


Hi all!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering key developments in AI research, industry, geopolitics and startups during October 2022. Before we kick off, a couple of news items from us :-)
The enthusiasm (and hype) of generative AI is in fifth gear. I joined Eric Newcomer on the Dead Cat podcast to explore what will happen next and where to invest.
Ian and I discussed the importance of AI safety with Parmy at Bloomberg who threaded the topic in this article.
I spoke to the second order opportunities of foundation models with Will at WIRED.
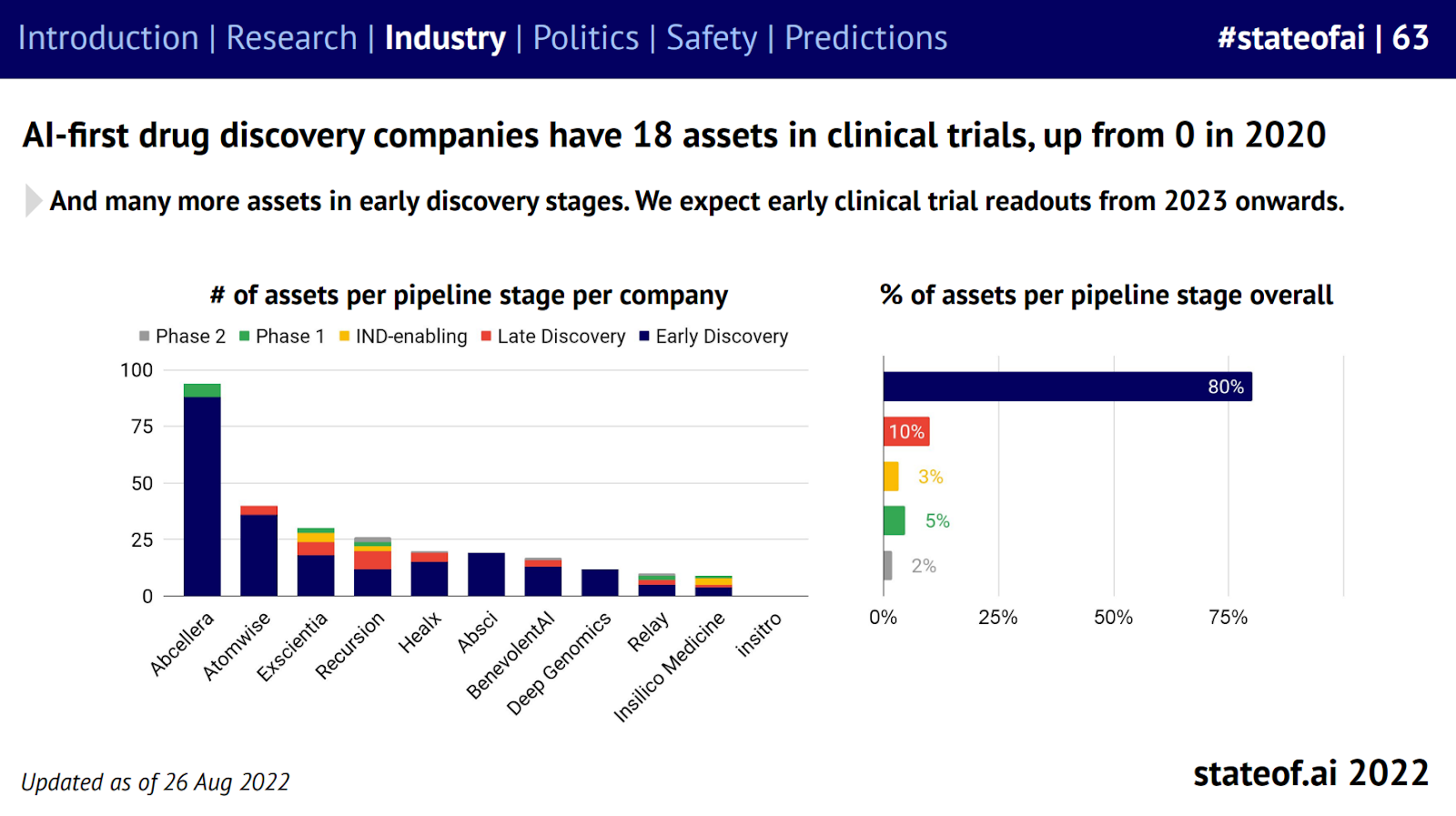
I shared a vignette on AI-first bio and how large models have learned the language of medicines and proteins with Mario at The Generalist.
As usual, we love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🧬 Life sciences
More AI-first protein engineering! A team at MetaAI used a protein language model called ESM to predict the 3D structures of 617 million metagenomic proteins directly from their primary amino acid sequences. Of those, more than a third are deemed to be of high quality, meaning that scientists can trust the structure predictions as almost ground truth in their experiments. Not only is the resulting ESM Metagenomic Atlas available to consult for anyone at https://esmatlas.com/ but they’ve also opened an API to predict the structure of proteins using ESM. This is a huge step after AlphaFold 2. Under the radar, Meta has actually been one of the pioneers of Protein Language Modeling. Their ESM language model, whose first version came out in April 2019 and was open-sourced in November 2020, predated DeepMind’s AlphaFold 2, and was the first to use a transformer-based protein language model.

Further expanding its platform capabilities, Exscientia announced its entry into biologics (protein-based medicines such as antibodies) by making use of generative design, simulation and a new high-throughout experimentation facility.
Verge Genomics, an AI-powered drug discovery platform, announced that it had begun its clinical trial. The drug, named VRG50635, targets a neurodegenerative disease with no known cure called ALS. This grows our count in the State of AI Report of assets in clinical trials to 19. Verge Genomics joins the likes of Abcellera, Exscientia, Recursion, etc. We’ll still need a year or two for early efficacy readouts of AI-designed drugs in clinical trials.
🌎 Geopolitics of AI
In perhaps the most important geopolitical AI news to date, the US has blocked the export of high-end AI chips to any entity operating in China, “whether that is the Chinese military, a Chinese tech company, or even a U.S. company operating a data center in China.” This is especially relevant with regards to NVIDIA, whose chips represent 95% of AI chip sales in China. This is the case not only because of its hardware, but also because of NVIDIA’s world leading CUDA software. But to make these export limitations viable without quickly boosting China’s AI chips innovation and internal chip market, the Biden administration is also blocking access to chip design software and US-built semiconductor manufacturing equipment and components. Coupled with the $250B CHIPS Act, which offers financial incentives for chip design and manufacturing companies to build in America so long as they do not grow business in China, the US has gotten extremely serious in its bid for technology sovereignty.
The White House introduced a Bill of Rights for AI systems. This is a list of rights that the federal government will respect when building and deploying AI systems. The hope is that such a bill can be extended in time to federal agencies, researchers, and the industry as a whole. These rights all seem natural and shouldn’t come as a surprise to anyone who has skimmed through the European AI act. For example, they include: The systems should be safe and effective; they should come with protections from algorithmic Discrimination and from abusive data practices; one should know if and how they’re interacting with an AI system; and when appropriate, one should be able to opt out from its use.
🍪 Hardware
On the autonomous vehicles front, Argo AI is shutting down. The company had raised $3.6B mainly from Ford and Volkswagen. Like the entire sector, Argo AI fell behind on its predictions to bring self-driving cars to the market by 2021. The company had already announced last July that it laid off 5% of its workforce and that it would slow down hiring. But, as losses kept on accumulating and new investment wasn’t available, Argo’s had no choice but to cease operating. TuSimple (the US-based self-driving trucks company) is also in a delicate position but its story isn’t as classical: the company is being investigated in the US for failing to disclose that it had incubated the Chinese startup Hydron, to which it transferred technology and provided funding. Meanwhile, Intel-owned Mobileye successfully IPO’d. Intel bought Mobileye at $15.3B in 2017 and it is now valued at ~$20B, a hefty figure but far below initial expectations. Meanwhile, Wayve demonstrated an exciting industry first: a driving AI that can both generalize to new, previously unseen cities and generalize across two very different vehicle platforms (passenger vehicle and a delivery van).
In the context of tensions between the West and China on chip manufacturing and supply, the German government came under the spotlight for backing the sale of an Elmos wafer fab to Silex, a 100%-owned subsidiary of Sai Microelectronics, a Chinese company.
According to Dylan Patel’s analysis of Qualcomm’s counterclaim in an Arm-Qualcomm lawsuit, Arm is changing its licensing rules. In particular, Arm will only license their CPUs design directly to device-makers and will forbid semiconductor manufacturers from selling Arm processors that Arm itself will offer as part of a broad license. Don’t worry though, NVIDIA has a 20-year Arm license secured, so your hardware should be OK.
🏭 Big tech and the generative AI frenzy
Google announced that Imagen, its text-to-image model, was coming to AI test kitchen, joining Google’s chatbot LaMDA. AI test kitchen is an app that allows users to explore AI demos for Google products. This will allow more people to test Imagen and compare it to other available text-to-image models like Stability.AI, Midjourney, or DALL-E 2.
Speaking of DALL-E 2, Microsoft introduced DALL-E 2-based Microsoft Designer, an application that allows users to generate new designs from textual prompts. This, in addition to Github Copilot, shows that Microsoft has been relatively quick in integrating and deploying new AI models, thereby making the most of its investment in OpenAI. Microsoft is reported to be in talks to invest more into OpenAI.
Investments are indeed pouring into generative AI, as this subset of AI is gaining momentum in the general press (see NYT’s article titles A Coming-Out Party for Generative A.I., Silicon Valley’s New Craze). The most notable financing round came from Stability.AI, the company behind the AI community’s beloved open-source Stable Diffusion model. The company raised $101M led by Coatue and Lightspeed. Jasper.AI also raised a huge round, with a $125M Series A at a $1.5B valuation. The company famously generates content using OpenAI’s GPT-3 (and makes more $$$ than OpenAI – see Nathan’s thread ;))
Ironically, amid the generative AI frenzy, Google has apparently pushed a new spam update that was shown in an experiment to push SEO traffic of AI-generated content by 17.29% on average.
Moving away from text-to-image and into code, the BigCode project (think BigScience, but for code) gave birth to The Stack, a 3.1TB dataset of source code in 30 programming languages. This promises to make programming language models a bit more accessible to researchers.
🔬Research
Mind’s Eye: Grounded Language Model Reasoning Through Simulation. Google. Large Language Models (LLMs) have been able to gather considerable knowledge of the real-world by training on gigantic amounts of textual data. But as they often fail in real-world reasoning tasks, LMs too need actual practice. So to make them better reason about the real world, Google researchers augmented the LM input with the results of simulations of the situation they need to reason about. Concretely, to answer “which of two baseballs of different weights and the same acceleration will fall faster to the ground”: a text-to-code model translates the question into a program that launches simulations on the Mujoco physical engine; then, the model uses the result of the simulation as a physical ground truth to ultimately give a textual answer to the question. With this simulation-augmented input, they show not only large improvements for LLMs on physical reasoning tasks, but also that small augmented-LMs can perform better than 100x larger vanilla LMs. Another article which is relatively close in spirit (though geared towards robotics) is Code as Policies: Language Model Programs for Embodied Control from Google, where an LM for code is trained to write robot policy code.
Language Models of Code are Few-Shot Commonsense Learners, Carnegie Mellon University, Inspired Cognition. A common way to evaluate models’ reasoning abilities is to generate reasoning-graphs. These structures are indeed ideally suited to represent logical reasoning steps. Recently, this problem (and indeed increasingly almost all problems in ML) has been tackled by using a natural language model on a flat representation of the graph. Here, researchers from CMU rather convert the training graph into python code, then train a code generation language model on the code representation of the graph. They show that this allows them to generate more accurate reasoning graphs (after they are converted back from code).
Scaling laws are empirical laws that predict the performance of a machine learning model depending on its parameter count, size of training data, or amount of compute, which give practitioners rough guidelines on model and data scaling choices. Papers from DeepMind, Anthropic, and OpenAI among others have studied scaling laws for supervised and self-supervised language and vision models. The interest in deriving scaling laws continues to grow:
Scaling Laws for a Multi-Agent Reinforcement Learning Model, Goethe University. A large-scale study of scaling laws for RL models has been lacking. This paper considers the performance of DeepMind’s AlphaZero on two games: Connect Four and Pentago. They observe the same scaling laws for both, which are also similar to those of LLMs: these are power laws with roughly the same exponents for both games. Applying their scaling law, they conclude that AlphaZero and AlphaGo Zero both would have benefited from using larger neural networks.
How Much Data Are Augmentations Worth? An Investigation into Scaling Laws, Invariance, and Implicit Regularization, University of Maryland, New York University. Among other things, this paper examines scaling laws for data augmentation. They examine the effect of different data augmentation levels on performance and show again a power-law scaling. Interestingly, they show that “the impact of augmentations is linked to dataset size; diverse but inconsistent augmentations [(e.g. adding random images)] provide large gains for smaller sizes but are hindrances at scale [compared to, e.g., consistent random flips]”.
Mastering The Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning. Meta AI, MIT. Self-play Reinforcement Learning has been successfully applied to two-player zero-sum games like chess, Go, and poker. An RL agent designed by OpenAI was even able to beat humans at Dota, a two-team zero sum game that involved cooperation between bots of the same team. Meta AI and MIT now brought this a level further by enabling bots to cooperate with humans in No-Press Diplomacy, a game involving cooperation where only part of the information is available to team members. The researchers improved a model they had recently introduced, which goes beyond pure self-play and models human behavior based on human data. The resulting agent, called Diplodocus, helped six humans achieve the top 2 average scores among 48 participants to a No-Press Diplomacy tournament.
Speech-to-speech translation for a real-world unwritten language, Meta AI. This work from Meta is a good example of several existing innovations coming together to enable a previously impossible feat. In this case: speech-to-speech translation of Hokkien, a primarily oral widely spoken language in the Chinese diaspora. The main challenge is the scarcity of Hokkien<->English data and translators. The first trick was to use a close proxy language, Mandarin, to build pseudo-labels for Hokkien speech. The second was using a speech encoder to encode a fixed representation of Hokkien – that lives in the same space as English representations – directly from speech. Finally, translating from and to Hokkien is probably the best illustration of the work Meta has been pioneering in speech-to-unit translation (S2UT), where speech is translated directly into acoustic units. The researchers used S2UT on top of the Mandarin-generated texts.
What Makes Convolutional Models Great on Long Sequence Modeling? UIUC, Princeton, Microsoft Research. In the July edition of this newsletter, we covered a few methods dedicated to long sequence modeling. The release of this paper on how CNNs do an excellent job on long sequences is the occasion to highlight a recent line of work which has been cracking the challenging long-range arena benchmark: these are methods that have made the classical state-space model more memory and computationally efficient and that are able to solve a 16k length task that all previous models failed on (including transformers and their efficient variants). These include for example S4, Liquid-S4, and S5. If you want to go into a bit more detail without reading the paper, read this thread from Davis Blalock, and the replies from Albert Gu, S4’s first author.
Large Language Models Can Self-Improve, Google. In this paper, researchers use chain-of-thought prompting (adding logical examples as a prompt the LM) and majority voting to generate labels for unlabeled datasets using their 540B-parameter LM (PaLM). They then train PaLM on these same datasets with the model’s own generated labels. This is good old self-training modernized with new language models tricks. And it does a great job on several datasets, improving GSM8K, DROP, OpenBookQA, and ANLI-A3 by 4.5 to 7.6 percentage points.
💰Startup rounds
Jasper, a startup using OpenAI’s GPT-3 to generate content, raised a $125M Series A at a $1.5B valuation, led by Insight Partners.
Generally Intelligent, a new AGI company backed by a who’s who of AI researchers and CEOs, attracted funding worth up to $120M.
The startup behind Stable Diffusion, Stability.AI, raised $101M led by Coatue and Lightspeed Venture Partners. The company advocates for truly open-source AI research and positions itself as a competitor to OpenAI and other top corporate AI labs.
Altana, which uses AI for supply chain management, raised a $100M Series B led by Activate Capital.
Avidbots, which sells a fully autonomous robot-cleaner, raised a $70M Series C led by Jeneration Capital.
Axelara, an AI chip company, raised a $27M Series A led by Imex.xpand.
Orum, one of many startups pursuing the AI sales assistants market, raised a $22M Series B led by Tribe Capital.
Navina, which makes AI-based software to help clinicians with data management, raised a $22M Series B led by ALIVE.
Taiwanese startup Neuchips, which builds AI accelerators, raised a $20M round led by Wistron, JAFCO Asia, and Powerchip Group.
MLOps company Galileo raised a $18M series A led by Battery Ventures
Insite AI, a company that uses AI to advise consumer goods companies on how to locate and promote their products in physical stores, raised a $19M Series A led by NewRoad Capital and M12.
LatticeFlow, an ETH spinout whose founding team includes Andreas Krause, the Chair of the ETH AI center, raised a $12M Series A led by Atlantic Bridge and OpenOcean. The company uses machine learning edge cases and blind spots in ML models development and data in order to make ML models more robust in production.
NumberOne AI, which uses an “automated AI/ML platform to the challenge of starting and launching new company ventures”, raised a $13M round.
Rewind, a startup building a tool that allows user to record, compress, and search into everything they have ever done on their Mac, raised a $10M round at a $75M valuation led by Andreessen Horowitz.
Gather AI, a company that uses drones to help with inventory, raised a $10M Series A led by Tribeca Venture Partners.
Recursion, the clinical-stage AI-first drug discovery company listed on the Nasdaq, completed a $150m private placement led by Kinnevik.
Exits
Mobileye, the Intel-owned Israeli automotive technology and autonomy company, was spun off and taken public on the NASDAQ.
Oterlu, the Swedish AI-first content moderation startup, was acquired by Reddit.
Alter (fka Facemoji), the avatar company for game developers, was acquired by Google for a reported $100m.
---
Signing off,
Othmane Sebbouh and Nathan Benaich, 6 November 2022
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | London.AI
Air Street Capital is a venture capital firm investing in AI-first technology and life science companies. We’re an experienced team of investors and founders based in Europe and the US with a shared passion for working with entrepreneurs from the very beginning of their company-building journey.