




Prefer narration? Listen to the audio version.
Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and startups over the last month. But first, some announcements!
Register for our annual Research and Applied AI Summit (RAAIS) on 14 June, which brings together 200 AI researchers, engineers, founders, and operators from around the world for a day of best practices and even better vibes. We’ll feature talks from Synthesia, Altos Labs, Recursion Pharmaceuticals, Vercel, InstaDeep, and Google DeepMind.
AI meetups: Thank you to the hundreds of researchers, builders, and operators who came to our meet-ups in NYC and SF. We have another event in NYC on Wednesday, which is almost sold out - but feel free to sign up for the waitlist here. Keep an eye on our events page for future meet-ups.
Don’t forget to subscribe to Air Street Press to receive all our news, events, and analysis directly in your inbox. Recent pieces have included a deep dive into frontier model economics, reflections on the perils of simplistic analogies, and lessons from AI techniques and approaches that didn’t gain traction.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
In our previous edition, we looked at the tricky time AI companies have in navigating the Gulf. While local investors can write the multi-billion dollar cheques needed to fund expensive hardware, there is a web of complex institutional ties to China. G42, a sprawling Abu Dhabi-based AI company and investor, had rung a series of alarm bells in Washington for being simultaneously an OpenAI partner and a shareholder in ByteDance and a series of other Chinese companies. Following US pressure, G42 sold all of its stakes in Chinese companies earlier this year. Now G42 has gone one step further, taking a $1.5 billion investment from Microsoft - definitively picking sides.
This sequence of events illustrates how the AI arms race is making geopolitical divides simultaneously more fraught and simpler. In its quest to defend US companies’ IP and prevent China from accessing the most advanced capabilities, the US government is gradually losing its tolerance for ambiguous partnership: you’re either with us or against us.
On the one hand, this seems like bad news for Gulf nations like the UAE, who’ve depicted themselves externally as a regional Switzerland, where anyone is free to make money provided they don’t ask too many questions. But, the fact that US officials worked so closely for months to hammer out an agreement with Abu Dhabi’s leadership and G42 underlines the importance of having allies prepared to spend big on AI. Maybe the best place to be in an arms race is the middle - who knows, Brad Smith may well be rushing to join your board.
Back in greater Europe, spare a thought for Rishi Sunak. The leader of safety island’s early access agreement with frontier model providers appears to be struggling with teething problems. It turns out that corporations with highly valuable IP are much more willing to sign theoretical commitments to share their technology with the government than they are to … actually share it. Of the leading AI labs, so far, only Google DeepMind has allowed the UK’s AI Safety Institute to test a model before full public release.
UK pre-deployment testing appears to be suffering from two main problems.
Firstly, companies’ concern that, in a highly competitive environment, the process will slow model releases. We’ve already privately heard stories of entire releases being junked because a competitor has managed to exceed performance days before launch day.
Secondly, the UK is not the US. Companies fear that by allowing one non-US country pre-deployment access, they’ll open the floodgates for others to insist on the same. This is ultimately why ‘leadership’ on safety is challenging without accompanying leadership in capabilities. Even with the best qualified safety institute in the world, it will be a continual battle to assert relevance, especially as the US continues to bulk out its own rival.
The UK is down, but not out. The Competition and Markets Authority, the world-leading opponent of midcap tech M&A, dropped its review of competition in the frontier model space. The report warned of the possibility that “incumbent firms may try to use partnerships and investments to quash competitive threads, even where it is uncertain whether those threats will materalise”. To combat this, it suggested a broadening of the scope of merger control rules to make it easier for regulators to intervene in non-traditional anti-competitive arrangements.

While a functional, competitive marketplace is important, with many of these interventions, it’s unclear what regulators believe this should look like beyond “not this”. As a result, many of the accompanying decisions seem arbitrary. For example, the EU is investigating Microsoft-Mistral but not Microsoft-OpenAI, while the CMA is investigating Anthropic-AWS but not Anthropic-Google. The FTC is at least being consistent in seemingly investigating everyone.
Ultimately, considering the constraints around hardware and capex, the alternative to this world of partnerships is consolidation. While arguably logical, competition regulators would undoubtedly dislike and seek to frustrate it at every turn. Short of artisanal model builders hammering together GPUs in their garden sheds or NVIDIA deciding to become a not-for-profit, partnerships are the next best thing.
While regulators circle on competition, the generative AI copyright wars continue to rumble on. While the legal position remains as ambiguous as ever, the number of incidents and licensing deals continues to snowball. Ed Newton-Rex, composer turned Stability exec turned CEO of Fairly Trained, put the boot into hot music generation start-up Suno as well as Udio, arguing that their models had very likely been trained on large quantities of well-known copyrighted music. When provided with the lyrics of various well-known songs, Suno and Udio served up some eerily familiar chord sequences and melodies.
Meanwhile, Adobe is facing questions after it emerged that Firefly, its image-generating software, was partially trained on images produced by Midjourney and other competitors. At first sight, this may not seem like a big deal. But Firefly’s big selling point was that it was safe from copyright disputes as it was primarily trained on Adobe’s own database of licensed images. While in practice this likely doesn’t hugely affect the commercial safety of Firefly, it’s non-ideal from a trust standpoint, especially as Adobe has been publicly critical of others’ data collection practices.
Keen to avoid adding to lawyers’ billable hours is OpenAI, with the company striking a licensing deal with the FT. The arrangement will allow OpenAI’s models to respond to questions with short summaries from FT articles and to link back to the source material, the fifth such arrangement the company has reached with a news publisher. Meanwhile, Reddit has warned that it will consider suing any company that uses its data for training purposes without authorization.
But if this kind of peaceful de-escalation doesn’t work, lawmakers may attempt to resolve these issues. Representative Adam Schiff has introduced the Generative AI Copyright Disclosure Bill, with the backing of various artists and writers unions, which will compel anyone training a model to disclose any copyrighted material used in a public database.
Whatever you think of copyright, the Bill as currently drafted is a case study in how not to navigate these questions. Considering how US copyright law works, it would likely require the disclosure of any works used to train an AI system, regardless of fair use considerations. Not only would this obliterate any commercial confidentiality, it would be prohibitively slow and expensive. While there may one day be a case for legislation on this issue, a loosely drafted five pages probably isn’t going to cut it. Having said all of this, it is likely that by the time legal action would run its course, various generative technologies and products will have diffused so broadly in the economy that it’ll be too late to roll them back. Today, we’re basically in the pre-banning era of doping in competitive sports. Until bans are put in place, participants will juice themselves up as much as possible because everyone else is doing it. Ultimately, big companies will be in a position to pay potential fines, just like they’ve done with GDPR, and move on.
🍪 Hardware
Despite ever tightening US restrictions, high-end NVIDIA chips still have a habit of showing up in China. Tender documents reveal that Chinese government-linked entities have been acquiring NVIDIA chips by buying server products from Super Micro, Dell, and others via resellers. It’s not clear how or when these ended up in the hands of resellers, but it illustrates the challenge of having visibility into the downstream supply chain. Putting aside the China issue, it drives home just how challenging AI governance proposals based on hardware control would be in practice.
That said, the Chinese government isn’t gambling on its ability to exploit loopholes in perpetuity. Officials in the Ministry of Industry and Information Technology have directed the nation’s telecoms carriers to strip foreign processors out of their networks and switch to local alternatives, in a move that will primarily hit AMD and Intel. With China accounting for 28% of Intel’s revenue and 15% of AMD’s, it’s a reminder that the technology wars have the potential to spiral beyond AI and that there will be losers on both sides. Decoupling is both practically challenging and financially destructive.
However, chipmakers have little choice. They’re reluctant players in the US government’s game of sanctions whackamole. Intel is gearing up to release two new sanctions-compliant chips later this year, while NVIDIA has plans for another three. Considering US Commerce Secretary Gina Raimondo has already said that “if you redesign a chip around a particular cut line that enables them to do AI, I’m going to control it the very next day”, it seems likely that many of these will go the same way as their predecessors.
Beyond US-China, the Indian government is exploring the possibility of building a GPU cluster for start-ups, researchers, and academic institutions, with access offered at a subsidized rate. This follows on from the country’s decision in March to spend over $1 billion to buy 10,000 NVIDIA GPUs for use via public-private partnerships.
While we commend the ambition, it’s always worth stopping to ask, as the Ada Lovelace Institute did recently: compute, what is it good for? The authors point out that spending big on a compute cluster is all well and good, but this needs to be accompanied by a sense of the intended public benefit and how this is likely to be realized. We’re already hearing reports of companies and investors acquiring GPUs before struggling to find a use for them. Governments need to be careful to avoid a cargo cult mentality in AI hardware.
However, if Mark Zuckerberg’s to be believed, none of this really matters. In his interview for the Dwarkesh Podcast to mark the launch of Llama 3 (more on that later), he talked about how Meta went on a GPU acquisition spree, essentially on the off-chance the company needed them, before generative AI was even on their radar. At the time, the company was attempting to optimize Reels and close the gap with TikTok, but deliberately overbought to create spare capacity. This proved to be a wise decision. But will it ultimately create a GPU supply overhang internally at Meta?
In the same interview, Zuckerberg talked about how we’ll one day move from a world of 50-100 MW data centers to 1GW - roughly equivalent to the size of a nuclear power plant. The scale of investment required to make this happen will be eye-watering and would ensure national AI leadership is strongly correlated with energy price. This would be good for the US, even better for China, and terrible for much of Europe.
🏭 Big tech start-ups
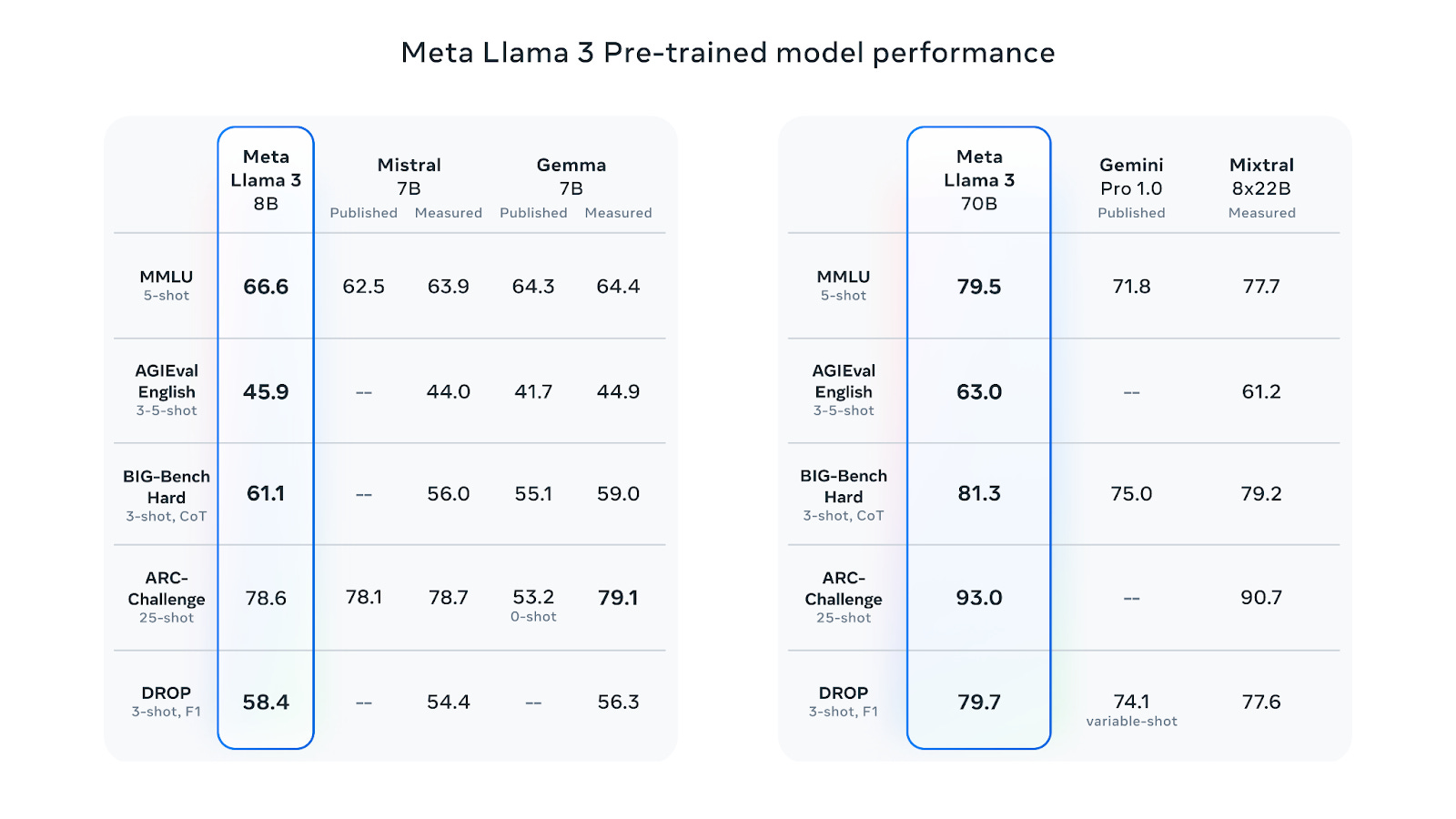
April finally saw the long anticipated launch of Meta’s Llama 3, with the company releasing the 8B and 70B models, with 400B+ models to follow later in the year.
While the full paper will not be released for a few months, Meta disclosed that Llama 3 was trained on 15T tokens (up from 2T), using a similar architecture to Llama 2, with refinements to improve language encoding efficiency and the use of grouped query attention across both the 8B and 70B models. 15T tokens represents more data than is thought to have been used for GPT-4 and is absolutely massive for an 8B model. Meta themselves acknowledge that this is significantly in excess of the “Chinchilla-optimal” amount of training compute, but say that both the 8B and 70B parameter models continued to improve log-linearly up to 15T. At a little over 8k, the context window remains shorter than most of its peers, but Meta says this will change in future releases.
The resulting model convincingly beat out Gemma, Claude 3 Sonnet, Gemma, and Gemini 1.0 Pro (and 70B Instruct against Gemini 1.5 Pro) across a range of benchmarks and it’s proving a hit in the community, as the highest-ranked open model on the LMSYS leaderboard.
Meta paired the announcement with the launch of their new Meta AI assistant, which they are billing as the most powerful freely available chatbot. It is also being integrated into WhatsApp, Messenger, or Instagram, but is currently geographically restricted. The integration already sparked a little controversy, with the standard litany of complaints about either accuracy or misinformation quickly surfacing. However, as far as we can tell, people are yet to identify many Meta-specific gripes at this stage.
Llama 3 may have long been anticipated, but a few days later, a new entrant to the enterprise LLM wars unveiled itself: Snowflake. The company’s new Snowflake Arctic impressed observers with its performance on tasks like coding and instruction, combined with its low training costs (sub-$2M). The model was built using a dense Mixture-of-Experts Hybrid architecture, combining a 10B dense transformer model with a residual 128×3.66B MoE MLP. On their chosen set of enterprise benchmarks, they found the model beat out Llama 3 8B and Llama 2 70B along with DBRX.
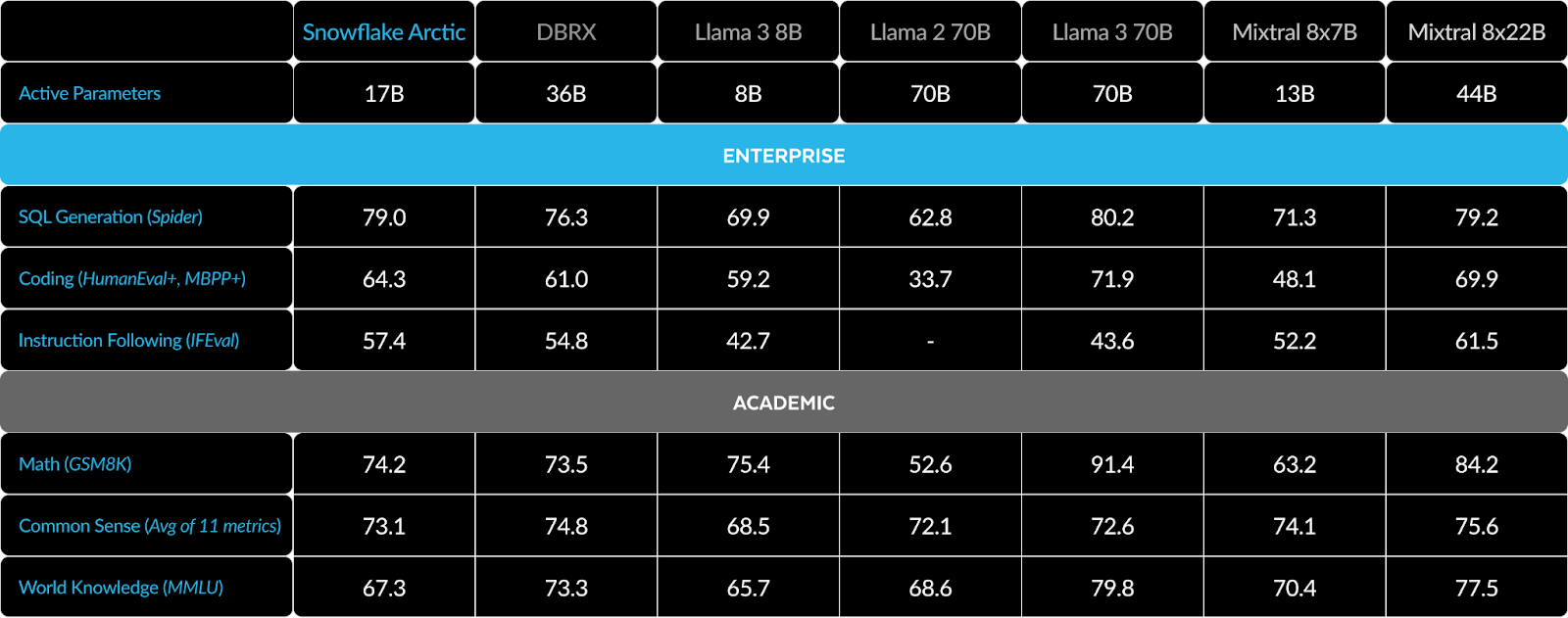
The company has released the model, along with ungated access to weight and codes via an Apache 2.0 license.
While we may have been stretching the definition of start-up beyond breaking point for the first two items, magnet link maestros Mistral definitely qualify. Mixtral 8x22B is a new open sparse MoE model, which only employs 39B active parameters out of 141B. It outperforms Llama 2 70B and Cohere’s Command R models across a range of common sense, reasoning, and knowledge benchmarks. It also has impressive multilingual capabilities. As is always the case with Mistral, the most impressive metric appears to be the performance/cost ratio.

Meanwhile, it’s been a busy few weeks for Elon Musk’s Xai. Not only are they allegedly approaching the close of a $6B fundraise at a valuation of $18B, but they released a preview of Grok-1.5 Vision, the company’s first multimodal model. Available soon to testers and existing Grok users, the model is competitive with GPT-4V and Gemini Pro 1.5 across a range of traditional benchmarks.

The eagle-eyed will spot an unfamiliar benchmark in the list. That’s because, to demonstrate its robustness in the real world, Xai created a new one - RealWorldQA - consisting of over 700 images with accompanying questions and answers. This came just a day after Meta released a new benchmark for vision language models, which uses open vocabulary questions to assess an AI agents’ ability to understand and communicate about the world it sees.
Beyond the world of model releases, something interesting is happening in the world of AI and biopharma. Xaira Therapeutics has emerged from stealth with over $1B in funding. Led by Marc Tessier-Lavigne, former president of Stanford and chief scientific officer at Genentech, the company will be building on technology from David Baker’s famous protein science lab at the University of Washington. The company is being advised by a range of luminaries, including a former FDA head, a Nobel laureate in chemistry, and a former Johnson and Johnson CEO. While the company is keeping the details of its pipeline under wraps, as one of the biggest ever bets on AI and drug design, we’ll be watching closely.
🔬Research
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, Microsoft.
Introduces phi-3-mini, a 3.8B parameter language model that achieves performance rivaling much larger models like GPT-3.5 and Mixtral 8x7B, while being small enough to run on a smartphone.
The authors specify that the model was deployed and tested on an iPhone 14 with an A16 Bionic chip. To enable on-device inference, the model was quantized to 4 bits, reducing its memory footprint to approximately 1.8GB. This quantized version of phi-3-mini was able to generate more than 12 tokens per second on the iPhone 14.
phi-3-mini was trained on 3.3 trillion tokens of heavily filtered web data and synthetic data, building upon the approach pioneered with the earlier phi-2 model.
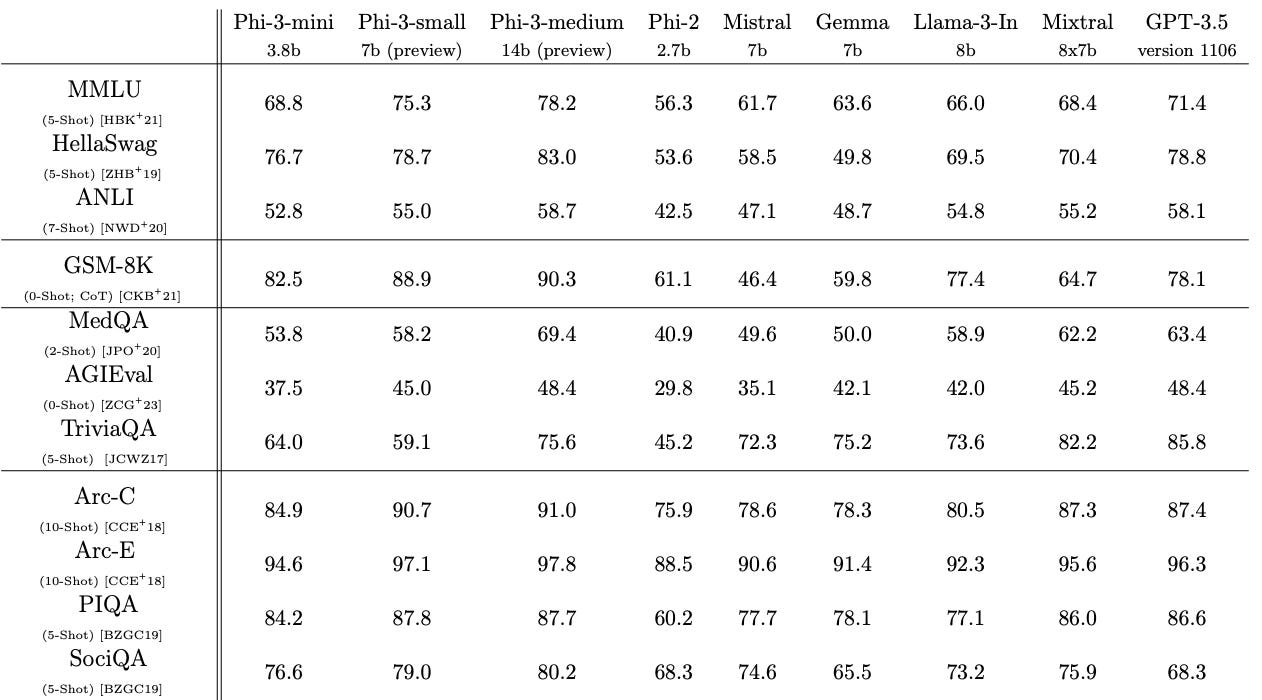
While performing well on benchmarks testing reasoning and question-answering, its small size limited its ability on factual knowledge, compared to larger models. The authors also provide initial scaling results with 7B and 14B parameter models (phi-3-small and phi-3-medium) trained on even more data (4.8T tokens). These larger models exhibit further improvements in capability.
Capabilities of Gemini Models in Medicine, Google DeepMind and Google Research.
Presents Med-Gemini, a new family of multimodal models for medicine, developed by fine-tuning Gemini Pro 1.0 and 1.5. The researchers used a combination of instruction fine-tuning on medical datasets, self-training to improve complex reasoning, and integration with web search to access up-to-date information.

For language tasks, they used datasets like MedQA, MIMIC-III clinical notes, and expert-written summaries to train Med-Gemini-L and Med-Gemini-M. For multimodal tasks spanning radiology, pathology, dermatology and other specialties, they fine-tuned Med-Gemini-M on datasets like MIMIC-CXR, Slake-VQA, Path-VQA and others. They also developed Med-Gemini-S with a custom encoder to process ECG waveforms.
On the MedQA benchmark of complex clinical reasoning, Med-Gemini-L achieved a new state-of-the-art accuracy of 91.1%, surpassing the prior best result of GPT-4 with specialized prompts. Careful relabeling of MedQA by clinicians revealed around 7% of questions had quality issues. Accounting for these, the model's performance is even higher. The strong reasoning capabilities generalized to other benchmarks like the New England Journal of Medicine (NEJM) diagnostic challenges.
For multimodal tasks, Med-Gemini established new state-of-the-art results on 5 out of 7 datasets evaluated, with an average 44% relative improvement over GPT-4.
Harnessing Gemini's long-context capabilities, Med-Gemini could process lengthy electronic health records (EHRs), achieving high precision and recall in retrieving rare findings - a challenging "needle-in-a-haystack" task. It also demonstrated strong results on medical video understanding, including surgical phase recognition and medical question answering.
Beyond benchmarks, Med-Gemini showed promising early results on tasks with real-world utility. These include generating high-quality clinical visit summaries, referral letters, and plain-language medical research synopses. In a preliminary study, clinicians found Med-Gemini's outputs to be on par with or better than human-written examples in most cases.
The Open DAC 2023 Dataset and Challenges for Sorbent Discovery in Direct Air Capture, Meta and Georgia Institute of Technology.
Introduces ODAC23, a collection of over 38 million quantum chemistry simulations, that’s built using physics-based computational chemistry methods. These simulations focus on how carbon dioxide and water molecules stick to the surfaces of more than 8,400 different porous materials known as metal-organic frameworks (MOFs). MOFs have long been thought to have potential applications in direct air capture. But due to the vast chemical space and the intricacies of understanding humidity and temperature, the discovery of promising MOF sorbents has proved challenging.

The authors use the ODAC23 dataset to train a series of graph neural networks to predict the strength of adsorption and forces between the MOFs and gas molecules. Their best models offered comparable accuracy to traditional quantum chemistry calculations, while being significantly faster. The researchers were able to identify 241 MOFs of exceptionally high potential for direct air capture. The dataset and the baseline models have been released openly.
Design of highly functional genome editors by modeling the universe of CRISPR-Cas sequences, Profluent.
Introduces OpenCRISPR-1, the world’s first open-source, AI-generated gene editor. Profluent used their proprietary LLMs, trained on a curated dataset of over 1 million CRISPR operons (gene editing systems), mined from 26 terabases of assembled microbial genomes and metagenomes, to generate thousands of diverse CRISPR proteins.
They generated 4.8 more protein clusters across CRISPR-Cas families than are found in nature, including some that are over 400 mutations away from any known natural protein. After characterizing their generations in the wet lab, they found a number of the gene editors’ performance was comparable or superior to SpCas9, the prototypical CRISPR gene editor.

OpenCRISPR-1, Profluent’s top hit, exhibited up to 95% editing efficiency across cell types, with a low off-target rate, and is compatible with base editing. This means the editor has the precision required to change a single DNA base pair without fully cutting the DNA double helix, reducing the possibility of unwanted insertions or deletions. Profluent is making OpenCRISPR-1 available for free for commercial and research use.
Also on our radar:
OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework, Apple. Introduces a new open-source language model family, which uses layer-wise scaling to optimize parameter allocations within transformer layers. The researchers find that a 1.1B parameter OpenELM outperforms comparable models like OLMo with 1.2B parameters, while using half the pre-training tokens. Apple have released the complete training and inference framework, along with code, logs, and pre-trained checkpoints on public datasets.
Anatomy of Industrial Scale Multilingual ASR, Assembly AI. Presents Universal-1, the company’s new multilingual speech-to-text model. The model was trained via a two-stage process of unsupervised pre-training on 12.5 million hours of unlabeled multilingual data, followed by supervised finetuning on a large-scale labeled dataset. It saw error rates as low as 5% across English, Spanish, French, and German.
Vision-language foundation model for echocardiogram interpretation, Cedars-Sinai Medical Center, University of California San Francisco. Presents EchoCLIP, a vision-language model that learns the relationship between cardiac ultrasound images and expert interpretations. After training on over 1 million ultrasound videos and corresponding expert reports, EchoCLIP demonstrated strong performance on various benchmarks for cardiac image interpretation without task-specific training.
ChatNT: A Multimodal Conversational Agent for DNA, RNA and Protein Tasks, InstaDeep. Introduces ChatNT, a novel multimodal conversational agent that can handle DNA, RNA, and protein sequences to solve a range of biologically relevant tasks. It combines a pre-trained DNA encoder, an English language model decoder, and a novel projection layer to map between the DNA and language embedding spaces. The researchers curated a new genomics instructions dataset covering 28 tasks across DNA, RNA, and proteins from multiple species, framed in natural language. ChatNT matched or exceeded specialized models on most tasks.
Many-Shot-In-Context Learning, Google DeepMind. Investigates the potential of many-shot-in-context learning, where LLMs are provided with hundreds of thousands of examples at inference time, in contrast to more commonly-explored few-shot setting. They find significant performance gains across a range of tasks, including machine translation, summarization, math problem-solving, and sentiment analysis. To avoid a bottle-neck in the volume of human-generated output, they also introduce reinforced and unsupervised in-context learning to mitigate the need for large amounts of human-generated data.
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions, OpenAI. Proposes an instruction hierarchy for model training to prioritize higher-privileged instructions over lower ones when they conflict. System prompts from developers receive the highest privilege, user inputs medium, and third-party content like web search results at the lowest level. This is designed to prevent prompt injections, jailbreaks, and other adversarial attacks.
A Careful Examination of Large Language Model Performance on Grade School Arithmetic, Scale AI. In response to growing concerns that impressive LLM benchmark performance stems from dataset contamination, this work introduces a new benchmark called Grade School Math 1000 (GSM1k) that mirrors the style and complexity of the established GSM8k benchmark. The results found that Mistral and Phi models were the most likely to suffer from apparent over-fitting, while Gemini, GPT, and Claude saw little change in performance (and even some improvement) against the new benchmark.
A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets, Université Côte d’Azur and TU Wien. While 3D Gaussian splatting offers high visual quality, fast training times, and the ability to render scenes in real-time, its resource-intensiveness makes it hard to render large scenes with good visual quality. The authors introduce a new approach that uses a hierarchy of 3D Gaussians, which enables them to train large scenes in independent chunks, which are then consolidated. This allows them to maintain quality and real-time performance. The hierarchical approach also allows for efficient Level-of-Detail rendering and smooth transitions between different levels of detail.
LINGO-2: Driving with Natural Language, Wayve. Introduces a closed-loop Vision-Language-Action-Model to help explain and determine driving behavior. The model combines driving and action language to provide continuous commentary over motion planning decisions, while also controlling the car. This marks an advance on LINGO-1, which was able to retrospectively generate commentary, but was not integrated with the driving model.
💰Startups
🚀 Funding highlight reel
Andesite AI, an AI cybersecurity analytics platform, raised a $15.2M Series A, led by General Catalyst and Red Cell Partners.
Celestial AI, working on ‘memory fabric’ for compute, raised a $175M Series C, led by the US Innovative Technology Fund.
Coreweave, the AI cloud computing company, raised a $1.1B funding round, led by Coatue.
Cognition, building software agents that can write and fix code, raised a $175M venture round at a $2B valuation, led by existing investor Founders Fund.
Cyera, creating an AI-powered data security platform, raised a $300M Series C, led by Coatue.
DeepCure, using AI to advance small molecule drug discovery, raised a $24.6M Series A1, led by IAG Capital Partners.
Fireworks AI, building an open source API for generative AI, raised a $25M Series A, led by Benchmark.
FlexAI, helping start-ups build systems on chips from different providers, raised a $30.5M seed round, led by Heartcore Capital, Elaia, and Alpha Intelligence Capital.
FYLD, an AI-powered observation and analytics platform for the infrastructure sector, raised a $15M strategic investment from the Ontario Teachers’ Pension Plan.
G42, the AI and cloud computing firm, raised $1.5B in investment from Microsoft.
Lumana, creating AI-powered video surveillance and safety technology, raised a $24M seed round, led by Norwest Venture Partners.
Mentee Robotics, building humanoid robots, raised a $17M venture round, led by Ahren Innovation Capital.
Oden Technologies, the manufacturing data analysis start-up, raised a $28M Series B, led by Nordstjernan Growth.
Perplexity, the AI-powered search tool, raised a $62.7M Series B1 round, led by Daniel Gross.
Robovision, building a computer vision platform for industrial automation, raised a $42M Series A, led by Target Global and Astanor Ventures.
SiMa.ai, a start-up producing chips for edge AI applications, raised a $70M Series C, led by Maverick Capital.
Symbolica, building symbolic models for enterprise, raised a $33M Series A, led by Khosla Ventures.
Vizcom, creating an AI-powered tool for industrial designers and artists, raised a $20M Series A, led by Index Ventures and Unusual Ventures.
Xfactor, the start-up building a unified revenue platform, raised a $16M Series, led by Mike Carpenter and Accel.
🤝 Exits
Darktrace, the London listed AI-powered cybersecurity company, is to be acquired by private equity group Thoma Bravo for $5.3B, which is roughly 2x from its IPO price in 2021.
Deci AI, a start-up compressing models to ensure they run more efficiently, is to be acquired by NVIDIA.
Run.ai, working on GPU optimisation by allowing developers to run workloads parallel, is to be acquired by NVIDIA for $700M.
Signing off,
Nathan Benaich and Alex Chalmers 5 May 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | London.AI
Air Street Capital invests in AI-first technology and life science entrepreneurs from the very beginning of your company-building journey.
