




Hi all!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering key developments in AI policy, research, industry, and startups over the last month. Before we get into it, some house-keeping from us:
We held two energizing AI meet-ups in Paris and Munich, bringing together over 400 researchers, founders, and builders. Stay tuned for NYC and SF events coming in April and May via our events page.
Register interest for our annual Research and Applied AI Summit (RAAIS) on 14 June, which brings together 200 AI researchers, engineers, founders, and operators from around the world for a day of best practices and good vibes.
Congratulations to our friends at Intenseye, who raised a $64M Series B to launch a new era for workplace safety. You can read the full story here.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
As February came to a close, Mistral and Microsoft unveiled a multi-year partnership to howls of outrage across the European technology ecosystem (for some reason, their partnership with Snowflake didn’t provoke the same reaction). The partnership would allow Mistral to scale its training efforts on Azure’s infrastructure, make Mistral’s premium models available via Azure AI Studio, and commit the two companies to partnering on training purpose-specific models. The deal immediately provoked a range of reactions, most of them negative. European lawmakers claimed they had been duped into weakening the AI Act to facilitate domestic leadership, only for Mistral to go overseas for partners. The Microsoft partnership also included a €15M in Mistral via convertible note, which immediately prompted a European competition investigation.
We found ourselves confused by the sound and fury. As a ten-month old company, it’s entirely logical that Mistral would seek a well-established go to market partner to facilitate model distribution. Being a French company does not oblige them to pick a European partner (if a credible alternative were to exist!).
This doesn’t somehow prove that Mistral doesn’t really believe in open source or that its opposition to elements of the EU AI Act was somehow sinister or in bad faith. A belief that the safety risk of LLMs is being overstated doesn’t obviously contradict with striking a partnership with a US company. The French Government agrees with us and has welcomed the deal.
This chaos contrasts with a relatively quiet few weeks over the channel on safety island. The UK finally published its long-awaited response to its consultation on its pro-innovation white paper to relatively little comment. This was likely because after one year, many roundtables, and 409 responses later, the government’s position had barely budged. The only real development was the first official statement that highly capable models would likely require regulation at an indeterminate point in future, once they reached an unspecified capability threshold. Given the considerable time and effort involved in this exercise in marking time, we do wonder if this kind of stakeholderism is an effective way to make policy…
As elections approach, India has suddenly moved from being a pro-innovation jurisdiction to embracing some of the worst proposals on AI governance we’re yet to see. In a sweeping advisory notice, the Indian Ministry of Electronics and Information Technology declared that any AI model, LLM or software using generative AI should seek the “explicit permission of the government of Indian” ahead of deployment if they are still being tested or are potentially unreliable in any form. The latter term essentially encompasses any model. Following widespread criticism, Entrepreneurship Minister Rajeev Chandrasekhar took to X to clarify that the notice would not apply to start-ups.
At this stage, the notice is non-binding, but it signals the direction of future regulation. This kind of measure would be chilling for innovation and suggests a poor understanding of the technology. While apparently aimed at preventing a repeat of a Gemini-style event, it’s unclear how the government is defining an acceptable level of reliability or its ability to assess it. It also overlooks the importance of how techniques like reinforcement learning from human feedback have played a critical role in allowing tools like ChatGPT to scale.
These political goings-on pale in comparison to the Gemini blow-up that took place. Readers will be familiar with the comical (and saddening to many involved in its development, but not its red teaming) sequence of events surrounding both the company’s AI image generator and chatbot’s ability to handle sensitive topics of conversation.
Neither Alphabet CEO Sundar Pichai’s rather nonspecific apology to staff nor the company’s public blog post seemed to acknowledge that Gemini was performing as intended. Based on both Gemini’s safety architecture in general and specifically its prompt transformation, this was the only possible outcome. This is why we are instinctively skeptical of the idea that Gemini was released too quickly or that this is proof of inadequate testing. Simply blaming a technical error and trying to move on probably won’t cut it. Google will likely have to reflect more widely on the cultural and process failings that paved the way for an incredibly predictable implosion.
Scrutiny will only intensify on model providers as we edge towards elections around the world. Voice-generation start-up ElevenLabs has followed OpenAI in publishing how it intends to approach potential abuse of their technology, largely reiterating existing measures, such as their ‘no-go voices’ policy and the release of their speech classifier. We’ve definitely observed an uptick in panicked media coverage on this topic, but having reviewed many examples of political deep fakes, we’re yet to be terrified. While this may well change, examples so far are largely crude forgeries and likely proliferate many more times as a result of the coverage than they would otherwise have organically.
🍪 Hardware
NVIDIA’s long march continued relentlessly as it crossed the $2T market cap threshold for the first time on 23 February, days after its earnings showed a 265% year-on-year revenue jump, driven by its booming AI business. As a sign of the company’s ambition, CEO Jensen Huang told the World Governments Summit in Dubai that every country in the world needed its own sovereign LLM and AI infrastructure, which NVIDIA could support, as “it codifies your culture, your society’s intelligence, your common sense, your history”. We’re not 100% convinced that you need an LLM to do this or that the government is particularly well-placed to build it. As the Mistral/Microsoft blow up shows us, we really need a better definition of sovereignty…
February also saw NVIDIA release Chat with RTX, a local app that allows you to query your own notes, saved content, or even videos by URL. While it currently requires a hefty 40GB of disk space and consumes 3GB RAM, it runs entirely locally. The product is still going through teething problems, around source attribution, its YouTube download function, and crashing - but it’s an exciting sign of things to come.
NVIDIA didn’t stop there, unveiling a new lab focusing on robotics and embodied AI called GEAR, for Generalist Embodied Agent Research. The group states that its mission is “to build foundation models for embodied agents in virtual and physical worlds” and they’re now actively hiring. This is particularly exciting and full of promise.
We may not be taking Jensen’s vision of sovereignty too seriously in this section, but China is having to come up with new ways of supporting start-ups as US sanctions bite. With the country’s big tech companies cutting back their GPU rental offerings, driving up prices, 17 Chinese city governments are providing compute vouchers to start-ups. Amid the firehose of Chinese subsidy efforts, this strikes us as by far the most sensible, and less likely to fall victim to the rampant corruption that’s accompanied direct subsidy of domestic semiconductor projects. European governments wondering why their start-ups aren’t doing better should take note.
Pressure on China will only intensify as the Biden administration is allegedly preparing to restrict US supplies to China-based semis manufacturer SMIC, the manufacturers of the chip powering Huawei’s Mate 60 Pro phone. While still a few years behind the state of the art in Taiwan, it’s China’s most powerful chip yet. Official letters to SMIC suppliers have already blocked millions of dollars of exports. In a similar vein, AMD has been informed by the US government that the MI309, its special chip for the Chinese market, is too powerful to sell without a license from the Department of Commerce.
Could China’s misfortune be Vietnam’s opportunity? The country is seeking to position itself as a neutral venue for semiconductor companies looking to do business in south-east Asia. It’s planning a series of industry grants as well as a significant training program for its domestic workforce, along with a series of tax incentives. While Vietnam has historically been a site for assembly, testing, and packaging - it historically lacked the skills base for higher-level parts of the electronics value chain.
Speaking of technology that won’t be reaching China, ASML is preparing to produce its new $350M High NA EUV machine, which is apparently the size of a double-decker bus. This new tool will give chipmakers the power to triple the density of transistors on their chips. Moore’s Law lives to fight another day.
🏭 Big tech start-ups
While Google reeled from the Gemini fall-out, OpenAI was reeling from drama of its own. In a lawsuit filed last week, Musk alleged that OpenAI had transformed “into a closed-source de facto subsidiary” of Microsoft and that it had breached its original Founding Agreement to focus on maximizing “the benefit of humanity”. The lawsuit argues that GPT-4 already constitutes AGI, Microsoft wields dangerous levels of control over the company, and that the new board lacks the ability to hold the company’s leadership to account. OpenAI hit back, releasing redacted emails appearing to suggest that Musk had previously supported the move and sought more control over the company for himself.
We aren’t legal experts, but there seems to be broad consensus that the case itself will be a tough one, given the absence of any written contract. It’s unlikely that Musk and his team don’t know this, so it’s likely that they hope this case will do two things. Firstly, lead to potentially damaging disclosures about the company, its operations, and private interactions between its senior leadership. Secondly, force a conversation about who, if anyone, is providing any real oversight over the company. We suspect few would argue that the Board is - at least while maintaining a straight face… OpenAI will likely see off this legal challenge, but at what cost?
It’s not all bad news for the company though. February saw the announcement of Sora, OpenAI’s text-to-video generation model. The model, currently only available to a handful of researchers, is able to generate videos up to a minute long, while maintaining 3D consistency, object permanence, and high resolution. It also allegedly displays emergent simulation capabilities.
In a typically light technical report, OpenAI discusses its novel use of spacetime patches, similar to the tokens used in transformer models, but for visual content. This allows Sora to learn efficiently from a vast dataset of videos. OpenAI also trained Sora on visual data in its native size and aspect ratio, removing the usual cropping and resizing that reduces quality. All in all, a bad time to be a Stable Video Diffusion wrapper company.
Meanwhile, Anthropic unveiled Claude 3, its GPT-4 and Gemini challenger. Claude 3 Opus, its most powerful model, was able to outperform GPT-4 on some reasoning, math and knowledge benchmarks. Sort of. It’s worth noting that Anthropic is benchmarking against the version of GPT-4 released early last year, not the most recent GPT-4 Turbo.

Other interesting features include the use of synthetic data for training to help represent scenarios that might be lacking in a scraped dataset, as well as a hefty 200,000-token context window (that extends to 1M for select customers). It’s also the first Anthropic model to build in vision capabilities, with an ability to process photos, charts, graphs, and technical diagrams.
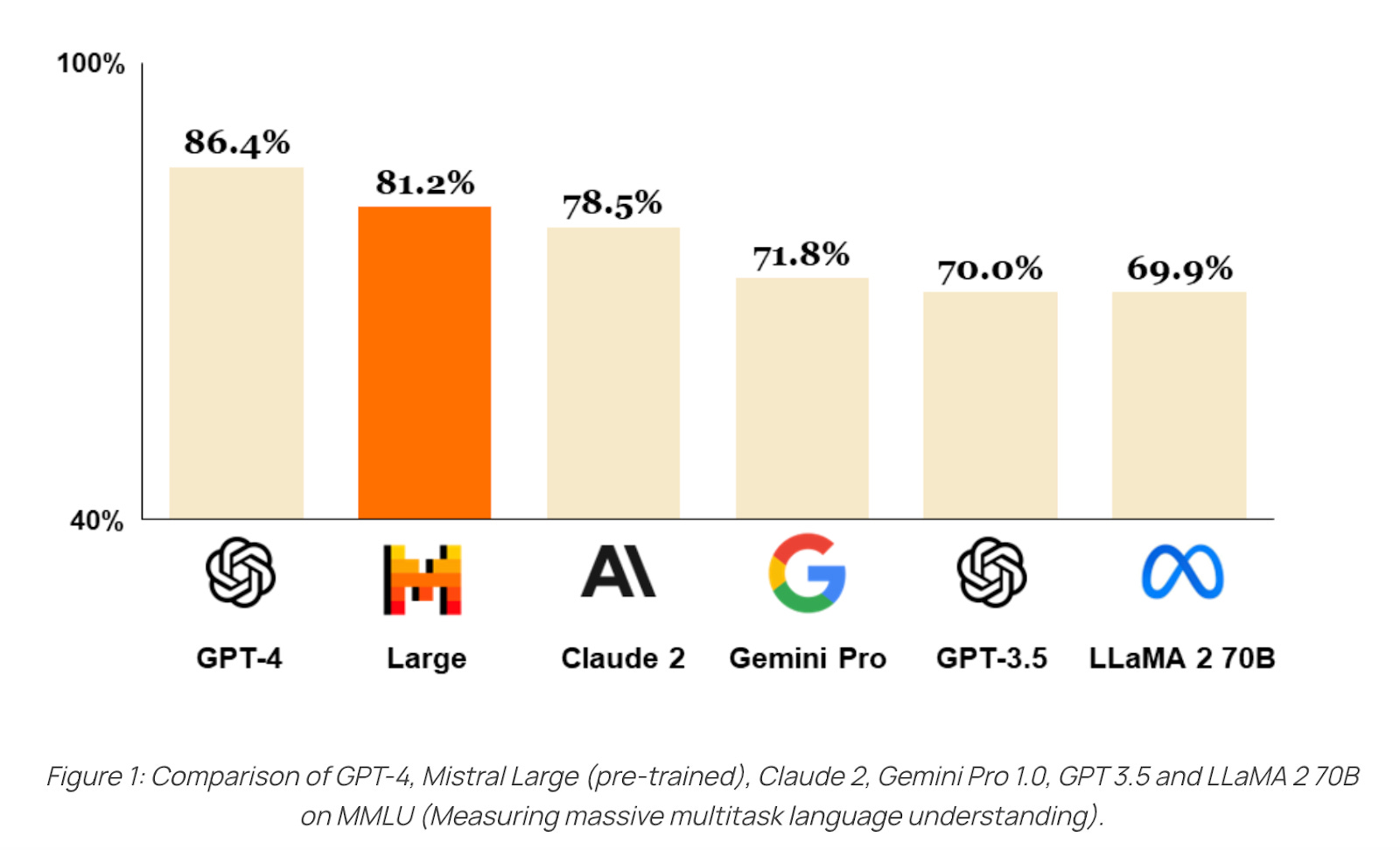
Beyond offending the world with its choice of cloud partner, Mistral has had a productive month too. The company announced details of Le Chat, currently in beta, a multilingual assistant based on Mistral’s models. Accessible via the product is the new Mistral Large, the company’s flagship, closed-source model, which Mistral claims is the second-most capable model available through an API. Mistral is particularly keen to flex its multi-lingual abilities, with Mistral Large consistently crushing Llama 2 70B in French, German, Spanish, and Italian.
Meanwhile, Inflection has unveiled an upgrade to its “personal AI” product Pi, rolling out Inflection-2.5. While still behind GPT-4, it’s able to be highly competitive across a range of benchmarks, despite allegedly being trained on approximately 40% of the compute. Given the computational resources used for GPT-4 have never been disclosed anywhere, we are unclear on how the Inflection team reached this number.
🔬Research
Large-scale characterization of cell niches in spatial atlases using bio-inspired graph learning, Wellcome Trust Sanger Institute, Helmholtz Center Munich and others. Presents a novel computational tool called NicheCompass, based on graph deep learning. NicheCompass is specifically designed to analyze spatial biological data, such as those obtained from transcriptomic and proteomic studies, on a large scale. NicheCompass works by creating a graph-based representation of the data, where nodes represent cells and edges represent the interactions between them. This allows the tool to identify and characterize cell niches, which are specific microenvironments within tissues where cells interact and function together. This can help researchers understand the complex spatial organization of cells in tissues and how this organization affects cellular function and communication. The tool has the potential to be applied across multiple tissue samples, making it a versatile resource for biological research
OK Robot: An open, modular framework for zero-shot, language conditioned pick-and-drop tasks in arbitrary homes, Meta AI. Introduces OK-Robot, a framework that enables robots to perform pick-and-place tasks in new and unstructured environments, such as homes, without needing prior training for those specific settings. OK-Robot combines vision-language models with movement planning and object manipulation models to understand natural language instructions and visually identify objects.

The system requires an initial manual scan of the environment to create a 3D map from which objects are identified. These are then stored in a semantic object memory module. The robot uses this information to plan a path, pick up the specified object, and drop it at the designated location. In tests across various homes, OK-Robot successfully completed tasks in 58% of cases, and the success rate improved to over 82% with optimized queries and less cluttered spaces.
Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia, Google DeepMind. Concordia is a new library designed to enhance generative agent-based modeling by incorporating actions that are grounded in physical, social, or digital spaces. Concordia allows for the creation of simulations where agents, guided by LLMs, can perform actions that are reasonable within their environment, recall relevant information, and interact with digital technologies through API calls.

A key feature is the Game Master agent, inspired by tabletop role-playing games, which oversees the simulation environment and translates the natural language actions of other agents into concrete outcomes. This could involve checking the feasibility of actions in a physical space or managing digital interactions through APIs. Concordia is designed to be flexible and applicable to a wide range of uses, from scientific research to the evaluation of digital services by simulating user behavior or generating synthetic data.
AlphaFold Meets Flow Matching for Generating Protein Ensembles, MIT. Explores a novel approach to generating diverse and accurate protein structure ensembles by integrating AlphaFold and ESMFold with flow matching, a generative modeling framework. This method aims to sample the conformational landscape of proteins more effectively than previous techniques. By training on the Protein Data Bank and evaluating on proteins with multiple structures, the method demonstrates the ability to produce ensembles with similar precision but greater diversity compared to traditional methods like MSA subsampling. Further fine-tuning on coarse-grained molecular dynamics trajectories allows the model to generalize to unseen proteins, accurately predict conformational flexibility, and model physiochemical properties such as intermittent contacts and solvent exposure. This approach represents a significant advancement in computational protein structure prediction, offering a more comprehensive understanding of protein flexibility and function.
You can now train a 70b language model at home, Answer.AI, Hugging Face, University of Washington. This paper details Answer.AI’s first project - an open source system that enables the training of a 70 billion parameter language model on just two 24GB GPUs, typically found in consumer-grade gaming computers. This system combines Fully Sharded Data Parallelism (FSDP) and Q-LORA. The use of FSDP allows for the efficient distribution of model parameters across multiple GPUs, reducing the memory requirements per GPU. The technical approach involves leveraging techniques such as gradient accumulation and quantization to manage memory usage effectively, while maintaining high training speeds. This system supports various configurations, including mixed precision training, to optimize computational efficiency.
Also on our radar:
Divide-or-Conquer? Which Part Should You Distill Your LLM?, Apple. Following recent research showing LLMs perform better on reasoning tasks after being asked to solve subtasks, the paper proposes breaking down reasoning tasks into problem decomposition and problem solving phases, demonstrating that this strategy outperforms a single-stage solution. It argues that problem decomposition can be distilled into a smaller model more easily than problem solving, as the latter requires extensive domain knowledge while the former only needs general problem-solving strategies.
Major TOM: Expandable Datasets for Earth Observation, Hugging Face, European Space Agency. Presents a framework named Major TOM (Terrestrial Observation Metaset), aimed at improving Earth observation (EO) research. The core of this framework, Major TOM-Core, is an open-access dataset that encompasses a significant portion of the Earth's land surface. Designed with expandability in mind, it allows for the inclusion of new data as it becomes available, supporting the development of deep learning models in EO.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, ByteDance. Presents Megascale, a production system that enables training very large language models on over 10,000 GPUs by taking a full-stack approach that co-designs algorithmic components like model architectures and optimizers with system components spanning computation, communication, data pipelines, and network performance tuning. To address the training efficiency and stability challenges at this scale, MegaScale incorporates in-depth observability and diagnostic tools to monitor systems components, identify root causes of failures, achieve fault tolerance, and improve utilization by 1.34x over previous approaches when training a 175 billion parameter model.
Sequence modeling and design from molecular to genome scale with Evo, Arc Institute. Introduces Evo, a genomic foundation model that uses a novel architecture called StripedHyena to process and generate DNA sequences at an unprecedented scale. Evo demonstrates the ability to predict the effects of mutations on protein function, the functional properties of non-coding RNAs, and gene expression from regulatory DNA. It can also generate complex molecular systems like CRISPR-Cas complexes and transposable elements. The model outperforms specialized models in zero-shot function prediction and can create sequences with realistic genomic coding structures.
Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts, Meta. Presents a method for generating a wide range of adversarial prompts to test and improve the robustness of LLMs. This approach, known as Rainbow Teaming, frames the generation of adversarial prompts as a problem of achieving both quality and diversity. It employs an open-ended search algorithm to create prompts that are designed to elicit potentially unsafe or biased responses from the target LLM. By varying their approach and content, they can systematically explore LLM weaknesses.
OS-Copilot: Towards Generalist Computer Agents with Self-Improvement, Shanghai AI Laboratory, East China Normal University. Introduces OS-Copilot, a framework for creating computer agents that can autonomously perform a broad range of tasks across different operating system environments. The paper showcases FRIDAY, an agent developed using OS-Copilot, which demonstrates significant self-improvement and adaptability in automating tasks like spreadsheet manipulation. FRIDAY's capabilities are evaluated using the GAIA benchmark, where it shows a notable improvement in task performance, highlighting the framework's potential for advancing digital assistant technologies.
💰Startups
🚀 Funding highlight reel
Abridge, a start-up that summarizes and structures medical conversations for doctors and patients, raised a $150M Series C, led by Lightspeed and Redpoint.
Ambience Healthcare, building an AI operating system for healthcare organizations, raised a $70M Series B, led by Kleiner Perkins and the OpenAI Startup Fund.
Baseten, building a serverless backend for ML applications, raised a $40M Series B, led by IVP and Spark Capital.
Bioptimus, developing a universal foundation model for biology, raised a $35M seed, led by Soffinova Partners.
Clarity, a start-up identifying deepfakes and synthetic media, raised a $16M seed, led by Walden Catalyst and Bessemer Venture Partners.
Daedalus, a start-up building AI-powered precision-manufacturing factories, raised a $21M Series A, led by NGP Capital.
Ema, a start-up building a “universal AI employee”, has raised a $25M venture round, led by Accel, Section 32, and Prosus Ventures.
Figure, building humanoid robots, raised a $675M Series B, involving Microsoft, Amazon, Nvidia, Intel, OpenAI, and others.
Ideogram, the image generation start-up that specializes in legible text, raised a $80M Series A, led by a16z.
Intenseye, building AI systems to improve employee health and safety, raised a $64M Series B, led by Lightspeed.
Inkitt, the AI-powered self-publishing platform, raised a $37M Series C, led by Khosla Ventures.
Langchain, a language model application development library, raised a $25M Series A, led by Sequoia.
Lambda Labs, building an AI compute platform, raised a $320M Series C, led by the US Innovative Technology Fund.
Magic AI, building an AI software engineer, raised a $117M Series B, led by NFDG Ventures.
Moonshot AI, the Chinese start-up building LLMs focused on long inputs, raised a $1B Series B, led by Alibaba.
Photoroom, the AI-enabled image capture app, raised a $43M Series B, led by Aglaé Ventures and Balderton.
Recogni, designing an accelerator chip for inference, raised a $102M Series C, led by Celesta Capital and GreatPoint Ventures.
Starship Technologies, building self-driving delivery robots, raised a $90M venture round, led by Plural and Iconical.
Unlearn.ai, an AI start-up accelerating clinical research, raised a $50M Series C, led by Altimeter Capital Management.
🤝 Exits
Definitive Intelligence, a start-up building API products for the application of data science in enterprise, was acquired by AI computing company, Groq.
InAccel, producing high performance accelerators based on FPGA engines, was acquired by Intel.
Patch Biosciences, a company applying AI and synthetic biology to gene therapies, and Reverie Labs, an AI for drug discovery company, were both acquired by Ginkgo Bioworks.
Udacity, the tech skills platform, is to be acquired by Accenture.
---
Signing off,
Nathan Benaich and Alex Chalmers 9 March 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | London.AI
Air Street Capital invests in AI-first technology and life science entrepreneurs from the very beginning of your company-building journey.
