




Introduction
A couple of months ago, people were marveling at the output of Luma Labs’ Dream Machine, a text-to-video model that was being touted as a Sora-killer. Demand to try the model was so high that a queuing system was rapidly introduced. But on the other side of the world, Kuaishou, a Chinese company that’s unfamiliar to many in the west, unveiled Kling. Not only was it available immediately, videos were generated reasonably quickly, the physics seemed accurate, and the output didn’t deviate from the prompt. While only short generations are currently available, Kuaishou claims the ability to generate 2-minute segments. AI Twitter was suitably impressed.
AI progress from Chinese labs has received significantly less attention than the model race between the biggest US labs. Commentary tends to be written from the standpoint of ‘who’s winning?’ and ‘are sanctions backfiring?’ and look to find a one-word answer.
We’ve made no secret of both our concerns about the Chinese Communist Party’s AI ambitions or our belief in the responsibility of the technology sector to contribute to defense and national security. However, that doesn’t make the answers to these questions straightforward. As we start gathering material for the State of AI Report, we’re sharing our assessment on some of these points. Spoiler alert: the answers are complicated.
Areas of strength
If we take the LMSYS Arena as a proxy, a small handful of Chinese labs are producing strong models that are highly competitive with the second-most powerful tier of models produced by US frontier labs. On specific sub-tasks, their performance matches the US state of the art. The labs in question are 01.AI (Yi), Alibaba (Qwen), Zhipu AI (GLM), and DeepSeek AI (DeepSeek).
As a product of necessity (more on that later), these labs have focused on achieving high levels of performance with maximal computational efficiency. If we take DeepSeek-V2 as an example, the researchers deploy a range of techniques to prioritize efficiency. These include:
Optimized Attention: A novel attention mechanism called Multi-head Latent Attention (MLA) that compresses the key-value cache, significantly reducing memory requirements during inference without sacrificing performance.
Enhanced MoE Architecture: a refined Mixture-of-Experts setup called DeepSeekMoE, featuring finer-grained expert segmentation and shared expert isolation. This allows for more efficient training of large models compared to traditional dense architectures.
Constrained Expert Routing: A device-limited routing mechanism that caps the number of devices involved in processing each token, helping to control communication overhead in distributed training.
Adaptive Token Dropping: A strategy to selectively drop less important tokens during training, reducing computational waste from unbalanced expert utilization.
Inference Optimization: For deployment, they used aggressive quantization techniques.
Chinese labs are upfront about how geopolitics has led them to prioritize efficiency. Kai-Fu Lee, the founder of 01.AI has said that “with a very high-quality infrastructure team, for every 1,000 GPUs, we might be able to squeeze 2,000 GPUs workload out of them”.
Models produced by Chinese labs have scored particularly well on math and coding. Again, taking LMSYS as a proxy, Yi-Large-preview is 5th, beating some iterations of GPT-4 and Gemini 1.5, while DeepSeek-Coder-V2-Instruct is 6th. DeepSeek also created DeepSeek-Prover, which outperformed GPT-4 on math problems.
They generated large-scale synthetic theorem-proof data by translating informal math problems from the internet into formal statements and using an iteratively improved language model to generate proofs. This synthetic data is then used to fine-tune the model, creating a recursive self-improvement cycle. While it only proved 5 out of 148 problems on their International Mathematical Olympiad benchmark of choice, GPT-4 proved … 0.

We’ve also seen vision-language models, which were competitive with the state of the art from US competitors last year. Qwen-VL, for example, based on the Qwen-7B LLM was highly competitive for its size at image captioning, visual question answering, and understanding/localizing specific objects or regions in images based on natural language description.
While Kling remains the standout success story for Chinese text-to-video models, it’s a space where Chinese labs are likely to do well. Not only are they poised to benefit from huge volumes of data and user-generated content, China’s weak copyright protection regime means model builders aren’t likely to run into the same time-consuming legal troubles as their western peers. Text-to-video models also tend to come with lower GPU requirements than LLMs, as they typically work with fixed-sized image or video inputs and their architecture allows for the more efficient processing of visual data.
In response to this progress, we’ve seen one common (and in our view, lazy) criticism emerge. This is the notion that Chinese frontier models are simply a Llama rip-off, with 01.AI’s work often in the frame. We’ve also seen this employed as a flawed argument to restrict open source AI on national security grounds. This is grounded in a misunderstanding about LLM training. It’s true that some Chinese models use the same architecture as Llama, but that architecture itself is only subtly different from the original transformer. Access to Llama hasn’t given Chinese labs some kind of secret recipe that they would have been unable to obtain themselves through other work. Meta themselves have said that Llama’s key strength is in its training data. 01.AI’s key work was in creating a high-quality dataset - something the company was upfront about.
Ironically, one body that might agree with this weak line of national security reasoning is the CCP, with the Beijing Academy of Artificial Intelligence warning second-in-command Li Qiang about the lack of self-sufficiency in model architecture.
Cracks below the surface
That’s not to say that all is rosy.
One striking thing about this work is the narrowness of the base. Innovation seems to be disproportionately concentrated in a small cluster of long-standing local tech giants or start-ups with well-known founders. Outside this pool, there are signs that investment into the space is slowing amid a challenging macro climate. HongShan, the artist formerly known as Sequoia China, recently closed a new $2.5B fund, significantly down on its $9B fund (which it has reportedly struggled to deploy).
Pockets of excellence potentially conceal a weaker broader ecosystem and risk resulting in a lack of competition. With little sign that international capital is about to return and the US preparing to restrict outbound investment, either local investors will need to step up or the government will need to step in. Although as China’s semiconductor subsidy efforts have shown (more on that later), the government doesn’t always make for an efficient allocator of capital.
Many of the criticisms aimed at models from US labs are also aimed at their Chinese counterparts, but individual cases of questionable practice appear to be worse. Potential future resource scarcity and resulting government involvement in allocation potentially creates an incentive for labs to create the strongest looking benchmark performances possible. When models claim 72.2% on MMLU and 74.4% on HumanEval with only 3.7B active parameters, they unsurprisingly attract skepticism. Other cases of relatively obscure labs scoring close to 80% on MMLU have also come under scrutiny.
Labs have received more than just Twitter snark on these issues. For example, Qwen has been accused of dataset contamination by at least two different actors. Skywork, a Chinese team producing an open bilingual foundation model, included a section on dataset contamination in their own technical report, comparing peers:

Meanwhile, when X.ai reevaluated a number of models, using the Hungarian national finals math exam set after they were released, Qwen’s performance dropped by 30 points.

Add to all this, the state imposes significant inconvenience on frontier model developers when they want to productize their work. We talk about over-regulation in the west, but the compliance regime in China is punishing and largely focused around political censorship. The country’s internet regulator requires companies to prepare a test of between 20,000 to 70,000 questions to test their ability to produce safe answers, as well as a dataset of largely ideological questions it will refuse to answer. To make things harder, the model doesn’t just have to refuse to answer ‘inappropriate’ questions, it can’t refuse to answer too many safe questions - the censorship can’t be too obvious.
The first model to achieve compliance instigated the following baroque process:

What about US sanctions?
It’s important to be clear about the purpose of sanctions. The gradually escalating US sanctions were never pitched as a method of crippling advanced Chinese AI research overnight. Similarly the sanctions against Russia following its invasion of Ukraine weren’t meant to lead to a popular uprising against President Putin - despite feverish media commentary. Rather, the purpose of sanctions is to introduce frictions that act as a longer-term break on growth by introducing small frictions. As Chris Miller, the author of Chip Wars, put it - “to throw sand in the gears” by making it hard to build up large clusters of advanced chips.
Critics who predicted that sanctions would spur innovation in Chinese semiconductors have been flatly proven wrong. State subsidy appears to have made a greater contribution to officials’ bank accounts than to innovation. Lay-offs have started at previously hot companies. Meanwhile, the Chinese state of the art continues to lag its Taiwanese counterpart by the customary five years, in theory. There was much excitement in late 2023 when Huawei released its Kirin 9000S, a 7nm chip, as we documented in that year’s State of AI Report:

As we wrote at the time, there were doubts about SMIC’s ability to manufacture these chips at quality and scale. These proved to be well-founded in the case of the Ascend 910B, Huawei’s 7nm AI chip. SMIC has struggled to produce them in the required quantities and 80% of them have been found to be defective. Huawei appears to be skeptical about its own ability to innovate in this space.
While it’s theoretically easy to covertly move GPUs across borders (more on that below) - it’s much harder to smuggle the crucial equipment required for advanced semiconductor manufacturing. This is most obviously the case with extreme ultraviolet lithography machines, which etch the intricate circuit patterns on silicon wafers.
The sole producer of advanced machines, Netherlands-based ASML, is no longer selling its top-end equipment to Chinese companies. These are difficult to smuggle as they’re produced in low volumes, are very expensive, and can be the size of double-decker buses. Chinese companies have allegedly attempted industrial espionage, but these machines contain over 100,000 components, which have to be calibrated perfectly. This likely makes them the hardest single piece of equipment in the world to replicate.
Given this, then how are labs continuing to produce SOTA research as rapidly as ever?
Loopholes you can drive a bus through
Firstly, many of the well-funded big labs and start-ups prepared for this eventuality. In fact, they’ve made no effort to conceal this at all. Late last year, Tencent was advertising the size of its stockpile as was 01.AI. It also didn’t help that upcoming restrictions were frequently telegraphed by the US Commerce Department months before they were implemented, giving companies ample warning.
One of the reasons NVIDIA hardware is so popular is its robustness - individual GPUs can last for close to a decade in some cases. By the time these GPUs reach the end of their productive lives, AI research may have moved onto a totally different paradigm with different hardware needs.
To supplement the A100 and H100s that were bought legally pre-restrictions, labs have also been able to buy NVIDIA’s sanctions compliant chips. The NVIDIA A800 was restricted to roughly 70% of the speed of the A100 (which still made it more powerful than most domestically produced competitors), before later being banned by the US. NVIDIA is now shipping the H20, L20, and L2 GPUs to China.
The H20 is a masterpiece in rigidly sticking to the letter, but not the spirit, of a sanctions regime. The H100 is vastly superior on some metrics - for example if you measure by FP16 Tensor Core Flops, it has a 6.68x performance advantage. But, despite its lower overall computing power, the H20 architecture has been optimized for LLM workloads in a way that is fully sanctions compliant and it’s reported to be 20% faster than the H100 in LLM reasoning tasks. If anything, it’s a downgraded version of the H200 that NVIDIA plans to release for non-Chinese customers next year.
Unsurprisingly, these chips have proven popular with Chinese customers, with NVIDIA forecast to net $12B in H20 sales this year. While Gina Raimondo, the US Commerce Secretary, previously said that “if you redesign a chip around a particular cut line that enables [China] to do AI I’m going to control it the very next day”, the H20 remains uncontrolled. This seems like an oversight.
However, NVIDIA does charge a premium for its China-compliant hardware to cover both the geopolitical risk and the inconvenience of having to make it in the first place. This means that smaller labs and start-ups have been disproportionately hit by the restrictions and have found themselves on the receiving end of rationing from local hyperscalers. Some have even resorted to stripping NVIDIA gaming chips of their core components and reinstalling them on new circuit boards. NVIDIA gaming chips often have raw computing power, but are not designed for the high-precision calculations needed with big datasets.
Beyond that, prohibition creates a black market. This primarily operates through resellers purchasing NVIDIA equipment from Dell or SMIC and shipping it to China from third countries that don’t have export control regimes. To avoid setting off alarms, resellers often file incomplete customs forms or don’t specify the exact equipment they’re selling. Sometimes entire servers are shipped, other times, a student might return from Singapore with some A100s in their luggage. This has allowed state-run research institutions and universities to acquire high-end chips long after the imposition of restrictions.
This might meet small shortfalls in demand and, as we’ve argued before, there’s a lot to be said for smaller models. However, it’s hard to build and maintain a large cluster through A100s smuggled in students’ suitcases. This is partly due to the inconvenience, but mainly because a global supply squeeze means that there is a ceiling on the volume of inventory resellers can get their hands on.
A little help from their friends
Many Chinese tech companies have another ace up their sleeves - a large network of local affiliates.
Companies like Huawei or ByteDance have a global footprint. There’s no prohibition on providing these companies’ local affiliates with cloud services outside China. ByteDance has been renting access to the most powerful NVIDIA chips in the US via Oracle, while Alibaba and Tencent are in discussion with NVIDIA about building US-based clusters. Again, this is something that the US could theoretically stop but has chosen not to.
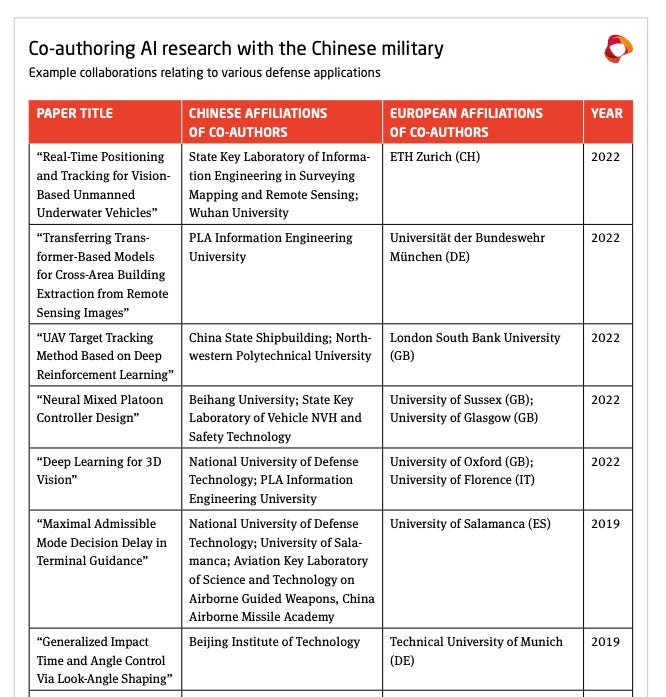
Chinese labs can do more than source their compute in the west. In European universities, they can find a willing source of research talent and assistance. As we compile Guide to AI, we routinely see high quality examples of these collaborations. For example, Huawei remains a major donor to the Technical University of Munich, one of Europe’s biggest concentrations of AI talent and research on UAVs. Meanwhile, the UK-China Transparency Project has covered the millions of pounds that Chinese military-linked entities have given the University of Cambridge to help it conduct sensitive AI research.
Researchers have found red warning lights all over the dashboard, with research collaborations (including one with the Germany military’s own university) conducted with Chinese military-linked institutions, even after European governments had grudgingly started excluding Huawei from their 5G infrastructure.
This active cooperation is accompanied by an oddly relaxed attitude towards other risks, whether it’s the UK Government authorizing local councils to use CCTV cameras made by Chinese state-owned Hikvision or the US allowing Chinese self-driving start-ups to map 1.8 million miles of roads with hi-res cameras and lasers.
Closing thoughts
So what should we draw from this?
Firstly, Chinese labs are clearly capable of producing SOTA research rapidly. Even if there are questions around … questionable benchmark use, the LMSYS arena suggests that practitioners believe their output to be of value.
Secondly, US sanctions are likely harming some sections of the ecosystem, while the deepest pocketed players remain resilient. Chip manufacturers and infrastructure providers have demonstrated that they will do everything within their power that stops short of breaking the law to continue selling to a lucrative market.
If we are aware of this, then it is unlikely that the US Commerce Department and the country’s wider national security apparatus are unaware (we hope). Therefore, we can only conclude that they are stopping short of tougher action deliberately. This may be out of a desire to avoid retaliation (which has so far been relatively half-hearted) or to avoid harming US businesses. While the US likely can’t stop the student in Singapore with the suitcase, it can probably stop a ByteDance partnership with Oracle. That’s a policy choice.
Can you cover the leading Chinese AI startups in a future exploration. That's the key point of all of this to me.