




Introduction
Veterans of AI Twitter know the cycle well by now:
A relatively obscure team announces a new technique or model;
They claim it rivals the performance reported by frontier labs, using a fraction of the compute and data;
They tout deliriously high MMLU scores in tweets full of fire emojis;
Everyone, minus a handful of hardened skeptics, is impressed for a few days;
No one is able to replicate the reported performance;
The finding is never discussed again.
Late last week, the AI world was rocked by yet another one of these cases. It stretched beyond a usual case of light overfitting, and gave the appearance (this is our opinion, don’t sue us) of being a case of genuine fraud. The story, in and of itself, is tragi-comic, but it also raises some important questions.
The Reflection story
On 5 September, Matt Shumer, the CEO of seed-stage AI assistant start-up HyperWrite (formerly OthersideAI), made a big announcement on X:
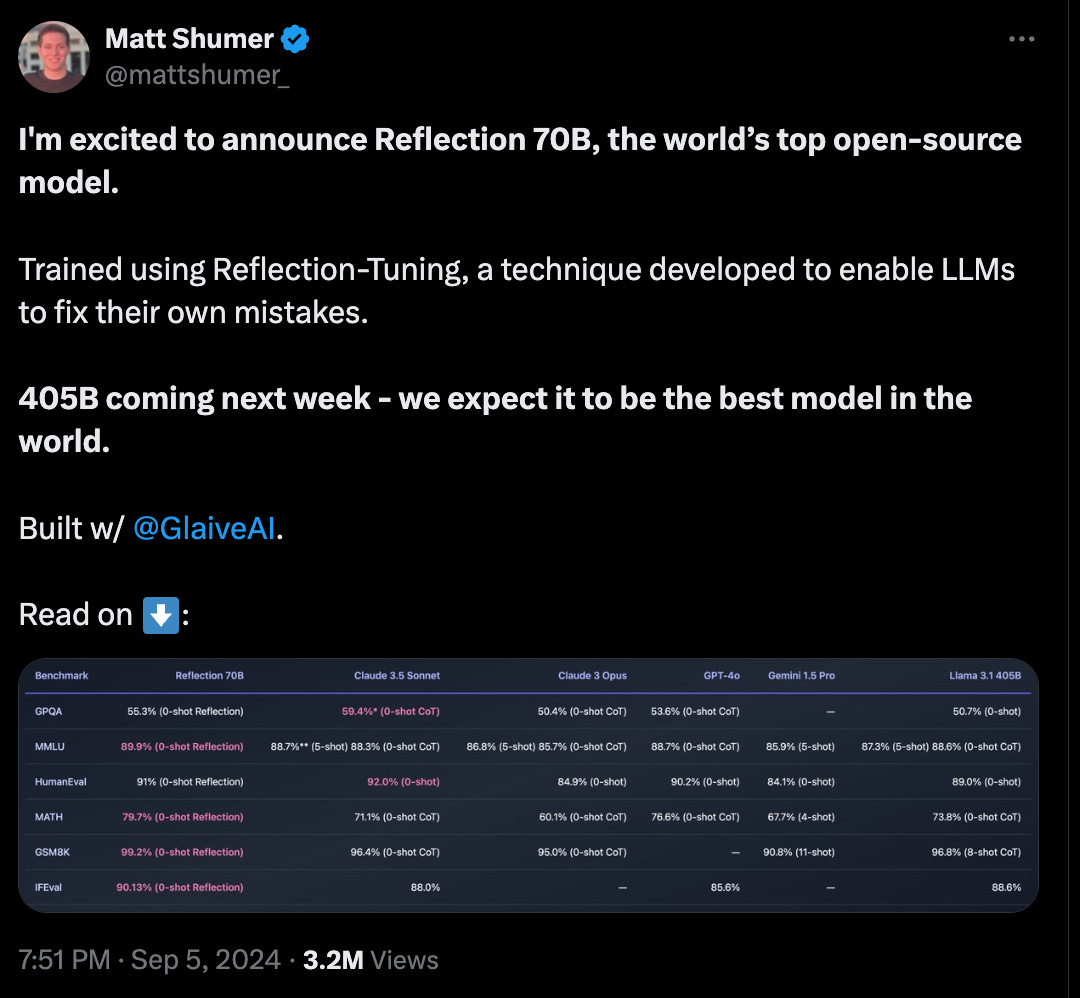
Shumer’s team claimed that Reflection 70B, their finetune of Llama 3.1-70B had been able to achieve unprecedented benchmark performance, including over 99% on popular math benchmark GSM8k via a simple error self-correction technique.
The idea is that by adding distinct phases of reasoning and reflection, whereby the model analyzes its own thought process, it can prevent hallucinations ever reaching the user. Shumer claimed to have used synthetic data generated by Glaive AI (in which Shumer is also an investor) in a matter of hours for the training process.

This new technique, branded ‘Reflection-Tuning’ (itself not a novel term) isn’t a wholly new idea. It overlaps conceptually with chain-of-thought prompting, where models output intermediate reasoning steps, as well as other explorations of LLM’s self-correction capabilities. While researchers have often reported improved performance on benchmarks after implementing these techniques, the jumps are not remotely comparable.
The model duly received an enthusiastic write-up from VentureBeat, which repeated Shumer’s claim that it was the “most powerful open source AI model in the world”, including his unverified claim that it was “rigorously” tested on multiple benchmarks “using LMSys’s LLM Decontaminator to ensure the results are free from contamination”.

Shumer’s tweets gained thousands of likes and retweets. Reflection 70B got glowing reviews from AI influencers and, within a day, became the #1 trending model on Hugging Face.
On the same day, Hyperbolic (the irony is not lost on us), a platform for fine-tuning and deploying LLMs announced that it was providing API access and members of Hyperbolic staff shared a number of tweets praising the model and continued to stand by Shumer, even after his story started to come apart. The first signs of doubt didn’t stop OpenRouter, an LLM aggregator and access point, starting to provide Reflection API access.
So, when did the community start to smell a rat?
In some cases, immediately. Some researchers instinctively looked at the reported benchmark scores and concluded that something was up.
The heat was turned up, when on 7 September, independent evaluators Artificial Analysis came to a startling conclusion: this finetuned version of Llama 3.1 70B appeared to be underperforming the base model and matching Llama 3’s MMLU score.

Artificial Analysis also tested the system prompt that allegedly unlocked these performance increases on a series of other models and found that it had no impact.
Shumer rushed to claim that a mistake had been made in the upload of the initial release, with the Hugging Face version apparently using multiple different models’ weights. Artificial Analysis were given access to a private API key to the ‘real’ version of the model. On 9 September, they found it performed better, but still fell short of the stated performance claims. However, they asked how a different version of the model had been published in the first place and clarified that they could not verify what sat behind the API.
But others, accessing the API version of the model via OpenRouter quickly discovered that “the most powerful open source AI model in the world” was in fact a Claude wrapper.

As people figured this out, the model behind the API appeared to change several times, cycling between Claude, GPT 4o, GPT 4o-mini, and then a Llama model.
At this point, OpenRouter pulled access and Shumer’s remaining defenders went quiet and VentureBeat wrote a follow-up piece covering the ‘fraud’ accusations.
But … why?
It’s easy to fall into the trap of assuming bad practice (from mere sloppiness up to outright fraud) is rare, just because it’s so self-defeating. Research communities are inclined to support apparent advances and give people the benefit of the doubt. The Head of Applied Research at OpenAI admitted to being initially taken in by Reflection before testing it himself. But doubters need only spend some time searching through the Retraction Watch database to get a sense of how rampant of a problem bad practice is across every scientific discipline.
As we’ve written about before, certain kinds of bad are widespread in the industry. Dataset contamination (when information from the test or validation data leaks into the training data) is rampant and researchers have been slowly pointing to the scale of the problem.
Scale AI retested a number of popular model families on their own math benchmark GSM1k, which was designed to resemble the popular GSM8k but with novel problems. They found that while Gemini, GPT, and Claude showed minimal signs of overfitting, Phi and Mistral performed poorly.

After a similar exercise from researchers at xAI pointed to the same trend in Alibaba’s Qwen family, one of the Qwen researchers came out with a refreshing admission:

This wouldn’t necessarily be a significant problem, if we collectively had a healthier relationship with benchmarks. While researchers frequently disparage them, they remain the easiest way of keeping score. This leads to the faintly absurd scenario where model builders overfit to benchmarks that contain high error rates, leading to better paper but worse real-world performance.
These practices are usually less drastic than what we saw in the Reflection story, but they, along with rigged demos, contribute to an erosion of standards. They contribute to a scenario where bad actors, keen to standout in an increasingly crowded field, feel confident trying their luck. It seems plausible that they might be able to get away with putting their thumb on the scale.
The temptation is also likely fuelled by just how difficult it is to advance the field. As an area of research evolves, the quantity of low-hanging fruit shrinks.
While it’s theoretically possible that there are small shortcuts that unlock huge performance gains consistently, the chances of finding new ones are likely to diminish with time. This is simply because a growing number of well-funded, sophisticated teams are on the case already. As we covered in our piece on the State of Chinese AI, you do get genuine architectural innovation, but this work is often plausibly difficult. For example, DeepSeek-V2’s speed and efficiency was unlocked by a series of architectural refinements and a novel attention mechanism - not a single quick fix. Maybe one extra API call is all you need, but it’s not likely.
There are only so many ways to develop an edge when building a foundation model. Unless you have a few billion dollars going spare, scale isn’t an option. That leaves you with the choice of either building a specialized high quality dataset or pioneering a new technique (e.g. pre-training/finetuning strategy or architectural innovation) that unlocks efficiency gains.
The advantage of the latter approach is that it’s much easier for questionable actors to game. You make some small tweaks, overfit your model to a few popular benchmarks, and wait for the retweets to start pouring in. It’s also harder for non-experts, who don’t know what questions to ask or how to run and evaluate the model themselves, to provide real scrutiny.
A whole system failure
Bad research doesn’t grow in a vacuum. To attain virality, other actors needed to play their role in this case.
Firstly, media coverage. For non-specialist reporters, assessing the quality of a model release can be challenging. If they’re on a deadline or not well-networked in the field, they may not have the time to ask around or conduct their due diligence. Also, if an obscure, open model is able to give the likes of Anthropic and OpenAI a run for their money - then it’s a great story! This kind of coverage provides an important imprimatur of legitimacy.
Secondly, the third party access and API providers. These companies aren’t neutral arbiters - they compete with each other and also need to raise capital. Being the first to provide access to a buzzy new model is a quick way of winning eyeballs and mindshare. It’s not their job to vet models, but when their teams post bold claims about model performance, grounded in a vibes-based assessment, they help to fuel the hype cycle. While OpenRouter eventually pulled access, for a while, they participated (unwittingly) in the fiction that a ‘fixed’ version of the model was on the way. Hyperbolic have said nothing.
Finally, the dynamics of X. As the body of real work has grown, so has the sea of AI influencers attempting to make a living off newsletters and ad revenues. ‘Shocking’ results and high volumes of content drive clicks, which can give the appearance of momentum and legitimacy to bad work.
But there are reasons to be cheerful. The community was able to figure out the truth in a space of a few days. While the debunkings often achieve less attention than the original hype, they work. And not just in this case. A few months ago, a group of Stanford students released Llama 3-V, a highly capable and efficient VLM that was competitive with various frontier lab offerings. Within a week, it was revealed that they had plagiarized MiniCPM-Llama3-V 2.5, produced by Tsinghua University.
Closing thoughts
The Reflection saga may just be one example, but bad practice, however quickly it unravels, needs to be taken seriously. This kind of behavior damages trust in research, makes life harder for genuine researchers and entrepreneurs, and risks making AI look like the next crypto.
If early promoters of the Reflection hype had asked themselves a few straightforward questions, much of this nonsense could have been avoided.
These include:
Who is the team?
How well-resourced are they?
What is their track record of research, journal, and conference submissions?
Are they framing or describing their achievements in the language and style we’d expect from serious scientists?
Do their reported benchmark scores seem plausible? Who else has validated them?
Are they upfront about any potential conflicts of interest?
Does this seem too good to be true?
While we love an ‘against the odds’ story, the CEO of an AI writing assistant company that’s raised fewer than $5M claiming that he is about to drop “the best model in the world” stretches credulity a step too far. We all need to do better.
I know nothing about AI and simply reading to learn. What I will say is that Shumer's article felt easier to understand than articles that debunk him like this one. And so inevitably, they're not going to perform as well.
Maybe we need more articles that speak in layman's terms so they can go viral too and disprove Shumer?