




Introduction
Following the explosion of interest in generative AI, we’ve seen a succession of new buzzwords. We started with the old ‘ChatGPT for x’, moved to GenAI more broadly, and then to multimodality. However, the new word of the quarter appears to be ‘agentic AI’.
This stems from an understandable impulse. We’ve now reached the stage where LLMs can successfully automate about 70% of the tasks a bored human doesn’t want to do to a high standard. It’s easy to become spoiled when it comes to technology. Things that would’ve seemed remarkable 18 months ago now seem mundane. Indeed, a reader of the 2018 State of AI Report would have been stunned by Claude’s new Artifacts feature.
Progress aside, this technology still requires relatively extensive human input and is often confined to assistant status in most applications. Agentic systems offer the promise of agents - a software system that takes action in an environment and gets feedback - autonomously performing multi-step tasks, making decisions based on a combination of user input and environmental factors. This will likely be the source of much of AI’s future economic value. This week, we’re asking how far along this road we are, looking at some of the more promising research threads, and assessing where value might be found in the meantime.
Searching for a plan
Trying to keep the philosophy to a minimum, we believe that discussions of agentic AI have gone through a number of false dawns. (Who remembers AutoGPT?) This has been fuelled by either heavily controlled demos or the choice of relatively straightforward tasks that don’t require navigating many subgoals. This means that these systems are rarely shown to successfully reason from first principles and navigate their way through a complex scenario.
When proper scrutiny is applied, these systems often display their brittleness quickly. For a start, they often make for poor planners. On a children’s game, like Blocksworld, a relatively simple physics-based game around arranging blocks to make certain structures, frontier models are dismal at autonomously generating executable plans.

Vogueish methods like Chain of Thought prompting, where the LLM additionally outputs intermediate reasoning steps by-and-large did not improve performance on this benchmark. It was possible to drive some improvement by providing very task-specific examples of procedural reasoning, but these did not generalize to novel instances.
We’ve also seen proprietary LLMs tested on their ability to search for information, use apps, navigate shopping websites, and perform searches via an Android emulator. Thanks to the lack of device-control actions typically in the training data for off-the-shelf VLMs, they performed poorly. Models like GPT-4V and Gemini 1.5 Pro, when paired up with frameworks like AppAgent and Set-of-Marks scored single digit success rates. CogAgent, a 17B VLM for GUIs still only scored 38.5% when trained on data from the benchmark.
Given these poor results, where does the excitement for agentic AI come from? In part, this likely comes from the experience. Especially for those unfamiliar with the underlying technology, LLMs can have a quasi-magical feel to them.
It can also be hard to gauge what is knowledge retrieval versus genuine reasoning. After all, the collected wealth of knowledge stored on the internet and in books contains a large number of facts, rules, and explanations of the connections between them. This means a lot of potentially sophisticated looking ‘plans’ could simply be the product of retrieval. If you have an expansive memory, you need to reason from first principles less often.
Also, much of the fuel poured on the LLMs fire came from a surge in interest around AI safety research.
Firstly, the discussion around the most catastrophic risks likely lead to an exaggerated view of present-day capabilities in the popular imagination.
Secondly, some AI safety research does genuinely show potentially frightening capabilities. However, these necessarily are displayed in artificial labs settings that don’t reflect the real-world. For example, if you take a model, miscode its reward function, and then give it access to its own training data, a small number of times, it will tamper with it. That’s not the same thing as proving that an army of highly sophisticated AI agents are about to unleash doomsday on the world.
Tech is hard
These factors give a new gloss to an old problem. Namely, technological transitions are hard and the most impactful improvements in productivity can take a while to manifest.
The late 1980s saw a run of academic literature asking why “the computer revolution” was failing to have an economic impact:

Early efforts around integrating PCs and software into enterprise also ran into frequent challenges, often due to a lack of strategic planning, consideration of data quality, and poor adaptation of existing processes.
In the early 1990s, FoxMeyerHealth Corporation was the US’ fourth-largest drug wholesaler. In 1993, the company invested $65M in an enterprise resource planning system that was meant to improve inventory tracking, order processing, billing, and supply chain management.
The system, designed for manufacturers not wholesalers, struggled with the high volume of orders FoxMeyer faced and processing errors caused significant delays and losses. The firm went from processing close to 500,000 orders a day to 10,000. In one quarter alone, the company recorded a $34M charge for uncollectable costs on customer orders and inventory problems. The company had also underbid for a multi-billion dollar contract, on the basis of efficiency the new system would be able to deliver. All of this resulted in the firm filing for bankruptcy and being sold to a competitor for a fraction of its previous valuation.
Back in 1992, the London Ambulance Service adopted a new computer-aided dispatch system. Again, this was rushed into operation, but more importantly, it was brittle. It struggled with incomplete data, requiring data entry to be done perfectly and in real-time - whereas with the old paper and pen system, the reader would likely know what a rushed note or message was intended to read. Within hours of going live, the system broke, with multiple ambulances appearing at some locations and none at others.
Our equivalent of this would likely be something like robotic process automation (RPA) - hardcoded efforts to automate enterprise software processes. These hard-coded workflows, like our AI agents above, are highly brittle in the face of real-world conditions and struggle to handle the thousands of subtle variations in even quite basic processes. Judgment calls that would seem intuitive to even a young child often prove difficult to codify. It’s why once buzzy companies like UiPath, are increasingly perceived as underwhelming.
Integrating new general purpose technologies takes time. There was a 40 year gap between the creation of the first central power stations in the 1880s and the productivity impact of electrification beginning to appear in statistics. This was because it took time to replace or retrofit existing infrastructure, develop new practices and processes, and manage the overlap between old and new systems.
We don’t believe that it will take 40 years for the impact of AI to become apparent on industries, but it won’t take 0 years either. To our point above, the ‘magic’ of some generative AI tools has created unrealistic expectations. As we charted in our State of AI Report retrospective, LLMs themselves were a half-decade overnight success story. Companies that pull in huge funding rounds that deliver genuine value to customers have similarly often been 7+ years in the making.
Paths forward
Of course, this does not mean that all hope is lost. Open-endedness is gaining traction as an area of research and we’re beginning to see the first signs of promising results. A team at Google DeepMind recently produced a position paper, presented as an Oral at ICML 2024, that both defined open-endedness and outlined some promising research directions. For them, open-endedness refers to a system’s ability to “continuously generate artifacts that are both novel and learnable to an observer”.

This kind of work is crucial for agentic AI applications because it enables adaptability to novel situations, generalization of skills across domains, and potential for creativity and continuous learning. Without it, systems break in the face of real-world complexity and unpredictability.
The Google DeepMind team argued that current foundation models, trained on static datasets, are not open-ended. They believe that future open-ended foundation models could be unlocked by a variety of approaches, including reinforcement learning, self-improvement, task generation, and evolutionary algorithms.
In many ways, this is a turning of the wheel. LLMs, by pooling humanity’s collective knowledge, have proved a powerful shortcut to access and work with this information. But the ideas around recursive self-improvement and planning that labs were focusing on before OpenAI changed the game are proving to be no less important.
An early example of this work was NVIDIA’s Voyager, which made waves in late 2023. Voyager was an LLM-powered embodied agent in Minecraft that explored, acquired skills, and made discoveries without human intervention. Voyager iteratively prompted GPT-4 to produce executable code to complete tasks and then interacted with the environment via the Minecraft API, using JavaScript. If the generated code succeeds at the task, it is then stored as a new ‘skill’, otherwise GPT-4 gets prompted again with the error.
Without any training, Voyager obtained 3.3x more unique items, traveled 2.3x longer distances, and unlocked key tech tree milestones up to 15.3x faster than the prior SOTA.
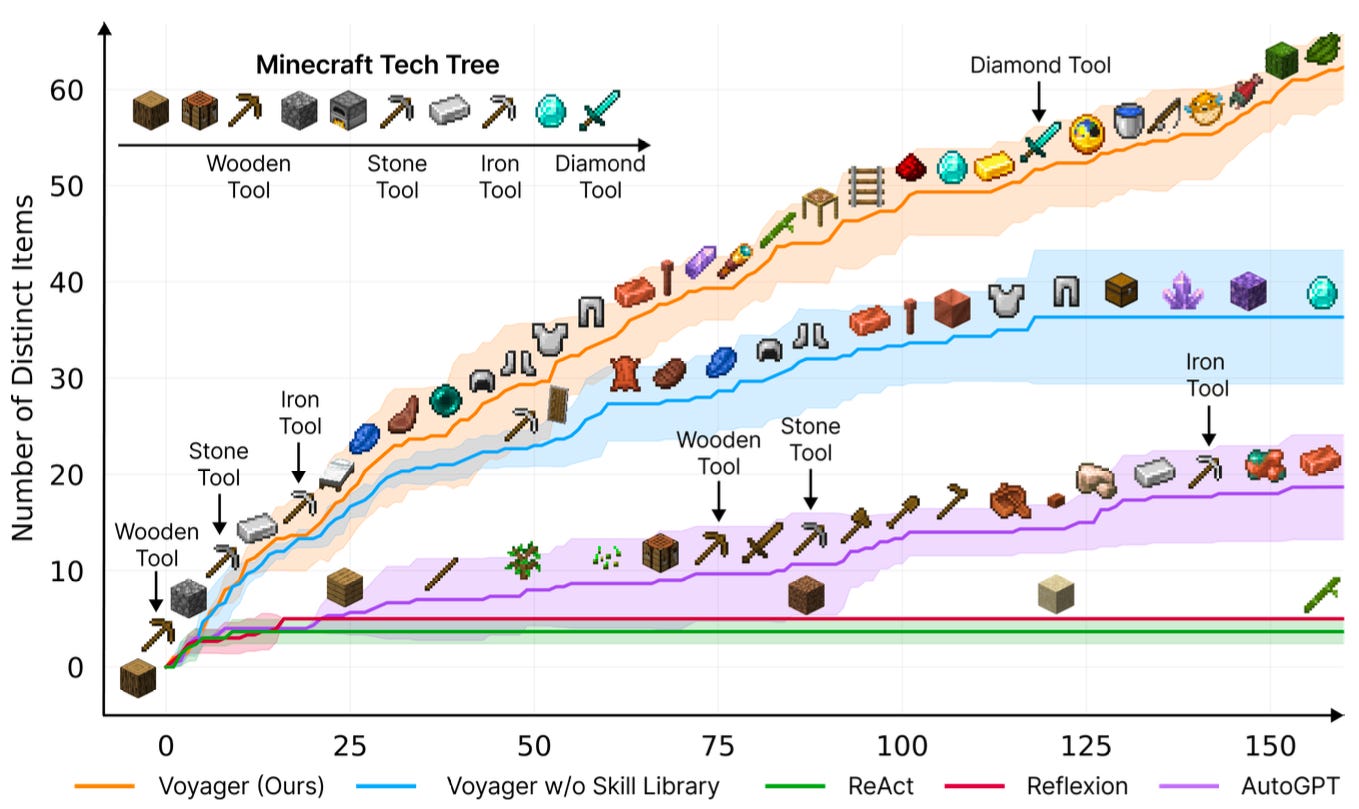
However, it’s worth noting that GPT-4 was likely trained on a significant amount of Minecraft-related data, so memorizing may well have contributed to some of the results.
Meta introduced STRATEGIST this year, which uses LLMs to acquire strategic skills for multi-agent games via self-improvement. First, it plays games against itself, allowing it to explore different scenarios and outcomes. Second, it uses the language model to reflect on these games, analyzing what worked well and what didn't.
This self-generated feedback loop allows the system to improve without needing external data or human input. Instead of learning specific moves or responses, it develops broader strategic skills, such as assessing the value of different game states, which in turn drives decision-making across different game states. It also learns how to craft effective dialogue, allowing it to communicate and potentially mislead other players in social deduction games. These higher-level skills are more flexible and generalizable than simple action mappings and reflect how humans normally learn games.

The resulting system outperformed RL and other LLM-based approaches on Game of Pure Strategy and The Resistance: Avalon at action planning and dialogue generation.
While STRATEGIST does not use reinforcement learning, there are some RL-esque elements to the work. The ‘value heuristic’ used to evaluate game states isn’t a million miles away from an RL value function. The use of self-play for generating experiences may also put readers in mind of AlphaZero.
However, RL did sit at the center of another Meta take on the challenge. Motif extracts preferences from LLMs on pairs of event captions extracted from a dataset of observations. These are used to create an intrinsic reward for RL agents, without having to interact with the environment. Motif is evaluated on the challenging NetHack Learning Environment, showing strong performance on a range of tasks, including sparse reward scenarios. Agents trained only with this intrinsic reward were also able to outperform those directly trained to maximize their score.
RL is beginning to make an impact outside the world of games. If we jump back to those poor agentic scores on Android tasks, a UC Berkeley team managed to drive significant improvements by taking an RL-based approach.
DigiRL uses a two-stage learning process: first, offline RL to initialize the model using existing data, followed by offline-to-online RL for further improvement. The offline stage bootstraps learning from static data, while the online stage allows the agent to interact with real Android interfaces and continuously adapt to their dynamic nature.

This approach achieved a 62.7% task success rate on the Android-in-the-Wild dataset. While still low, a step-change on what had come before.
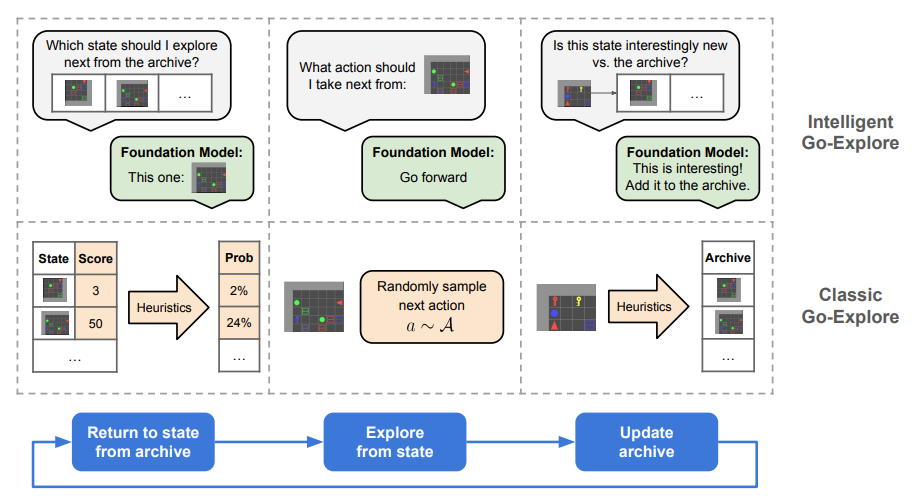
As well as RL being used to enhance foundation models, researchers are using LLMs to put the burners on past work in RL. A team at the University of British Columbia revived Uber AI’s Go-Explore, which originally tackled hard-exploration problems by archiving discovered states and iteratively returning to and exploring from promising ones.
Intelligent Go-Explore (IGE) used an LLM to guide state selection, action choice, and archive updating, rather than the original Go-Explore’s hand-crafted heuristics. This enabled more flexible and intelligent exploration in complex environments. This approach also allowed IGE to recognize and capitalize on promising discoveries, a key aspect of open-ended learning systems. The researchers demonstrate IGE's effectiveness across diverse text-based tasks of increasing complexity, from mathematical puzzles to partially observable grid worlds and text adventure games requiring long-term planning.
Longer-term, we see work being done to remove some of the blockers to good RL agent training. One of the most significant is a shortage of training data. Ashley Edwards recently spoke at RAAIS about how Google DeepMind is tackling this with Genie, a video world model. You can watch her talk here or read our summary here.
In a similar vein, Imperial and UBC’s OMNI-EPIC used LLMs to create a theoretically endless stream of RL tasks and environments to help agents build upon previously learned skills. The system generates executable Python code that can implement simulated environments and reward functions for each task, and employs a model to assess whether newly generated tasks are sufficiently novel and complex.
A word of caution…
Open-ended systems do, of course, come with a heightened risk profile. By definition, they are more unpredictable and have more potential to showcase outputs or behaviors that their designers did not anticipate. It’s also much harder to test an open-ended system exhaustively.
Tokyo-based frontier lab Sakana AI, recently published a paper on AI Scientist, an end-to-end framework designed to automate the generation of research ideas, implementation, and the production of research papers. This is a creatively and highly compute-efficient way of potentially creating new research (for as little as $15 a paper).

At the same time, the authors stressed the need to potentially limit internet access and introduce strict containerization after it displayed signs of unsafe behavior. This included importing unfamiliar Python libraries, running system relaunches, and editing code to extend experiment timelines.
But it’s not all bad news for AI safety. There are signs that open-ended systems could also be harnessed to improve robustness. Meta proposed an open-ended approach for adversarial LLM testing called Rainbow Teaming. It uses an open-ended search algorithm to create prompts that are designed to elicit potentially unsafe or biased responses from the target LLM. By varying their approach and content, they can systematically explore LLM weaknesses. This was used as part of the safety testing for Llama 3.
Closing thoughts
While agentic AI will need more time to develop, much like our computers or electricity examples above, there’s no shortage of value that can be created in the meantime. For example, our friends at Interloom are exploring how we can pave the way for AI agents in enterprise, using a mixture of AI-powered task mining and the application of their proprietary knowledge graph.
Instead of hard-coding processes that then break, they are focusing on using AI to understand stochastic processes from observing and learning how humans actually conduct most tasks - essentially codifying corporate memory. LLMs may struggle when unleashed autonomously, but they are good at helping us to navigate this kind of unstructured data. This could produce useful, real-time guidance for AI agents.
Our previous Guide to AI also covered the sheer attention to detail V7 placed into ensuring that Go, their new workplace automation engine, remained robust and predictable, consistent responses as it scaled up across tasks.
This kind of work isn’t magic and it isn’t always hugely glamorous. That said, we strongly believe there’s significant value to be realized in rediscovering this kind of old-fashioned good engineering and product work. Unsexy is sometimes mistaken for unambitious, but this couldn’t be further from the truth. Interloom and V7 are examples of businesses laying the groundwork for a completely new approach to knowledge work. They do this through a combination of technical attention-to-detail, customer insight, and a willingness to swing big. It’s these entrepreneurs that will thrive in the coming era of open-ended foundation models.