

Dreaming in latent space
Sereact's Cortex 2.0 and world-model planning in real-world robotics


Learning before acting
A warehouse robot that worked perfectly yesterday is given a new returns workflow today. The boxes are slightly larger. The packing material is different. The lighting in this aisle is dimmer. No new training run is scheduled.
In robotics, the hard problem is no longer solving a single manipulation task under ideal conditions. It is handling small, relentless variation without brittle retraining. Modern Vision-Language-Action (VLA) systems can perform impressively in controlled setups, but they remain reactive at their core. They observe the scene and select the next action given a goal. For short-horizon tasks, that works.
The trouble begins when actions interact across time. A grasp that technically succeeds may create a collision two steps later. A slightly unstable placement can trigger a recovery loop that costs thirty seconds. Reactive policies often repeat near-miss actions because nothing in their internal state marks a trajectory as fundamentally flawed rather than temporarily unlucky.
In our previous essay on Cortex 1.6, we described how robots can improve by learning from execution itself, drawing signal from how tasks unfold rather than simply whether they succeed. That made systems more robust after mistakes occurred.
With Cortex 2.0, Sereact pushes the idea further upstream. Instead of learning only from what happened, the system evaluates possible futures before committing motion, generating and scoring imagined continuations of the scene to avoid unstable trajectories in the first place.
Plan, imagine, then execute
Instead of immediately choosing an action, Cortex 2.0 generates several imagined continuations of the scene in visual latent space. These are short predicted futures, each corresponding to a different plausible sequence of movements.
Those imagined futures are scored using the reward logic introduced in Cortex 1.6. The model estimates progress toward the goal, risk of instability or collision, and expected smoothness. Only the highest-scoring candidate shapes the execution policy.
The reactive controller remains, running at high frequency to make fine motor corrections. But it is no longer acting blindly. Its movements are influenced by trajectories that already look stable. In the video below, we depict the Cortex 2.0 architecture, which now includes a world model generating candidate futures, PRO scoring, and execution conditioning. The shift is subtle but material. The system no longer treats every next action as equally plausible. It favors futures that look coherent before instability appears.
Why visual prediction?
Planning in visual latent space is pragmatic. Images encode geometry, contact, and occlusion in a representation that transfers across hardware platforms. A box and its contents look similar regardless of the arm that manipulates them. Planning in joint space would bind reasoning to specific kinematics.
But let’s not forget that latent predictions are imperfect. A world model can generate futures that look plausible but diverge from real dynamics. Cortex 2.0 mitigates this by training on real production data rather than simulation, grounding predictions in warehouse interactions. Rollouts are short and continuously corrected by the reactive controller, limiting error accumulation. Each deployment produces prediction-versus-reality comparisons, tightening alignment over time.
How much thinking is enough?
Cortex 2.0 does not fix the amount of planning. The parameter K controls how many candidate futures are generated per decision. As K increases, success rates rise, as does latency.
In evaluations, K is set to 2 to balance foresight and throughput. For high-stakes manipulations, one can use more planning, while for low-risk tasks we can afford to use less planning. In this way, the robot has an explicit task-specific thinking budget.
Benchmarking Cortex 2.0
In the multi-step shoebox manipulation task, Cortex 2.0 completes the full sequence - opening the box, removing packing material, and extracting both shoes - with a 95% success rate, dramatically higher success than open-source baselines, completing the task reliably end-to-end without human intervention while other methods frequently stall or fail entirely.
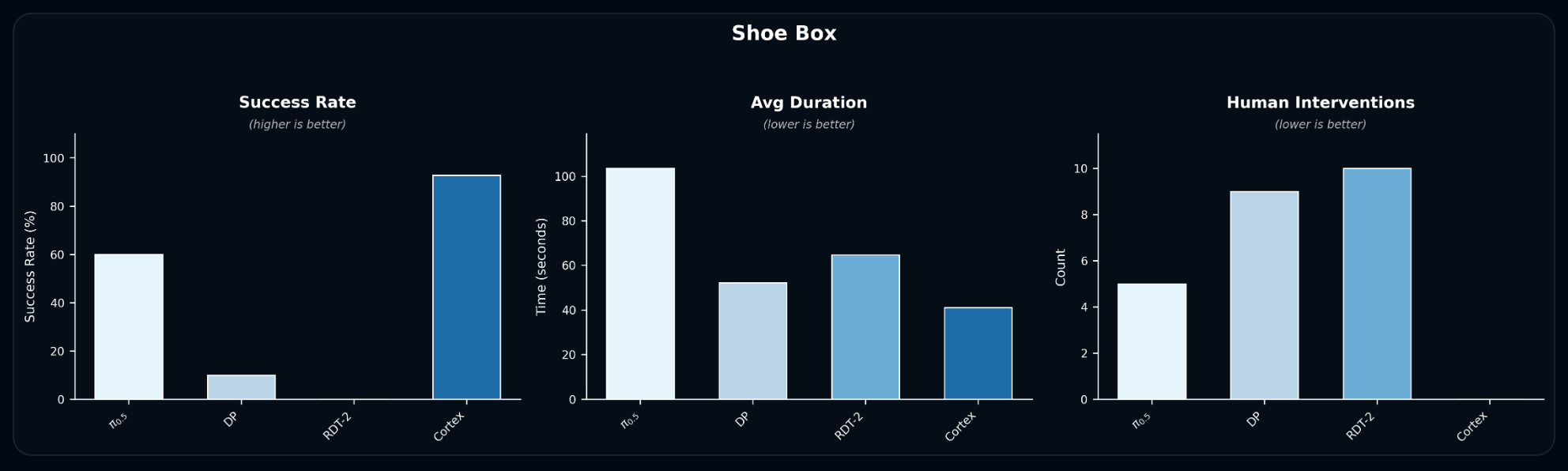
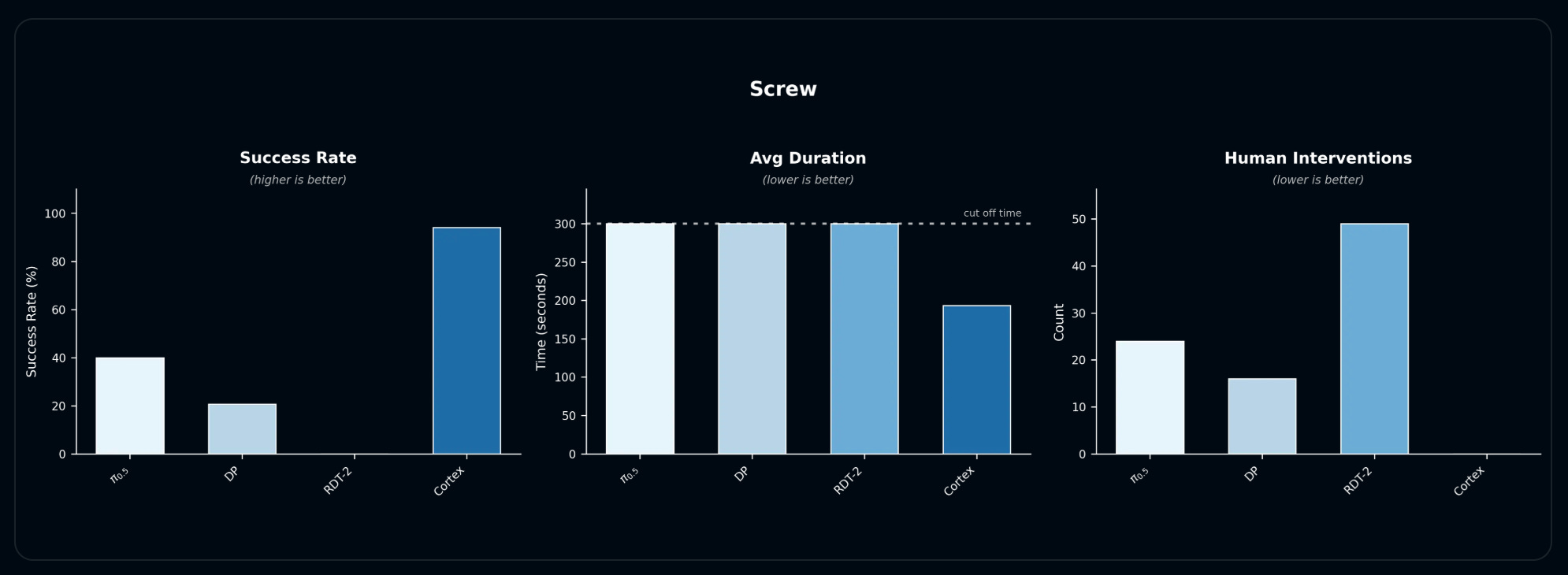
In fine-grained screw sorting, Cortex achieves near-perfect per-operation success (~95%+) and the shortest average completion times, while baselines often hit unrecoverable states and fail to finish.
In cluttered sorting of items and trash, Cortex again outperforms its peers, reaching per-operation success rates above 90% and completing all rollouts autonomously, whereas all baseline policies require human intervention or time out before finishing.
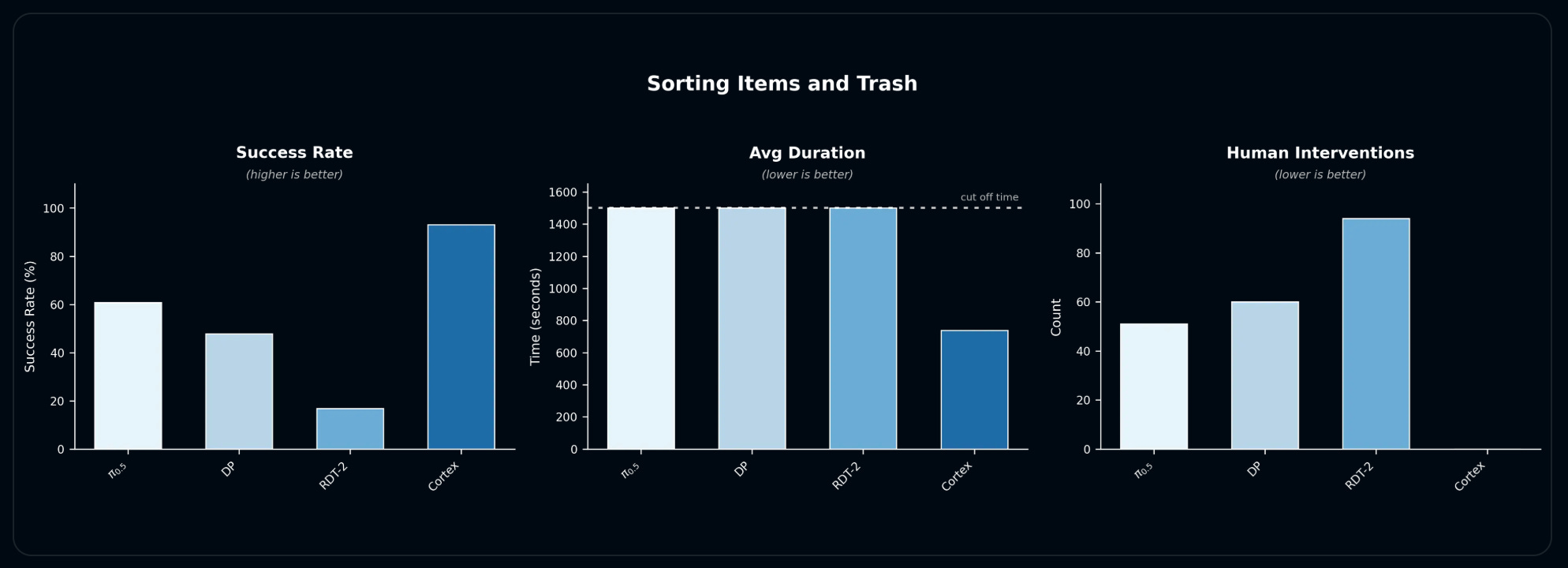
Across tasks, Cortex’s combination of high success, low intervention, and reduced duration under identical runtime constraints highlights planning’s concrete impact on real-world manipulation performance. These results come from controlled evaluations, but the system's longer-term value depends on what happens when it operates continuously across a growing fleet of 100+ robots.
Learning in production
With Cortex 2.0, deployment generates more than execution traces. Each imagined trajectory can be compared with what actually happened so that the model learns where its forecasts were accurate and where they drifted.
As predictive alignment improves, planning becomes more reliable. As reliability increases, deployment expands. As deployment expands, the distribution of physical interactions broadens. The flywheel compounds forecasting accuracy as well as execution quality.
Today, Cortex 2.0 is being validated most heavily in returns handling, where sequence-dependent failures are common and intervention costs are high. Whether similar gains hold across the long tail of industrial manipulation remains an empirical question.
Reactive systems can perform well in structured tasks. The test for world-model planning is whether it consistently turns fragile autonomy into durable autonomy across varied environments.
The architecture is in place. The next phase is scale.