018…

…with 2023
What’s next for us?
The State of AI Report season is one of the most energizing times of the year. We get to document all the awesome work the community’s been doing, while forcing ourselves to think about what’s ahead. It wouldn’t be possible without our reviewers, the companies that contribute data, or the team that helps me produce it. And of course, thank you to the community for giving us so much to report on. See you in October 2024 for the next installment. You can follow us on Twitter here or sign up to our newsletter to receive the next report in your inbox.
