




Prefer audio? Listen to this newsletter here
Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and startups over the last month. As ever, some news:
Thank you to everyone who came to our ICML dinner this year - it was great to see old friends and new. Sign up here to ensure you don’t miss future events, including NYC, SF, London, and Paris.
Don’t forget to subscribe to Air Street Press to receive all our news, analysis and events directly in your inbox. Recent pieces included a deep dive into the state of Chinese AI, the importance of non-consensus, and an overview of the work of our friends at Hedera Dx.
We’re releasing more and more of our content in audio form for those of you who listen on the go, or multi-thread modalities :-), including this newsletter - check it out on Spotify here.
While we work on the State of AI Report 2024, this summer edition covers our 8th Research and Applied AI Summit, held in London on 14 June.
The in-person event brings together 200 AI-native researchers, entrepreneurs, and operators for a day of talks, networking, and best practice sharing. It supports the RAAIS Foundation, a non-profit that advances education and the funding of open source AI for the common good.
We’re sharing a few key takeaways from the event, while videos of the talks can be found on the RAAIS YouTube channel. If you’re feeling inspired, you can pre-register your interest in next year’s event here.
As usual, we love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
—
Is reinforcement learning back?
A research direction we’ve been increasingly following is open-endedness. These describe systems that, to quote a recent Google DeepMind position paper, are able to “continuously generate artifacts that are novel and learnable to an observer”. Current LLMs are not open-ended, in the sense that they don’t create new knowledge (as far as we currently know), and their performance frequently degrades on out-of-distribution tasks where they are unable to rely on memory or retrieval.
Against this backdrop, it was fascinating to hear from Thore Graepel. Now Head of AI at longevity company Altos Labs, his main claim to fame is being one of the co-inventors of AlphaGo - the most famous early demonstration of reinforcement learning’s power. In his fireside chat with me, Thore reflected on what research directions had and hadn’t changed from then to now.

Thore observed that the current instantiating of agentic AI would be familiar to anyone who’d worked on RL in the past - none of the ideas are new. Ultimately, if we want agents to achieve goals, they will need to interact with an environment, collect information, and take actions according to some form of reward function. This is the RL framework.
We felt Thore put it nicely when he said that: “There's almost this irony that DeepMind, of course, was very focused on reinforcement learning, but then it turned out that drawing on the … crystallized proceeds of intelligence that have been produced and that are available on the internet - to draw on that first and train large models to extract knowledge out of that - turned out to be the faster short-term solution for making progress. But I don't think that means that we don't need to eventually also look at the good old ideas of planning and of recursively self-improving systems.”
As a result, Thore sees integrating LLMs into a multiagent framework as a promising research direction.
Without wanting to give away any spoilers, the limitations of LLMs on planning tasks, open-ended systems, and promising LLM/RL integrations will be a theme we return to in this year’s State of AI Report.
Video generation and world models
Next up: One of the big bottlenecks for training RL agents is a shortage of training data - standard approaches like converting pre-existing environments (e.g. Atari) or manually building them are labor-intensive and don’t scale. Ashley Edwards’ talk examines the possibility of leveraging LLMs to create diverse and rich interactive environments directly from video data - crystallizing some of the accumulated knowledge Thore referenced.

While video generation models now exist, they lack the capacity for fine-grained interaction. Meanwhile, world models often require videos or environments paired with actions (which again run into scalability issues).
By contrast, Genie (which went on to win a Best Paper award at ICML 2024) analyzes 30,000 hours of video game footage from 2D platformer games, learning to compress the visual information and infer the actions that drive changes between frames. By learning a latent action space from video data, it can handle action representations without requiring explicit action labels.
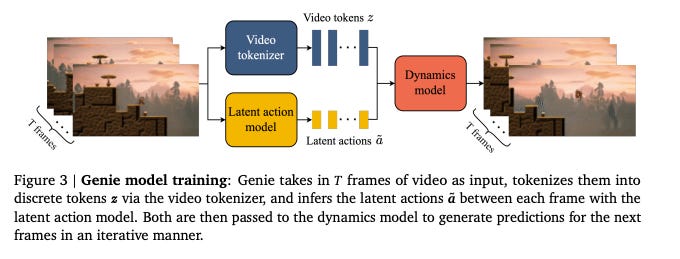
As well as recreating scenarios from its training data, Genie is able to imagine entirely new interactive scenes. The resulting system demonstrates significant flexibility; it can take prompts in various forms, from text descriptions to hand-drawn sketches, and bring them to life as playable environments. The system demonstrates an understanding of game mechanics, physics, and visual styles common in platformer games.
Ashley noted that the same approach carries over from games to real-world data. The team took the hyperparameters from the game model and were able to apply the model to robotics data, without fine tuning, with the same effect. This is pretty amazing.
Foundation models make waves in biology
As the world began to pour over AlphaFold 3, released shortly before RAAIS 2024, we had two speakers explain how their work was transforming each step of the drug discovery process.
Daniel Cohen, president of Valence Labs (part of Recursion Pharmaceuticals) took us through his team’s work toward their goal of developing autonomous systems capable of Nobel Prize-worthy insights into drug discovery.

The major challenge they face is that drug discovery is a low-data domain and there’s usually an inverse relationship between quantity of data and translation relevance in the drug discovery pipeline.
Moreover, drug discovery involves sifting through a vast array of candidate molecules each with many different medicinal properties that need to be optimized simultaneously to yield a potent drug. We can only empirically evaluate a small fraction of possible molecules in the lab. This leaves us with incomplete data for most combinations of properties, and as far more molecules don’t work than do, this creates datasets heavily skewed towards unsuccessful candidates.
This means drug discovery companies are limited in their ability to keep hitting the scale button and have to revive good old-fashioned ideas like algorithmic innovation. Turns out, this is Valence’s strength. During their life as a startup (which Air Street funded), they focused heavily on a mix of few-shot, meta, representation, and active learning. Teaming up with Recursion, however, gave them access to 25 petabytes of data and significant compute resources (in fact, the largest NVIDIA GPU cluster in all of biopharma).
In terms of research, the team is focused on three main areas:
Developing computational representations of biological and chemical systems, including accurate reconstructions of cellular images and molecular structures, with performance improving as they scale up data and computing power.
Querying and experimenting these representations in the real-world through efficient use of wet lab infrastructure to validate hypotheses and run experiments, with active learning prioritizing areas of higher uncertainty.
The use of LLMs for complex drug discovery workflows, enabling scientists to run sophisticated computational analyses.
A notable early achievement is the development of a DALL-E-like system for drug discovery, which can predict the biological effects of molecules and suggest molecules for desired biological perturbations.
Meanwhile, Karim Beguir, the co-founder and CEO of InstaDeep presented his team’s work on the application of AI to genomics. The advent of the transformer presented a particular opportunity to help us understand so-called ‘junk DNA’ - the less-understood majority of genomes that do not code for known proteins.

InstaDeep approached the problem step by step, integrating more modalities and functionality with time. They started with a nucleotide transformer, trained on multi-species genomic data using self-supervised learning techniques. It was one of the first applications of transformers to DNA and could distinguish different genomic regions and dutifully predict specific biological features. It was also able to outperform specialized protein prediction models using only DNA data.
They extended this work with SegmentNT, which added a segmentation head to the nucleotide transformer, inspired by vision models. This model was able to predict 14 classes of genomics elements at single nucleotide resolution, identifying functional regions within DNA, such as protein-coding genes and regulatory elements, with high accuracy.

They then saw the potential to combine this work with an open-source language model by projecting DNA embeddings into the language model. This allows users to ask natural language questions about genomic data, leveraging the strengths of both genomic and language models. The added contextual richness led to the integrated model outperforming the standalone model on 18 reference tasks.
The final piece of the puzzle was combining DNA and protein language models to improve predictions. By integrating embeddings from both types of models, they achieved superior performance, demonstrating the potential of multimodal approaches to capture complex biological information more effectively.
AI has the potential to abstract away boring and challenging tasks
As well as breakthrough research, we heard from teams that were successfully applying AI-first products to address real-world problems in enterprise - something many companies claim to be doing, but only a handful are doing well.
Our friend Simon Edwardsson, the CTO and Co-Founder of V7 Labs, talked about building and deploying Go. V7’s initial claim to fame was Darwin, its platform for manual and automated data annotation, but the team realized that frontier models could increasingly solve problems with less upfront training data.

Go is a workplace automation system that leverages multimodal foundation models, with a spreadsheet-like interface, where the columns are powered by either foundation models or code.
To avoid the classic enterprises challenges, they’ve dedicated significant resource into identifying and resolving specific hurdles, including:

Here’s a demonstration of the product in action:
Generative user interfaces
We were also joined by Jared Palmer, the VP of AI at Vercel, who focused on how AI is changing how software is built and experienced. He made the point that the definition of a "developer" is expanding to include a much broader audience due to the lowering barriers to entry in software development.

This is enabled by Vercel’s AI SDK, which provides an abstraction layer for developers to work with various AI providers without dealing with the complexities of different APIs and streaming formats. More excitingly, when combined with React Server Components, it can create dynamic and scalable interactions.
Crucially, it unlocks the potential for generative UI. The AI SDK’s ability to manage stateful interactions, where the AI maintains awareness of the current state of the interface and the ongoing conversation, is essential for useful, real-world applications. Jared demonstrated this with examples like the flight booking system and a financial advisor interface, where the AI could respond to changes in the UI state. It also allows for tool calls bound to specific React components. This means that when the AI decides certain information or functionality is needed, it can directly trigger the rendering of appropriate UI components.
Jared is also the inventor of V0, a tool that generates entire UI layouts and React code based on text prompts or screenshots.

V0 is designed to streamline the process of creating UIs by leveraging AI to translate high-level descriptions into functional code. He believes it will evolve to generate more interactive, stateful components - unlocking fully generative applications in the future. We’re particularly interested to see AI-first products built in this way. If you’re working on this, ping us :-)
…but productizing in AI is hard, requiring time and lots of self-belief

Selecting a good challenge involves swinging big and being prepared to work for several years before being vindicated. Our first speaker, Jonathan Starck, the CTO of Synthesia drove this home in his account of the company’s journey. 7 years ago, Synthesia had early confidence that we were moving into a video-first world, based on changing consumer habits and the boom in video content on social media, but there was little reason to believe AI-generated video would be easy.
Back in 2017, the state of the art generative adversarial networks produced short, low-quality video that was commercially unusable. In 2019, transformer-based models were just beginning to be used for single-image generation.
Jonathan walked through how Synthesia broke the problem down into manageable chunks to create value in the interim. Initially, they focused on using GANs to develop deep fake technology for lip-syncing so customers could dub a video into any language convincingly. It took another 2-3 years to get to text-to-video with avatars and then achieving product-market fit.
But as we showed in last year’s State of AI Report, once they found product-market fit a couple of years later they never looked back…

End-to-end learning is all you need?
Alex Kendall, Co-Founder and CEO of Wayve faced the unenviable task of taking a completely different approach to every other team working on self-driving. However, 7 years in, he’s raised a $1.05B Series C round, suggesting he’s clearly getting something right. He shared a few reflections on his entrepreneurial journey.

From day one, he was focused on the potential of end-to-end systems in self-driving, where a single neural network maps raw sensory inputs to driving actions, without explicitly programmed intermediate steps. It instead implicitly learns to perform tasks like object detection and path planning via a combination of supervised learning from human driving demonstrations and reinforcement learning, rather than these intermediate representations being hardcoded.
By contrast, other teams working on self-driving pursued a modular approach, where all these intermediate tasks were broken down into distinct steps, using their own models, some of which were hand-engineered.
However, Alex’s previous work in robotics led him to see the brittleness of these traditional approaches. It was possible to hack around parameters and thresholds to throw together plausible demos, but these systems disintegrated on first contact with the real-world. In the meantime, he’d seen the success of DeepMind’s end-to-end Deep-Q learning solve the control of Atari games, while his own personal experimentation with end-to-end image segmentation systems displayed successful generalization.
While parts of the approach changed as the field evolved (e.g. swapping out CNNs for multimodal transformers), the team had conviction that it was a question of if, not when, the field would start moving towards end-to-end.
When he started Wayve, he raised a £2.5M seed round. The feedback he received from the outside world was that he was wasting his time, given that others had raised billions to tackle the same challenge. He noted that resource constraint acted as a drug for innovation and now has the reverse challenge - preserving the same focus and efficiency at a time of abundance.