

🗽 Your guide to AI: April 2024



Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and startups over the last month. Before we get started, our usual house-keeping:
Register interest for our annual Research and Applied AI Summit (RAAIS) on 14 June, which brings together 200 AI researchers, engineers, founders, and operators from around the world for a day of best practices and even better vibes.
Congratulations to our friends at Profluent, who raised a fresh $35M funding round. You can read the full story here.
Our latest AI meetups are coming to NYC and SF this month and next. Keep an eye on our events page to hear more once they’re live.
We’ll also be in Montreal at MILA next Wednesday to talk about forming AI startups from research. Register here.
Audio version! Click here to listen to this newsletter with Nathan’s (AI) voice. We’d love to hear your feedback on this.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
The AI world was stunned by the surprise appointment of Inflection co-founder Mustafa Suleyman as CEO of Microsoft AI. The newly-created division will focus on the company’s consumer AI efforts, with Copilot as its flagship product. Mustafa will bring a number of key Inflection staffers with him, while Microsoft will pay his former company $650M in licensing fees to provide access to Pi via Azure - presumably as a form of pseudo-acquisition payout to shareholders. Meanwhile, Inflection has said it will pivot away from its consumer-facing chatbot in favor of enterprise services.
To call the sequence of events here unusual is an understatement, but we think it’s a sign of things to come. In the past year, we’ve seen the performance of foundation models converge, while already sky-high GPU bills continue to grow. Usually a market in which a group of companies are building similar products but are struggling to make the economics work would see consolidation. However, regulators on both sides of the Atlantic have made it clear that they don't want this to happen.
Freezing the exit market might preserve the illusion of competition, but it doesn’t make non-viable businesses any more viable. As this story shows, it ends up punishing people for taking risk, whether that’s investors or early employees, who both stand to lose big. Meanwhile, we’ll be watching Mustafa’s next act closely. He may be divisive, but he’s never boring…
While we’re on the subject of competition regulators, we can’t see them being thrilled by the rumors that Apple plans to integrate Google’s Gemini into the iPhone. Apple has kept its AI cards close to its chest over the past few months, although we do know they have various on-device projects cooking behind the scenes. This silence, combined with recent internal resource reallocation, has led to speculation that these efforts aren’t running entirely smoothly, although there appear to be signs of change. More on that in the research section…
We don’t know what this partnership would involve, but it’s easy to imagine Siri getting a new lease of life or Apple moving to supercharge its image and video-editing capabilities. Either way, it would represent a huge boost for Gemini and serve as a powerful reminder not to write Google off in the AI race, despite some of its teething problems. That said, this partnership will undoubtedly be received poorly in some quarters. Google’s 2021 deal with Apple to make its Search the default search engine on Safari is now at the center of a landmark US antitrust action. Throw in Google’s plans for a paid AI-powered search engine and it’s hard to imagine the EU and the FTC staying away for long.
Moving from anti-trust to safety, back in February, the US National Telecommunications and Information Administration (NTIA), an arm of the US Department of Commerce, put out a Request For Comment on the risks and benefits of open AI models with widely available weights. Since then, we’ve seen responses pour in from a range of tech companies, academic institutions, and think tanks. While these vary quite dramatically in detail level, they provide a helpful illustration of the emerging battlelines in this debate.
Unsurprisingly, Meta put up a robust defense of openness along with Stanford HAI, while OpenAI studiously avoided any specifics, and Google DeepMind tried to steer a middle path, reframing the debate away from open vs closed. The Center for AI Policy invoked the prospect of “WDM-like AI” in a response that called for more immediate regulation. But for us, many of these responses are more interesting for what they don’t say.
With the exception of Meta, the main labs all implicitly believe that there will have to be some form of foundation model regulation in the future. However, they don’t wish to be pinned down on a specific capability threshold or commit to a theory of liability for model misuse before this happens. This inevitably results in artistic levels of vagueness in some of their policy recommendations. Problems are surfaced, before an amorphous mix of government, civil society, industry is tasked with figuring out the solutions. This triggers flashbacks to the blank cheque the then Facebook gave policymakers to regulate it at the height of the backlash against big tech. They lived to regret it and learned their lesson. Will other companies find themselves in the same position in a few years time?
While the labs agonize over the wording of their recommendations, the UK and US Governments are moving forward with the commitments made at last November’s AI Safety Summit. The UK and US unveiled an MOU, which will see the two countries’ respective AI safety institutes align their standards for testing and evaluating powerful AI models. Despite the fanfare, the MOU contains little we didn’t know before. Our more cynical readers might argue that this is the product of a government scrabbling around for good news or relevance. We couldn’t possibly comment.
🍪 Hardware
The past month saw NVIDIA’s GTC and an accompanying run of announcements. Top of the list for most people was the unveiling of the new Blackwell B200 GPU and GB200 Superchip. The system will mark a significant performance gain on the previous Hopper architecture of H100 fame, with the company claiming it can reduce cost and energy consumption 25x over an H100. To illustrate this, the company said that it was possible to run a 1.8 trillion parameter model on 2,000 Blackwell GPUs while consuming 4 megawatts of power versus 8,000 Hopper GPUs and 15 megawatts. Full production and shipping should begin later this year, but NVIDIA hasn’t committed to a specific timeframe. Strikingly, and in an illustration of NVIDIA’s power, seemingly every big AI lab CEO pledged their allegiance in the accompanying press release. As the saying goes, when asked to jump, the answer is “how high?”.
To much less fanfare, Cerebras unveiled the CS-3, underpinned by the new WSE-3 chip, which they are billing as the fastest AI accelerator in the world. The company is claiming that the CS-3 makes it possible to train a 24 trillion parameter model (over 10x bigger than the current largest frontier models) on a single device. Cerebras appears to be planning for an IPO in the second half of this year, targeting an increase on its current $4 billion valuation. Considering the company has struggled to compete with NVIDIA at scale, due to its admittedly powerful product being difficult to manufacture and scale economically, an IPO may seem like a bold move. But as the rising public market tides continue to lift all semiconductor boats, it may well pay off.
Past editions of the newsletter have covered Sam Altman’s ambitions for a multi-trillion dollar international chip empire that breaks OpenAI’s dependence on NVIDIA. OpenAI is rumored to be in talks with Abu Dhabi state-backed investor MGX, following separate discussions with Singapore-backed Temasek. There are separate rumors that OpenAI has been pitching Microsoft on plans for a $100 billion super monster enormous data center. If approved, this would be orders of magnitude larger than any other Microsoft data center. It would also be set up to give Microsoft and OpenAI the flexibility to use alternatives to NVIDIA GPUs.
This all reinforces the tightrope that OpenAI is (so far quite masterfully) walking. On the one hand, the eye-watering sums of money its ambitions require are far beyond the reaches of standard VC funding, but international sovereign wealth is fraught with risk. If we take MGX as an example, one of its founding partners is G42, which attracted concerns from US intelligence officials over its ties to China. The UAE and China have been forging closer military ties, while Chinese-developed surveillance technology is deployed on the streets of its cities. While these issues are removed from chips per say, it’s not hard to envisage the Congressional subcommittees that previously investigated TikTok taking an interest. For now, OpenAI just needs GPT-5 to wow and for Microsoft to keep writing the checks. No pressure then.
Europe meanwhile might be able to gain a surprising new semiconductor hub: Italy. After the country failed to bribe convince Intel enough to build out local capacity, Singapore-based semiconductor integrator Silicon Box will invest €3.2 billion to build a chip factory in northern Italy. This deal will likely have received significant government financial support, but the details are yet to be published. As with many of these European chip subsidy arrangements, we remain skeptical that onshoring tiny portions of the supply chain guarantees ‘sovereignty’ in the event of an actual geopolitical shock. That said, this all pales in comparison to the $20 billion in grants and loans Intel will receive from the US government via the Chips Act.
🏭 Big tech start-ups
As the open source ecosystem continues to go from strength to strength, Databricks has emerged a surprise new leader with the release of DBRX. The model uses a fine-grained mixture-of-experts (MoE) architecture, encompassing 132B parameters. It surpasses competitors like Mixtral and Grok-1 in granularity by operating with 16 smaller experts - selecting 4 for any given task - facilitating a significantly higher diversity in expert combinations that enhance model performance. The model was pretrained on 12T tokens of curated data and a maximum context length of 32k tokens, with the team finding that curriculum learning for pre-training drove significant improvements in results. This is interesting validation for a technique that’s long had potential, but has been under-discussed as an approach to improving training performance.
The resulting model outperformed established open source models across a range of benchmarks, while surpassing GPT-3.5 and being competitive with Gemini 1.0 Pro.
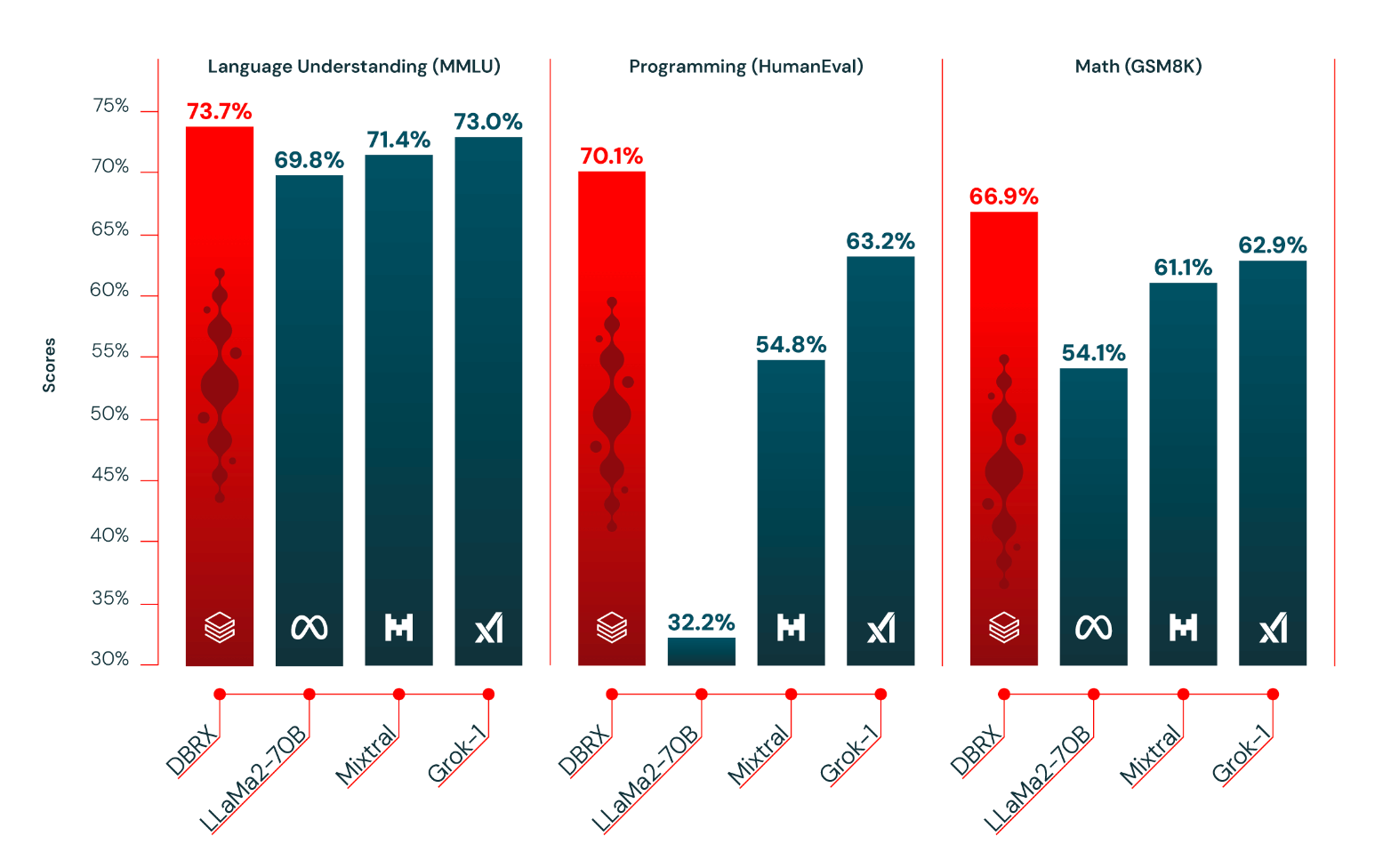
The work took the team approximately 3 months, a relatively lean $10M, and required 3,072 NVIDIA H100s. However, it’s always worth taking the cost figures from tech companies with a pinch of salt, as they don’t include investments carried over from previous models or projects.
After Elon Musk launched his legal action against OpenAI for its lack of openness, a number of AI commentators on X questioned why Grok was closed. In response, xAI released the base model weights and network architecture of Grok-1. Openness is welcome but, given the size of the model, most people would struggle to run it locally without access to a GPU server. In a busy few weeks for the company, xAI also announced Grok-1.5. As well as a new 128k context length, xAI recorded significant performance gains in coding and math-related tasks, with a particularly strong performance on HumanEval, a code generation and problem-solving benchmark. The model is competitive with Mistral Large, Gemini Pro, and the March 2023 release of GPT-4.

After impressing observers with the new Claude 3 family, Anthropic received $2.75B from Amazon as part of its $4B commitment to the company. As part of the arrangement, Amazon will be the company’s primary (although not exclusive) provider of cloud services. Anthropic is still conducting a separate fundraising process, expected to total at least $750M. One early Anthropic investor we don’t hear much from these days is FTX. The majority of the fallen crypto exchange’s 8% stake in the company was sold this month, with the largest buyer being an affiliate of Emirati sovereign wealth fund Mubadala. A bid from Saudi Arabia was turned down on national security grounds.
OpenAI has revealed that it has been building Voice Engine, a text-to-speech and voice cloning model. The company first developed it in 2022 and used it to power some of the text-to-speech functionalities bundled with ChatGPT. The company has now released snippets of audio in multiple different languages, but has opted not to make the model accessible, citing safety concerns. OpenAI warns that we urgently need to improve public awareness of the potential of deceptive content, phase out voice-based authentication as a security method, and build better provenance tools. While some immediately accused OpenAI of using safety fears as a marketing tactic, considering the number of major elections looming this year, it’s understandable that the company may have decided that this isn’t a regulatory storm worth sailing into just yet.
🔬Research
A generalist AI agent for 3D environments, Google DeepMind.
Presents SIMA, a generalist agent that can follow natural language instructions to navigate and interact within a wide range of 3D virtual environments, including research platforms and video games, marking a significant advance on systems trained for specific environments.
The core of SIMA’s architecture is an image-language model, combined with a video prediction model that anticipates how the environment will change over time. The DeepMind team partnered with 8 game studios to expose SIMA to 9 different video games, ranging from open-world exploration tophysics-based sandboxes. They also used 4 custom research environments, including a Unity-based "Construction Lab" where agents have to build sculptures from building blocks. This diversity of 3D environments was crucial to imbuing SIMA with broad, generalizable capabilities. The researchers further trained SIMA on a large dataset of human-generated language instructions paired with the corresponding game actions, recorded from gameplay sessions where one player provided instructions to another.

The multimodal approach allowed SIMA to interpret instructions and execute actions in unfamiliar settings, demonstrating robust zero-shot learning abilities. Based on an evaluation of 1,500 unique in-game tasks, the researchers found that in each game, SIMA outperformed all the specialized agents.
Long-form Factuality in Large Language Models, Google DeepMind.
Introduces a new framework, consisting of a dataset, evaluation tool, and metric, for assessing the factuality of LLMs in producing long-form content.
LongFact is a dataset consisting of 2,280 fact-seeking prompts (generated by GPT-4) across 38 topics, designed to assess the ability of LLMs to generate accurate long-form responses. SAFE, the evaluation tool, automates the process of dissecting a model's response into individual facts and assessing their accuracy using Google Search in a multi-step reasoning process. This approach is demonstrated to be more reliable and over 20 times cheaper than human annotators.
The evaluation metric, F1@K, is an adaptation of the F1 score that balances the precision and recall of a response, taking into account the number of supported facts relative to a hyperparameter representing a user's preferred response length (K).

The results from benchmarking thirteen models from across four families (Gemini, GPT, Claude, and PaLM-2) found that larger models within these families performed better in terms of long-form factuality. Between families, GPT-4 Turbo was the strongest performer, followed by Gemini-Ultra, and Claude-3 Opus.
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training, Apple.
Provides a glimpse into Apple’s approach into developing high-performing large multimodal models. The authors lay out their findings on optimal design, finding that using a mix of image-caption, interleaved image-text, and text-only data is important, in contrast to other published pre-training approaches. Additionally, the image encoder, image resolution, and image token count have substantial impact, while the vision-language connector design is less critical.
Based on these insights, the authors constructed the MM1 family of multimodal models of up to 30 billion parameters. This includes both dense models and mixture-of-experts variants. After supervised fine-tuning, the MM1 models demonstrate competitive performance on established multimodal benchmarks. The authors also note that the large-scale pre-training endows the MM1 models with enhanced in-context learning and multi-image reasoning capabilities.

Generative AI for designing and validating easily synthesizable and structurally novel antibiotics, Stanford, McMaster University.
Presents SyntheMol, a generative model for drug design, optimized for creating easily synthesizable molecules. In contrast to models that evaluate molecules one-by-one, SyntheMol uses a combination of molecular property prediction models and Monte Carlo tree search to efficiently explore a vast combinatorial space of potential drug molecules. The Monte Carlo tree search algorithm allows SyntheMol to iteratively build up candidate structures by making sequential decisions about which molecular fragments to add or modify, guided by the model's training on a large dataset of known drug-like molecules.

The researchers consciously built SyntheMol to design easy-to-synthesize molecules to enable wet lab validation, avoiding the common challenge of synthetically intractable AI-designed molecules that can’t be tested in the real world. When tested, SyntheMol was able to generate six novel antibiotic compounds that displayed broad-spectrum antibacterial activity against multiple bacterial species, including A. baumannii, a bacterium with few known treatments. The code, along with the data and models, is fully open sourced. Jonathan Stokes, the main author, spoke at RAAIS in 2020 on the use of chemical biology and AI to develop novel antibacterial therapies. Check out the talk here to see how this work’s evolved.
Also on our radar:
A Toolbox for Surfacing Health Equity Harms and Biases in Large Language Models, Google. Introduces a framework for identifying bias in medical LLMs, introducing an assessment rubric and seven newly-developed datasets (EquityMedQA) designed to test for health-equity related biases through adversarial queries. In an empirical study involving 17,000 ratings by physicians, health equity experts, and consumers, the framework demonstrated its ability to surface specific biases in LLM-generated medical advice.
Whole-body simulation of realistic fruit fly locomotion with deep reinforcement learning, HHMI Janelia, Google DeepMind. Introduces an anatomically detailed, biomechanical whole-body of a fruit fly for simulating realistic locomotion behaviors, such as flying and walking. Developed with the open source MuJoCo physics engines, the model includes sophisticated representations of the fly’s body parts, fluid forces during flight, and adhesion forces. Incorporating deep reinforcement learning, allows for the creation of neural network controllers that drive the simulated fly in complex trajectories and tasks based on sensory inputs, achieving high fidelity in locomotion simulation.
Cosmopedia: how to create large-scale synthetic data for pre-training, Hugging Face. Recreates the synthetic training dataset Microsoft used for the Phi family of models, generating synthetic textbooks, blog posts, and stories over 30 million files and 25 billion tokes using Mixtral-8x7B-Instruct. The team details the process, the challenges, and makes the dataset and accompanying model, which is competitive with non-frontier models, available openly.
SegmentNT: annotating the genome at single-nucleotide resolution with DNA foundation models, InstaDeep. Presents SegmentNT, which uses a foundation model trained on DNA sequences to annotate genomes at single-nucleotide resolution. This method can identify functional regions within DNA, such as protein-coding genes and regulatory elements, with high accuracy. By leveraging the powerful representation learning capabilities of foundation models, SegmentNT can capture complex patterns in genomic data that are difficult to detect using traditional bioinformatics techniques.
The Unreasonable Ineffectiveness of the Deeper Layers. Meta and MIT. Looking at open-weight pre-trained LLMs, argues that many deeper layers contribute little of substance to overall model performance. The authors find it’s possible to eliminate up to half of a model’s layers with negligible performance drops on various question-answering benchmarks. They identified optimal layers for removal based on similarity and then “healed” the model through small amounts of efficient fine-tuning. This suggests that architectural choices and training techniques should focus on improving the effectiveness of deeper layers, rather than simply increasing model depth.
Re-evaluating GPT-4’s bar exam performance, MIT. Argues that OpenAI’s claim that GPT-4 achieves 90th-percentile performance on the Uniform Bar Exam is over-inflated. The paper finds that while GPT-4's UBE score nears the 90th percentile on approximate conversions from the February Illinois Bar Exam (which is skewed towards repeat test-takers who tend to perform less well), while data from a recent July administration suggests GPT-4's overall percentile was below the 69th, and around 48th on essays.
Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion, Waabi. Presents Copilot4D, a foundation model for the physical world, which is able to reason in 3D space and time. By tokenizing 3D sensor observations, it’s possible to train a discrete diffusion model to efficiently predict the future of the driving environment. Experiments show this method significantly outperforms prior state-of-the-art techniques, reducing prediction error by over 50%. The authors demonstrate the potential of this unsupervised, diffusion-based approach to advance autonomous driving capabilities without relying on expensive labeled data.
Biophysics-based protein language models for protein engineering, University of Wisconsin-Madison. Proposes a new protein language model framework called Mutational Effect Transfer Learning (METL) that combines AI with biophysical modeling. Unlike existing protein language models that rely solely on evolutionary data, METL is pre-trained on biophysical simulation data to capture fundamental relationships between protein sequence, structure, and energetics. When fine tuned on experimental sequence-function data, METL can leverage these biophysical signals to excel at challenging protein engineering tasks like generalizing from small training sets and extrapolating to new protein positions.
💰Startups
🚀 Funding highlight reel
Applied Intuition, building simulation software for autonomous vehicles and defense, raised a $250M Series E, led by Lux Capital, Elad Gil, and Porsche.
Fieldguide, building automation and collaboration software for assurance and advisory firms, raised a $30M Series B, led by Bessemer Venture Partners and Elad Gil.
Foundry, a cloud compute workload orchestration platform, raised a combined $80M seed and Series A, led by Sequoia Capital and Lightspeed Venture Partners.
Haiper, building foundation models for video and content creation, raised a $13.8M seed round from Octopus Ventures.
HeyGen, a generative AI video platform, raised $60M from Benchmark.
Higgsfield, an AI-powered video generation and editing platform, raised an $8M seed round, led by Menlo Ventures.
Hippocratic AI, creating AI agents for hospitals and clinics, raised a $53M Series A, led by General Catalyst.
Hume, building ‘emotionally intelligent’ conversational AI, raised a $50M Series B, led by EQT Ventures.
Lambda, the GPU cloud company, raised a $500M special purpose GPU finance vehicle, led by Macquarie Group.
Luminance, building a legal co-pilot, raised a $40M Series B, led by March Capital.
Metaview, which is using AI to rework business workflows, raised a $7M Series A, led by Plural Platform.
Minimax, building a chatbot and video/image/audio generation platform, raised a $600M Series B, led by Alibaba.
OpenPipe, allowing start-ups to build their own fine-tuned models, raised a $6.7M seed round, led by Costanoa Ventures.
Orchard Robotics, building AI-driven camera systems for crop management, raised a $3.8M seed round, led by General Catalyst.
Picogrid, unifying autonomous systems for military operations, raised a $12M seed round, led by Initialized Capital.
Physical Intelligence, developing foundation models for robotics and other physical devices, raised a $70M seed, led by Thrive Capital.
Profluent, an AI-first protein design company, raised a $35M funding round, led by Spark Capital alongside Air Street Capital and Insight Partners.
Rabbit, building an AI-powered companion device, is raising a fresh $28M funding round, investors tbc.
Skyflow, a data privacy vault company for AI, raised a $30M Series B extension, led by Khosla Ventures.
Synch, an integrated sales and GTM platform, raised a $3M seed round, led by AltCap and Haystack.
Together AI, a provider of inference, fine-tuning and GPU access, raised a $106M Series A, led by Salesforce Ventures.
Unstructured, working on ingestion and preprocessing for LLMs, raised a $40M Series B, led by Menlo Ventures.
Vizcom, producing AI-powered software for industrial design, raised a $20M Series A, led by Index Ventures.
Zephyr AI, developing explainable AI solutions for precision medicine, raised a $111M Series A, led by Revolution Growth, Eli Lilly & Company, Jeff Skoll, and EPIQ Capital Group.
🤝 Exits
DarwinAI, developing technology for inspecting components during manufacturing, was acquired by Apple.
---
Signing off,
Nathan Benaich and Alex Chalmers 7 April 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | London.AI
Air Street Capital invests in AI-first technology and life science entrepreneurs from the very beginning of your company-building journey.
