




Hi all!
Welcome to the first issue of your guide to AI of 2024, which marks the 9th year of this newsletter. I started with 6 (brave) friends back in October 2015 and now count almost 25,000 readers, thank you! We’ll kick off the year with the most important developments in AI policy, research, industry, and start-ups. As ever, some housekeeping from us:
State of AI: We published our 5-year retrospective of the State of AI (yes, we did review 934 slides 🙂). You can see the post in full here and the launch thread here.
Meetups: Our in-person community programming is back. We welcome builders and researchers for Munich AI on Tues 22 Feb 2024 (sign up) and Paris AI on Thurs 5 March 2024 (sign up). Stay tuned for NYC and SF events coming in April and May!
RAAIS: Sign-ups are now open for our annual Research and Applied AI Summit (RAAIS) on Fri 14 June 2024, which brings together 200 AI researchers, engineers, founders, and operators from around the world for a day of best practices and good vibes.
Air Street Press: We’re combining all of our content and community work under a single umbrella to make it easier to follow. While we’ll still maintain the separate Guide to AI feed, if you sign up to Air Street Press, you’ll receive all of our news, analysis, newsletters, reports, and events in one feed.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
The political and business elites of the world converged on Davos this January and AI was top of the mountain (agenda). The AI apocalypse had fallen down the agenda in favor of continuity and capabilities improvements. Indeed, we think this will be the trend for 2024 as the upside to AI technology progress wins more airtime than the existential safety agenda. Sam Altman, who made his WEF debut, said that while we could reach AGI in the “reasonably close-ish future”, it “will change the world much less than we think”.
Coinciding with the close of Davos, the UK Government published a framework for the application of GenAI in government, along with the results of the GOV.UK Chat beta - an attempt to use an OpenAI-powered chatbot to simplify interactions with online government services.
The chatbot trial results illustrate the unique challenges governments face when applying technology. High levels of trust in the GOV.UK brand meant users took any information provided on trust, even when it wasn’t accurate. While a disclaimer that information may not always be accurate is enough for the average Claude user, the margin for error vanishes when it comes to public services. As the Babylon Health (the direct to consumer doctor app that rose and imploded) story illustrates all too well that, when it comes to public services, beware of companies bearing simple chatbot solutions.
It’s been a busy start to the year for OpenAI. In the closing days of 2023, the New York Times announced that it was suing OpenAI. The NYT alleges that OpenAI infringed its copyright by using millions of articles to train its model, providing multiple examples of OpenAI models regurgitating NYT pieces verbatim. In its response, OpenAI claimed that regurgitation was a “rare bug” and accused the NYT of intentionally manipulating the prompts to achieve the desired outcome. It observed the ‘regurgitated’ pieces were years old and had been widely replicated on third-party sites.
Apple seems keen to avoid the litigation that a range of model providers are facing this year and is reportedly offering publishers contracts worth up to $50 million for access to their training data.
In other legal woes for big foundation model providers, as predicted in the 2023 State of AI Report, the US Federal Trade Commission has announced that it will be investigating recent investments and partnerships in not just OpenAI/Microsoft, but also involving Alphabet, Amazon, and Anthropic. This comes amid concerns about the rapprochement between labs working on frontier models, and the big tech companies providing them with significant levels of funding and cloud compute. The light cast on the OpenAI/Microsoft relationship during the abortive coup attempt at the end of last year likely did little to help matters. Large labs will continue to grapple with the challenge of demonstrating their independence while being entirely reliant on Big Tech’s financial and compute war chest.
Moving beyond the democratic world, it has been revealed that OpenAI, Anthropic, and Cohere held back-channel talks with Tsinghua University and other Chinese state-backed institutions in the run up to the UK’s AI Safety Summit. Convened with the knowledge of the US, UK, and Chinese governments, these talks focused on investment in safety and international standard-setting.
On the one hand, it’s possible to interpret the news as a welcome sign of international cooperation. At the same time, veteran China watchers might raise their eyebrows at the references from negotiators to AI aligning with the norms and values of each society. This turn of phrase is a common trope in official Chinese Communist Party rhetoric and is often read as an attempt to relativize human rights as a merely western ideal.
No (recent) Guide to AI would be complete without a brief trip to the world’s regulatory superpower. The EU AI Act finally cleared the legislative process, as France’s planned last stand against foundation model regulation collapsed, with all sides agreeing to horizontal transparency rules for all models, and additional obligations for higher risk models. This, of course, is not the end of the process. There will be extensive jostling over the exact ways in which the rules are interpreted. Many acts of secondary legislation will follow and seconded national experts running the AI new Office will surely stir the pot further.
That said, Brussels is continuing to make waves for technology companies without being granted new powers. Amazon announced that it was dropping its planned $1.4B acquisition of iRobot, the Roomba maker. This was due to concerns that it could lead to reduced competition in the robot vacuum cleaner market. Considering there is so much competition in the robot vacuum market that iRobot was somewhat reliant on fresh cash to stay alive, this strikes us as an odd decision. The EU blocking acquisition of one non-European company by another on spurious competition grounds reminds us of President Macron’s warning that Europe will end up in a position where it “will regulate things that we will no longer produce or invent”…
🍪 Hardware
After surprising new chip restrictions towards the end of 2023, China has suffered a fresh supply chain blow. At the start of January, ASML, the producer of extreme ultraviolet lithography machines, announced that it was canceling shipments to China. While new export restrictions were due to kick in weeks later, the Biden Administration upped the pressure behind the scenes. Based on similar moves with chip exports (where NVIDIA shipments would be blocked ahead of deadlines), this appears to be part of a wider strategy to disrupt stockpiling.
NVIDIA needn’t worry about losing any China business after Mark Zuckerberg announced that Meta was planning a major AI infrastructure push. Taking to Reels, he revealed that, by the end of 2023, Meta would be wielding an arsenal of 350,000 H100 graphics cards, along with “600k H100 equivalents of compute if you include other GPUs”. In an interview with The Verge, Zuckerberg said that: “We’ve come to this view that, in order to build the products that we want to build, we need to build for general intelligence.” Like Altman, Zuckerberg chose his words carefully when asked to describe AGI, saying that “I’m not actually sure that some specific threshold will feel that profound”.
Meta isn’t the only company on a chip-buying offensive. Bloomberg revealed the news that Sam Altman was on a push to raise billions of dollars to build a network of semiconductor factories. While Altman’s ambitions in the chipmaking space aren’t new, the potential range of partners has grown from G42 (facing fresh scrutiny over its China links) and Softbank to include Intel, Samsung, and TSMC. According to Bloomberg’s reporting, Microsoft’s interested in the plan as well.
While there is no shortage of projections showing a shortfall in AI chip production, a plan of this ambition will require tens of billions of dollars and years to implement, and the location of these fabs would no doubt run head-long into political sensitivities. There is, after all, a reason why most tech companies have avoided this kind of vertical integration in the past. But if it turns out that Altman’s right and the rest of the industry is wrong, in a chip-constrained world, it could prove to be the game-changer in the raging AI arms race. But let’s not forget just how insanely hard it is to design future-proof AI accelerators and make them a joy to use for developers, while competing against entrepreneurial incumbents such as NVIDIA.
We’ve been down on safety island in recent installments of this newsletter, but the UK received a boost when Google announced it was planning to build a new data center in Hertfordshire. This followed a similar announcement from Microsoft in December. With the Home Counties set to be buzzing with the sound of GPUs, maybe the UK still has some soft power after all…
Meanwhile, over on the highways of the Phoenix area, Waymo is making a world first. This product is truly amazing.
🏭 Big tech start-ups
After the run of model releases we saw at the end of last year, it’s been a quieter few weeks in LLM land.
Our friends at Adept AI have unveiled Fuyu-Heavy, the world’s third-most capable multimodal model - behind only GPT4-V and Gemini Ultra, which are 10-20 times larger. The model is able to beat models of a similar size on text-based tasks, despite having to devote capacity to image modeling. On multimodal reasoning, its primary strength, it scores higher on the MMMU benchmark than Gemini Pro. It’s exciting proof of Adept’s Fuyu architecture ability to handle different image shapes and sizes, reuse existing transformer optimizers, and to scale.
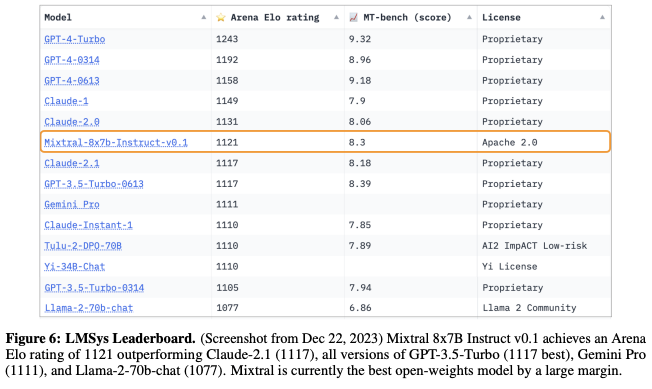
Meanwhile, following its legendary drop by magnet link, Mistral has published the Mixtral 8x7B paper on arXiv. It outlines how the sparse mixture of experts model is able to outperform Llama 2 70B on most benchmarks. The paper also presents Mixtral 8x7B - Instruct, which has been trained through supervised fine-tuning followed by Direct Preference Optimization to follow instructions carefully. Based on independent human evaluation, it’s the best-performing open weights model as of December 2023.
However, Mistral witnessed a touch of over-openness when an early version of a new model appeared on HuggingFace. After users noticed the ability of the mysterious “miqu-1-70b” to trounce much of the field against common LLM benchmarks, CEO Arthur Mensch confirmed that an early access customer had leaked an old Llama 2-based version of the model. Apparently rivaling GPT-4 performance on some counts, we can’t wait to see the real thing.
Pushing the frontiers of (actual) openness, the Allen Institute for AI unveiled their first Open Language Model (OLMo), released at 7B and 1B, along with its full training data, model weights, training code, metrics, inference code, evaluation and fine-tuning code. Their evaluation suggests it is competitive with Llama 2 across a range of tasks - with different strengths and weaknesses.
All these model releases cost a lot of money. Just six months after its $270M Series C, Cohere is rumored to be in talks for a funding round in the $500M - $1B range, more than it has raised across its four previous rounds combined. Few additional details are available at this stage.
Meanwhile, Elon Musk’s xAI is on a global fundraising drive, allegedly targeting sovereign wealth funds and family offices in the Middle East and Hong Kong. It is rumored that Musk may be seeking to raise as much as $6 billion. While the Middle East and China are logical destinations considering the volumes of capital required to build a viable OpenAI competitor, it risks touching a geopolitical third rail. The specter of US export controls, Hong Kong’s rapidly diminishing sovereignty, and China’s mercurial attitude towards western companies make this a high-risk, high-reward tightrope walk. Of course, when it comes to Elon, we’d expect nothing less…
Meanwhile, Google DeepMind is facing mutiny in the outer provinces, with researchers in both Paris and New York on the brink of unveiling breakaways. The Parisian crew, operating under the working title of Holistic, have allegedly been speaking to investors about a funding round in excess of €200M. On the other side of the Atlantic, three ex-DeepMinders are gearing up to launch Uncharted Labs, an image and music generation start-up, having raised $8.5 million out of a $10 million target. DeepMind’s retention levels remain healthy for the industry, but the several year-long trend of top researchers making a break for freedom shows no signs of slowing down. Rumor has it that these aren’t the only overseas DeepMinders working on new start-ups - watch this space…
Things are looking rosier elsewhere for big tech, with Microsoft and Meta both unveiling AI-heavy earnings. The former’s Azure cloud business grew by 30%, a fifth of which came from AI-related demand, while the company is projecting Copilot sales of $60 billion this quarter. Meanwhile, Mark Zuckerberg used the occasion of Meta’s healthy earnings to state his ambition that: “Everyone who uses our services will have a world-class AI assistant to help get things done, every creator will have an AI that their community can engage with, every business will have an AI that their customers can interact with to buy goods and get support, and every developer will have a state-of-the-art open source model to build with”
🔬Research
Shaping the future of advanced robotics, Google DeepMind.
While all eyes were on Gemini at the end of 2023, Google DeepMind has been slowly carving out a position as a world-leader in robotics research. DeepMind kicked off 2024 by publishing papers summarizing three new systems - AutoRT, SARA-RT, and RT-Trajectory - designed to enhance the efficiency, adaptability, and data collection capabilities of robots.
AutoRT is a system that combines large foundation models, such as an LLM or a Vision Language Model (VLM) with a robot control model to create a system that can deploy robots to perform diverse tasks in various settings. It uses a VLM to understand the robot's environment and the objects within sight, and an LLM to suggest a list of creative tasks that the robot could carry out. AutoRT also features safety guardrails, including a Robot Constitution, a set of safety rules inspired by Isaac Asimov’s Three Laws of Robotics.

SARA-RT, or Self-Adaptive Robust Attention for Robotics Transformers, is designed to make Transformer models more efficient, which is critical for faster decision-making. It employs a novel method for fine-tuning the model, which the researchers "up-training", to convert "quadratic complexity to mere linear complexity", thereby reducing the computational effort and increasing the speed of the model.
RT-Trajectory is a method that enhances robotic learning through video input. It uses coarse trajectory sketches for policy conditioning, which are used as task specification for an RT-1 policy backbone. For each episode in the dataset of demonstrations, a 2D trajectory of robot end-effector center points is extracted. This method is designed to improve robot movement accuracy in new situations and to extract knowledge from existing datasets.
The Operational Risks of AI in Large-Scale Biological Attacks: Results from a Red-Team Study, RAND Corporation. Biorisk is often called out by AI safety proponents as one of the major threat vectors that LLMs can exhibit. This work tasks researchers with role-playing as malign nonstate actors who want to plan a biological attack. The comparison is between teams with access to both an LLM and the internet and teams who only had access to the internet. The paper concludes that LLMs do not post a material biosafety risk: “Although the authors identified what they term unfortunate outputs from LLMs (in the form of problematic responses to prompts), these outputs generally mirror information readily available on the internet, suggesting that LLMs do not substantially increase the risks associated with biological weapon attack planning.” Relatedly, OpenAI published Building an early warning system for LLM-aided biological threat creation in which they compare how “biology experts and students” might use GPT-4 to create biological threats. They find that an “at most a mild uplift in biological threat creation accuracy.” Indeed, the result is far from being statistically significant, leading the researchers to conclude that “While this uplift is not large enough to be conclusive, our finding is a starting point for continued research and community deliberation.”
Mamba: Linear-Time Sequence Modeling with Selective State Spaces, CMU and Princeton. Published in December last year, this paper has received lots of interest and spawned several new derivatives. Mamba is a state space sequence model (SSM) for sequence modeling that presents an alternative to the Transformer and self-attention. This class of models can be computed very efficiently as either a recurrence (RNN) or convolution (CNN), with linear or near-linear scaling in sequence length. Mamba introduces an input data selection mechanism to allow the model to filter out irrelevant information and remember relevant information indefinitely. The Mamba model is a simple and homogenous architecture that combines the design of prior SSM architectures with the MLP block of Transformers into a single block. In particular, this confers Mamba much better performance on language tasks and GPU efficiency, resulting in 5x throughput on inference than Transformers. It also resolves the quadratic scaling problem of Transformers because Mamba scales linearly with sequence length (up to millions long). More recent work, such as MambaByte: Token-free Selective State Space Model, Cornell, does away with tokenizing input data and replaces this with an end-to-end mapping from raw data to predictions to give rise to a MambaByte that can operate on raw bytes. The results suggest that MambaByte is competitive with and even outperforms state-of-the-art subword Transformers.
Solving olympiad geometry without human demonstrations, Google DeepMind. Introduces AlphaGeometry, a neuro-symbolic theorem prover for Euclidean plane geometry. The methodology involves generating synthetic data to train a neural language model, which then guides a symbolic deduction engine through problem-solving. This approach bypasses the need for human demonstrations, which are costly and scarce, especially in geometry. AlphaGeometry synthesizes millions of theorems and proofs, with the neural model trained on 100 million synthetic examples. The system learns to generate new proof terms, a critical component missing in previous methods, enabling it to tackle Olympiad-level problems. The results show that AlphaGeometry solved 25 out of 30 recent Olympiad-level problems, surpassing the previous best method that solved only ten. Its performance is comparable to an average International Mathematical Olympiad gold medallist. The system also produced human-readable proofs, solved all geometry problems in the IMO 2000 and 2015, and discovered a generalized version of a translated IMO theorem from 2004.
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data, Bytedance. This paper presents Depth Anything, a monocular depth estimation model that exhibits strong generalization ability to unseen datasets without any fine-tuning. The key to their approach is scaling up the training data to 62 million diverse unlabeled images from multiple sources. To effectively leverage these unlabeled images, they use an initial teacher model to assign pseudo-labels, and train a student model to not just reproduce the pseudo-labels but to seek extra visual knowledge under strong perturbations like color/spatial distortions. Further, they align the student model's features with a frozen semantic encoder to inherit rich semantic priors. Without using common depth estimation datasets like NYUv2 and KITTI for training, their model outperforms prior state-of-the-art models like MiDaS across multiple test datasets. When fine-tuned on NYUv2 and KITTI, it establishes new state-of-the-art results. Their encoder also transfers well to semantic segmentation.
Towards Conversational Diagnostic AI, Google Research and Google DeepMind. Extending their Med-PaLM (family) of works, the team built an LLM-based system called Articulate Medical Intelligence Explorer (AIME) that is optimized for physician-patient dialogue. AIME is trained in a simulated environment in which it learns through self-play with automated feedback mechanisms across different disease conditions, specialities and contexts (inspired by AlphaGo). In the words of final author Vivek Natarajan (who presented his team’s Med-PaLM work at our RAAIS conference last year), “In a randomized, double blinded study of text consultations with validated patient actors in the style of objective structured clinical examination (OSCE), AMIE outperformed board-certified primary care physicians (PCPs) on multiple evaluation axes for diagnostic dialogue (52 of 58 axes while being non-inferior on the rest). Perhaps excitingly, AMIE surpassed PCPs not only on aspects pertaining to diagnosis but also those related to communication, relationship fostering and rapport building with the patient (suggesting such AI systems may help us scale empathy).”
Also on our radar:
Biochemical-free enrichment or depletion of RNA classes in real-time during direct RNA sequencing with RISER, Australian National University. Introduces RISER, which uses deep learning to streamline RNA sequencing, by enriching or depleting specific RNA types in real-time, bypassing the need for complex biochemical methods. It can operate with just a CPU, making it faster and more accessible than traditional methods.
DrugAssist: A Large Language Model for Molecule Optimization, Tencent. Introduces DrugAssist, an interactive model for molecular optimization, a crucial task in drug discovery, via human-machine dialogue. Leveraging the interactivity and generalizability of LLMs, DrugAssist outperformed traditional molecular optimization approaches in single and multiple property optimization.
Towards Joint Sequence-Structure Generation of Nucleic Acid and Protein Complexes with SE(3)-Discrete Diffusion, Profluent. Introduces MMDIFF, a generative model that designs sequences and structures of nucleic acid and protein complexes using joint SE(3)-discrete diffusion noise. This model is designed to address the limitations of existing methods that model protein structures or sequences without considering the interactions between proteins and other macromolecules
Instruct-Imagen: Image Generation with Multi-modal Instruction, Google DeepMind, Google Research. Introduces Instruct-Imagen, a vision-language model that can effectively merge diverse inputs like sketches and visual styles with textual directives to produce contextually accurate and compelling images. They achieve this by continuing the training of a pre-trained diffusion model with additional image and text contexts, and fine-tuning it on diverse image generation tasks.
VideoPoet: A Large Language Model for Zero-Shot Video Generation, Google Research. Introduces VideoPoet, a model developed for zero-shot video generation, which employs a decode-only transformer architecture to process multimodal inputs. Achieves state-of-the-art performance, particularly excelling in high-fidelity motions and supporting a wide range of video generation tasks, including text-to-video, image-to-video, video stylization, inpainting, outpainting, and video-to-audio.
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws, MosaicML. Proposes modifications to DeepMind Chinchilla's scaling laws, which they believe neglect to include the cost of inference. They suggest that LLM researchers expecting a large inference demand should train smaller models for longer than than the Chinchilla-optimal.
💰Startups
🚀 Funding highlight reel
1X, a start-up building humanoid robots to address labor shortages, raised a €91M Series B led by EQT Ventures.
CellVoyant, a start-up using AI to accelerate the development of novel stem cell therapies, raised a £7.6M seed round, led by Octopus Ventures.
Chalk, building developer infrastructure for GenAI, raised a $10M seed round, led by Xfund, Unusual Ventures, and General Catalyst.
DataSnipper, applying AI to audit and data reconciliation, raised a $100M Series B, led by Index Ventures.
Distributional, building an enterprise platform for AI testing and evaluation, raised a $11 million seed round, led by a16z.
Eleven Labs, the two-year old AI voice company, raised $80M at a $1.1B valuation.
Essential AI, using LLMs to automate repetitive work, raised a $56.5M Series A led by March Capital.
GreyOrange, a start-up developing AI-powered software and robots for warehouse automation, raised a $135M Series D led by Anthelion Capital.
Harvey, building a GenAI platform for professional services firms, raised an $80M Series B led by Kleiner Perkins and Elad Gil.
Lightmatter, the company changing chip architecture with photonic processors, raised a $155M Series C led by Viking Global Investors and Google Ventures.
Luma AI, the GenAI start-up 3D models from text descriptions, raised a $43M Series B led by a16z.
Mercor, the AI-powered hiring platform, raised a $3.6M seed led by General Catalyst.
Nabla, developing a copilot for clinicians, raised a €22M Series B led by Cathay Innovation.
Norm AI, building an AI-powered platform for compliance, raised an $11M seed, led by Coatue Management.
Nous Research, an applied research group focused on LLM architecture, raised a $5.2M seed led by Distributed Capital and OSS Global.
Perplexity, building an AI-powered conversational search engine, raised a $74M Series B led by IVP.
Quora, the social Q&A site and creator of AI chat platform Poe, raised $75M from a16z.
Rabbit, building a custom operating system using a natural language interface, raised an additional $10M from Khosla Ventures, following an earlier $20M Series A.
Shield AI, the manufacturer of autonomous drones and aircraft for defense, expanded its Series F to $500M, with an additional $300M in equity and debt.
Tacto, applying AI to industrial procurement, raised a €50M Series A led by Sequoia Capital and Index Ventures.
TextQL, a start-up working on enterprise data analysis, raised a $4.1M seed round, led by Neo and DCM.
Sierra, another enterprise AI focused newco (this time founded by former co-CEO of Salesforce, Bret Taylor), is rumored to have raised capital at a unicorn valuation (already).
🤝 Exits
Claypot AI, the start-up working on real-time data processing for AI, was acquired by Voltron Data.
Kwest, the start-up using AI to speed up the installation of energy infrastructure, was acquired by Kraken, the tech arm of Octopus Energy.
---
Signing off,
Nathan Benaich and Alex Chalmers 4 February 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | London.AI
Air Street Capital invests in AI-first technology and life science entrepreneurs from the very beginning of your company-building journey.
