




Prefer audio? Listen to this article here.
Introduction
The generative AI copyright wars took a new turn recently, when the Recording Industry Association of America (RIAA) announced that it was suing music generation services Suno and Udio for massive infringement of copyright. The lawsuit alleges the systematic unauthorized use of copyrighted works to train the two companies’ models and points to how some of their output either closely resembles or directly copies various iconic songs.
Back in April, Ed Newton-Rex, the former composer and Stability executive turned founder of Fairly Trained, found something similar when he used the lyrics of well-known songs as prompts.
These actions are just the latest in an avalanche. These include:
The New York Times suing OpenAI, arguing that ChatGPT had parroted its articles;
Getty Images suing Stability AI, pointing to the appearance of its watermark in some of Stable Diffusion’s output;
A group of visual artists are suing Stability and Midjourney, Runway, and Deviantart for misuse of their work;
Groups of fiction and nonfiction authors suing Meta and OpenAI for the use of their books.
A group of record labels are alleging Anthropic removed copyright management information from lyrics and used them to train Claude.
Perplexity is facing mounting scrutiny over alleged scraping of data and the specifics of some of its data collection practices.
Neither of us are lawyers and we don’t plan to argue the rights and wrongs of the AI copyright wars. We can see the logic of both sides' positions, understand the strength, and are glad that the courts are approaching some of the weaker arguments with appropriate skepticism.
We believe that history suggests that some kind of compromise is likely to be forced on this debate, if not by the courts, then by politics. Without taking a position on fair use arguments, we ultimately believe that copyright will prove to be a futile hill for the industry to die on. Based on how cases so far have progressed, total victory looks increasingly unlikely, so model builders should begin to invest their energies into working out the best possible shape for a compromise. At the same, artists and industry bodies will need to be careful not to hit back with unreasonable asks. Given how much of a bottleneck data acquisition can be for founders, it’s important for all concerned that cooler heads prevail and a reasonable settlement is found.
Compromise and overreach
As long as a modern technology industry has existed, there have been copyright disputes.
One of the most notorious, appropriately enough, concerns music rights. Few need an introduction to Napster, the P2P file sharing platform that was primarily used for distributing music for free. At its peak, the service had approximately 80 million users. Unsurprisingly, the company was far from popular among record labels and within a year of its founding in 1999, Napster was sued by 18 members of the RIAA. Napster’s fair use defense failed to persuade the courts, as did its argument that it could not distinguish between legally and illegally uploaded files.

Napster’s defeat led to the business shuttering in 2002, but it still changed the music industry. The company inspired a burst of other P2P sites and it was impossible for record labels to tackle them all simultaneously. Attempts by labels to lock CDs or watermark music files made little difference. Napster had also fuelled consumer appetite for singles over albums.
This meant that when Steve Jobs proposed the concept of iTunes, giving consumers legal certainty and labels compensation, the industry cooperated. Music consumption was transformed overnight.
This is not to say that the industry and Apple became best friends. There were years of feuding over pricing, which was eventually settled by compromise. Record labels continued to push for more, even demanding a cut of iPod revenue - an argument Apple felt comfortable dismissing out of hand.

These trends cut both ways. When one side over-presses in these disputes, it can result in near total defeat.
We saw this dynamic play out in the case of Google Books.
Google launched the service in 2002, which digitized large volumes of books and made them searchable. While Google scanned entire books, it only provided previews or snippet views of copyrighted works. In 2005, Google was hit by lawsuits from the Authors Guild of America, several individual authors, and the Association of America Publishers. Google had a relatively easy ‘fair use’ defense in the case, given it was hard to argue convincingly that short book snippets constitute a market substitute for entire copyrighted works. Nevertheless, looking for a quiet life and legal certainty, the company decided to pay off its opponents. In that spirit, it reached a settlement with the litigants, which included a $125M payment to affected authors, the introduction of an opt-out system, and a revenue share scheme with authors and publishers.
While the litigants were broadly happy, other authors’ societies were not. The settlement agreement came under such extensive criticism that it was withdrawn. Following some more legal twists and turns, the case went to trial and Google won a complete victory. Subsequent appeals were all denied. Rather than take the good result they’d won with a … frankly shaky hand, authors and publishers overpressed and came away with nothing.
The balance between compromise and overreach plays out beyond copyright. In the ride-sharing world, this exact pattern ended up playing out in Uber’s two main areas of legal difficulty - licensing and employment status. These have been gradually resolved via local compromises, while its opponents overpressed.
In the early days of the company, taxi unions and their political supporters repeatedly called for the service to be banned outright. They argued that hiring taxis via app was illegal, and demanded that the company employ its drivers directly. Under its original leadership, Uber adopted an aggressive stance on these questions, believing it could magic away legal obstacles through a combination of ignoring them, expensive lawyers and wielding their popularity with consumers as a political weapon. This approach won them temporary reprieves, but little more.

Dara Khosrowshahi’s more conciliatory approach yielded significantly better results. The company managed to secure its first ever long-term license in London where it preserved its booking system while upping safety standards, passed an advantageous employment compromise in California via Proposition 22 and steered a middle-way through UK employment law.
While the company still faces regulatory challenges, it has largely resolved the existential questions about its future. Uber’s early aggression levels matched those displayed by its opponents in the traditional taxi industry. However, unlike the company, they failed to learn and largely clung to their original maximalist position (banning Uber), which guaranteed increasing irrelevance as they diverged from public and political opinion.
In the unlikely event that AI model builders emerge unscathed from the legal process and escape ‘hard’ constraints imposed by the courts, they would then have to negotiate these kinds of ‘soft’ political constraints. While some in tech point to their diminishing reader numbers, news publishers continue to wield elite-level political influence and are bad enemies to have.
This is why, for example, Google reached a financial agreement with News International around the featuring of stories from their publications in the Google News showcase. No doubt many at Google resented the apparent shakedown, the company made the calculation that the cost was lower than continued unrelenting hostility from one of the world’s most powerful news publishers. Throw into the mix, large numbers of popular authors and entertainers and companies risk finding themselves on the political backfoot pretty quickly. Expect copyright to be added to the other sticks used to beat model builders (fairly or unfairly), such as misinformation, future of work, or safety.
Avoiding the courts
It’s tempting to argue that companies should just take their chance in the courts - they’re deep-pocketed, they might win, and can worry about political challenges further down the road. But this neglects how companies that have avoided this route have yielded significant upside.
It is usually much easier to reach an equitable or advantageous deal with someone if you haven’t just lost to them in court. Your bargaining power is greater and good will levels are likely to be higher.
Many people forget that Napster didn’t die immediately after its legal troubles. It attempted to relaunch in a compliant way, charging users $5-10 a month to download a fixed number of songs. As well as having to compete with the tide of free music it had helped to propagate, Napster found that many of the record labels it had fought against in court weren’t particularly keen to strike licensing deals with it. Things got so bad that the company tried to lobby Congress to create a universal compulsory license for music. The relaunch failed within a year. Apple, without this baggage, did not face the same struggles.
By contrast, when YouTube began being hit with lawsuits in 2007 over claims that it had failed to take adequate steps to prevent copyright infringement, it acted quickly. The company quickly unveiled its Content ID system, which used digital fingerprints of songs or videos to trace unauthorized uploads.
Copyright owners then have the option to either block the content, monetize it by placing ads against it, or track viewership statistics. Not only did this head off most (if not all) of YouTube’s legal troubles at the pass, it meant that copyright holders have been able to make billions of dollars from content, while Google was able to take its cut. While record labels have complained about the royalty rate, these disputes have been settled via bespoke agreements rather than legal battles.
A future settlement?
We’re already seeing evidence that the AI industry is taking this on board. OpenAI has started pursuing licensing deals with major global publishers such as News Corp, Axel Springer, the Financial Times, and Associated Press. Meanwhile, Reddit and Google have reached a content licensing deal.
The upfront license fee is only one potential model and comes with challenges. Firstly, a big upfront payment isn’t always accessible for earlier stage businesses. Secondly, given the relative nascency of generative AI technology, it’s hard to predict exactly how much value model builders will gain from much of this data - so any price tag is, at best, a guesstimate. That’s why Ed Newton-Rex favors a revenue sharing approach.
Executing either approach will require a major cultural shift at AI labs, as well as significantly greater record-keeping around training data and an end to the practice of deleting datasets after training. It’s also true that this would likely make it more expensive to drive up costs for some businesses (no, this doesn’t mean it’s regulatory capture). It’s always cheaper to start a business if one of your major inputs is free, but startup costs aren’t the only metric for assessing the merits of a policy. If they were, it would also make sense to repeal all environmental protections, employment rights, and product safety regulation.
There are certain ways of mitigating this.
Instead of start-ups paying more and more to the big model builders that hold licenses, they could approach data providers directly.
We could see a world in which start-ups or investors pool resources to negotiate fair licensing terms. Alternatively, corporates or universities may embrace tiered licensing models so start-ups can access data at a significantly lower rate or for free, via a partnership model. You could equally see start-ups bypass the big model builders and approach data-holders to licence data for RAG, cutting out the middle man.
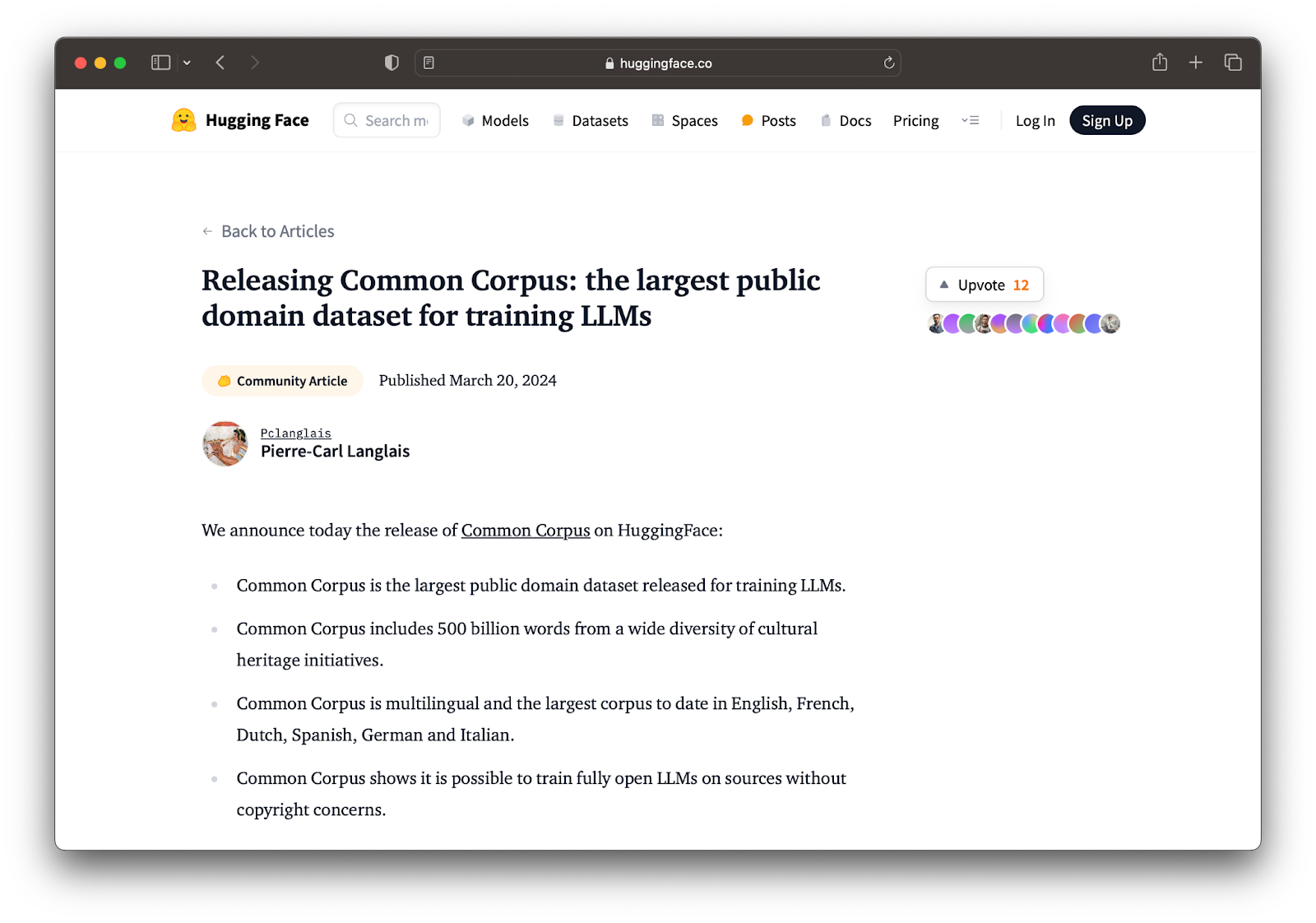
The community can also play a role. Hugging Face has created Cosmopedia, a huge open synthetic dataset, while Pleias coordinated Common Corpus, a 500 billion word multilingual dataset compiled using only public domain material.
Closing thoughts
As optimists about the power of technology, we believe that AI-first companies will take on critically important social and economic roles in the coming years. They will attract their share of critics and detractors, and will face pushback from incumbents with vested interests. There will also be greater and greater public scrutiny and concern.
In this field, it will be important for the industry to pick its battles carefully. Even with the best will in the world, it is not possible to take on and win every political fight all of the time. For example, there is potentially much more destructive legislation headed down the line around model capabilities and ‘safety’.
We have tried to avoid taking a philosophical stance on ‘fair use’ and instead focus on the practical questions. Looking at this through a purely analytical lens, this seems like a fight which the industry has a good chance of losing legally and an even better one politically. Its arguments, regardless of their validity, are difficult to explain and counterintuitive in their most sophisticated form. In their less sophisticated forms, they sound disingenuous.
If we work backwards from their stated policy positions, some of our fellow techno-optimists appear to believe that AI will simultaneously develop awesome capabilities while having little social or economic impact. (“The line will on the graph will get higher, but the creative industries will be fine, or if they’re not, they deserve it.”)
This strikes us as a courageous but unsustainable position. Some kind of new social contract will have to emerge. Companies can embrace it, or have it enforced on them.
The historical parallels were well executed in support of the argument. Nice work.