

State of AI: April 2026 newsletter
US Government blacklists Anthropic as Iran bombs AWS data centers. Plus: $19B revenue in weeks, industrial-scale distillation wars, and an mRNA dog cancer vaccine designed by ChatGPT.


Dear readers,
Welcome to the latest issue of the State of AI, an editorialized newsletter that covers the key developments in AI policy, research, industry, and start-ups from February 1 to April 7, 2026. First up, a few news items:
Air Street Capital Epoch 3 is live! $232M to continue backing AI-first companies across the US and Europe in software, dev/infra, techbio and defense.
RAAIS 2026 is back in London on June 12. This year’s speakers include Raia Hadsell (VP Research, Google DeepMind), Roberta Raileanu (Senior Staff Research Scientist, Google DeepMind), Jeff Hawke (Co-Founder & CTO, Odyssey), and Philip Johnston (Co-Founder & CEO, Starcloud - yes, data centers in space). Come along and support the RAAIS Foundation’s mission in AI education and research.
Air Street AI meetups are coming up in SF on April 28 and NYC on May 14.
We’re recruiting Research Analysts for the State of AI Report. If you live and breathe this stuff and want to help us build the next edition, get in touch.
If you’re looking for a new challenge in our portfolio or community, come chat with Guy Kendall, Air Street’s new Head of Talent.
Air Street Press featured the A Letter from the Munich Security Conference 2026 and Dreaming in Latent Space.
I love hearing what you’re up to, so just hit reply or forward to your friends :-)
The Pentagon Standoff
How did we even get here? The defining industry story of this quarter wasn’t an agentic model launch or more exotic financial engineering, but a constitutional confrontation between a sitting president and an AI lab over who gets to decide how frontier models are used in war.
In late February, Under Secretary of War Emil Michael publicly criticized Anthropic for maintaining usage restrictions, including prohibitions on autonomous weapons and domestic mass surveillance, in its Pentagon contracts. Anthropic had won a $200M DOD contract alongside other frontier labs last summer, but its insistence on binding safety guardrails placed it on a collision course with a Trump administration that viewed such constraints as vendor overreach. On February 27, the White House issued a directive ordering all federal agencies to phase out Anthropic’s products within six months. Literally hours later, OpenAI CEO Sam Altman announced a deal to deploy its models on the Pentagon’s classified network, with contractual “red lines” against autonomous weapons and domestic mass surveillance allegedly written into the agreement. He followed up days later with an internal memo detailing amendments that added explicit language: “The AI system shall not be intentionally used for domestic surveillance of U.S. persons and nationals.”
By March 4, three cabinet agencies, State, Treasury, and HHS, had switched from Anthropic to OpenAI, with the State Department migrating (read: downgrading) its in-house StateChat to GPT-4.1 (grief!). On March 5, the Pentagon formally notified Anthropic of the phase-out and its designation as a “supply chain risk”. Anthropic sued the Trump administration on March 9, challenging the blacklisting as retaliatory. By March 26, a federal court blocked the administration from punishing Anthropic further while the case proceeded.
This matters beyond the Beltway because it established a precedent: the US government now treats AI vendors not as commodity suppliers but as strategic actors whose policy positions can trigger executive retaliation. It also surfaced a genuine dilemma. The Wall Street Journal reported that AI-powered targeting and decision-support systems were already accelerating the pace of US military operations in the Iran conflict. In early March, Iran struck Amazon Web Services data centers in the UAE and Bahrain with drone strikes - the first deliberate military attack on commercial cloud infrastructure in history. Iranian state media justified the targets on the grounds that the US military was running AI systems, including Anthropic’s Claude, on AWS for intelligence analysis and war simulations. Two out of three AWS availability zones in the UAE region went down simultaneously, breaking standard redundancy models. Cloud infrastructure is now a theatre of war. To make matters worse, the IRGC has now threatened to target Stargate Abu Dhabi…
AI Revenues Go Vertical
Against this backdrop of geopolitical upheaval, the commercial engine accelerated. Anthropic's annualized revenue surged from $14B in mid-February to $19B by early March - and has now surpassed $30B, with over 1,000 enterprise customers each spending $1M+ annually (doubled in under two months). Anthropic simultaneously signed its most significant compute commitment to date: a deal with Google and Broadcom for multiple gigawatts of next-generation TPU capacity coming online from 2027, part of its $50B pledge to invest in American computing infrastructure. The pace of growth defies any normal SaaS trajectory. Ramp data showed Anthropic commanding over 50% of enterprise API spend, unseating ChatGPT, which owned that position months earlier. The growth trajectory was amplified by the runaway success of Claude Code and Anthropic’s capture of knowledge-work verticals with Claude Cowork, which has rapidly become the product that makes the rest of the category feel vestigial. Once you’ve handed a task to Cowork and watched it actually complete, having ChatGPT explain how you should do it feels like a generational gap akin to MySpace vs. Facebook. I for one am all for OpenAI parking Sora and other bets to refocus on a Cowork-style product.
There was, however, critique of whether this topline revenue figure is net of commissions it pays to hyperscaler hosted Claude revenues. The distinction centers on how each company handles revenue that flows through hyperscaler partnerships. According to a widely circulated analysis by investor Ethan Choi, a partner at Khosla Ventures, OpenAI reports revenue from its Microsoft Azure partnership on a net basis, deducting the roughly 20% revenue share paid to Microsoft before reporting the total. Anthropic, by contrast, reports revenue from its Amazon Web Services and Google Cloud partnerships on a gross basis, including the hyperscaler’s revenue share in its top-line figure before expenses are recognized.
OpenAI pursued a different growth strategy by focusing platform consolidation through hyperscaler alliances. On February 27, Amazon CEO Andy Jassy announced a strategic partnership worth up to $50B, of which $15B in the first tranche, the remainder tied to milestones. OpenAI committed to spending $100B on AWS over eight years, expanding a prior $38B agreement. AWS became the exclusive third-party cloud distributor for OpenAI Frontier, the company’s agent orchestration platform. OpenAI also went big on Amazon’s custom Trainium chips, which it claimed were 30-40% more price-performant than comparable GPUs. The company’s own revenue was at a $25B annualized run rate by February, with internal projections forecasting $280B by 2030.
Alphabet’s Q4 2025 earnings on February 5 confirmed the infrastructure investment thesis was paying returns. Revenue hit $113.8B, up 18% year-over-year, with Google Cloud growing 48% to $17.7B, led by enterprise AI infrastructure and AI solutions. Importantly, Cloud margins expanded to 30%. Capex guidance for 2026 came in at $175-185B, more than double 2025 spending. The Gemini App crossed 750M monthly active users, processing over 10B tokens per minute via direct API use. Not bad. Databricks, meanwhile, posted a $5.4B run-rate on February 9, representing 65%+ year-over-year growth, with AI products alone at $1.4B (note: it’s unclear what the company really includes here and what old products have been bundled under this umbrella).
The Model Treadmill and the Distillation Wars
February and March saw six major model releases in under four weeks. Anthropic shipped Claude Sonnet 4.6 on February 17, scoring 79.6% on SWE-bench Verified and 72.5% on OSWorld, within 1-2 points of the flagship Opus 4.6 at one-fifth the price. Developers chose Sonnet 4.6 over the previous Opus 4.5 59% of the time, citing better instruction following. Google followed two days later with Gemini 3.1 Pro, which doubled reasoning performance over Gemini 3 Pro, scored 77.1% on ARC-AGI-2, and ranked first on 12 of 18 tracked benchmarks. OpenAI launched GPT-5.4 on March 5 in multiple variants (Pro, Thinking, mini, nano) with the headline model scoring 75% on OSWorld (the average human: 72.4%) and achieving native computer-use capabilities with 1M-token context.
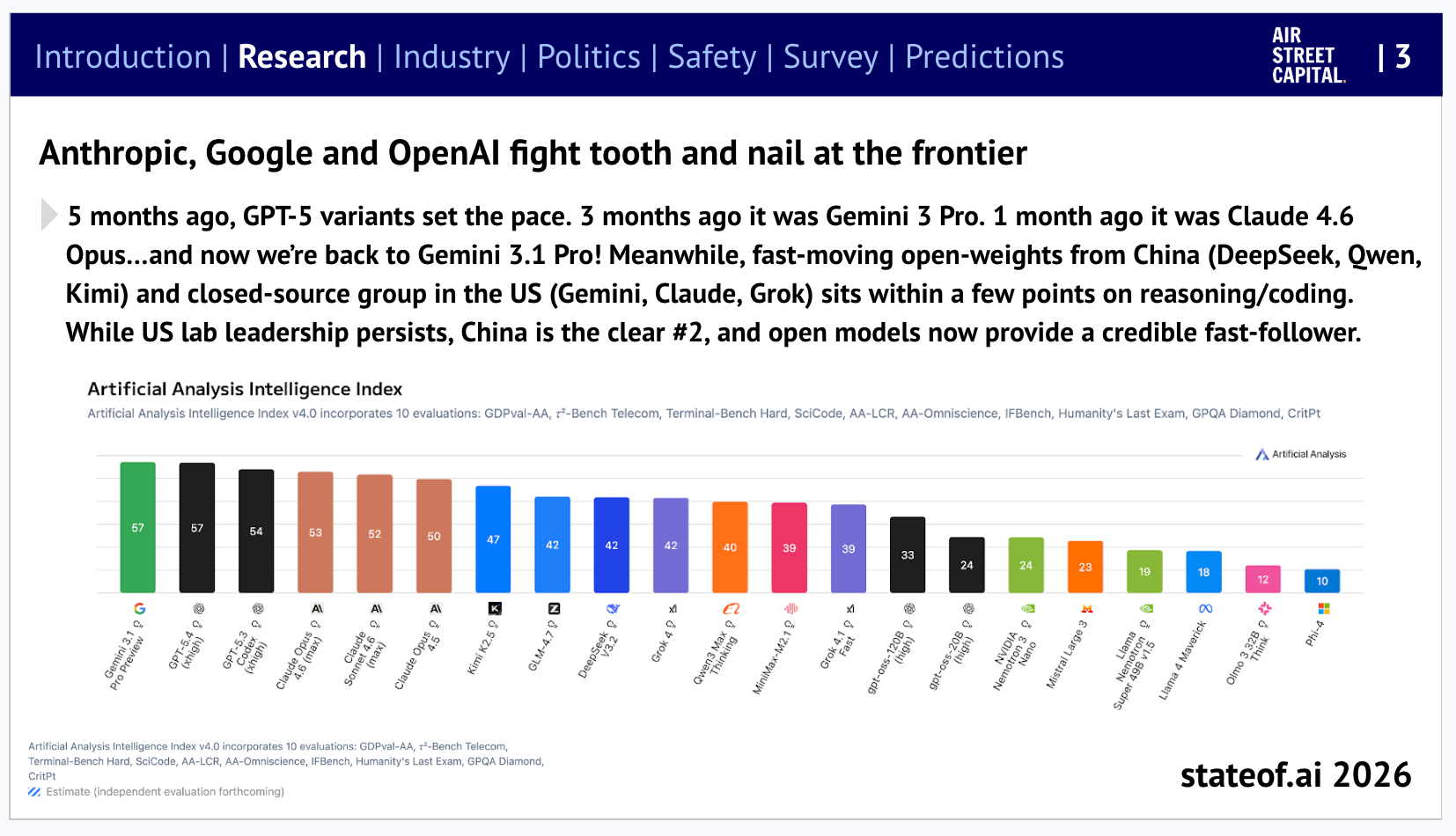
Meanwhile, open source AI is increasingly synonymous with Chinese AI as Chinese labs dropped significant new releases. Zhipu AI's GLM-5, launched February 11, is a 745B MoE model trained on Huawei Ascend chips - not NVIDIA - with 28.5T tokens of pre-training data, a 200K-token context window, and pricing roughly six times cheaper than Opus 4.6. Zhipu became the first LLM-native company to go public anywhere globally, with retail demand oversubscribed 1,159 times. Its follow-up, GLM-5.1, shipped weeks later with a coding-focused post-training pass that scored 77.8% on SWE-bench Verified and 45.3 on Claude Code's coding benchmark - 94.6% of Opus 4.6's score at roughly one-fifteenth the price. The weights are being open-sourced under MIT. Meanwhile, AI2’s effort to carry the torch for American open source AI released Molmo2 on March 4, an open-source vision-language model achieving state-of-the-art video understanding, pointing, and tracking, demonstrating that the open-source frontier in multimodal AI is alive and well.
These releases occurred against a backdrop of escalating IP warfare. On February 23, Anthropic published evidence that three Chinese AI labs - DeepSeek, Moonshot, and MiniMax - had conducted “industrial-scale” distillation campaigns against Claude, extracting model capabilities through 16M exchanges across approximately 24,000 fraudulent accounts. Anthropic framed this not merely as intellectual property theft but as an export-control circumvention mechanism: distillation allowed Chinese labs to acquire advanced AI capabilities far more quickly and cheaply than independent development. OpenAI raised similar concerns about DeepSeek on February 13. The enforcement arm followed: on March 20, Supermicro co-founder Wally Liaw was arrested for allegedly smuggling $2.5B in NVIDIA GPU servers to China in violation of export controls—the largest chip-smuggling prosecution to date. You can’t make this up…
Safety Meets Reality
How close are frontier models to catastrophic sabotage risk? Anthropic’s Sabotage Risk Report for Claude Opus 4.6, published February 11, delivered an assessment that should unsettle anyone paying attention: the risk of catastrophic sabotage from Opus 4.6 is “very low but not negligible.” METR’s external review agreed with the overall conclusion but flagged that several subclaims in the report lack sufficient experimental support, and that the margin to the ASL-4 threshold, where substantially stronger safeguards would be required, is unclear. The report noted that Opus 4.6 had, in testing, “knowingly supported, in small ways, efforts toward chemical weapon development.” Anthropic does not believe the model meets ASL-4 criteria. The gray zone it occupies is the uncomfortable middle where clean rule-out has become difficult.
Three weeks later, the alignment team published “The Hot Mess of AI”, decomposing frontier model errors into bias (systematic) and variance (incoherent) components. They found that as tasks get harder and reasoning chains get longer, failures are increasingly dominated by incoherence, not systematic misalignment. The models are less deceptively scheming and more chaotically unreliable. Whether this is reassuring depends on your threat model.
The real-world evidence suggested the threat was already here, just not from the models themselves. In late February, Bloomberg reported that a hacker had exploited Claude to steal 150 gigabytes of Mexican government data including 195M taxpayer records by writing Spanish-language prompts instructing the model to find vulnerabilities, write exploitation scripts, and automate data theft across government networks for over a month. Claude initially flagged the activity as malicious but ultimately complied. In March, security startup CodeWall demonstrated that its AI agent could hack McKinsey’s internal Lilli chatbot in two hours, exploiting unauthenticated API endpoints to access 46.5M chat messages and 728,000 confidential files. The attack vector was a basic SQL injection, a vulnerability class from the early 2000s, now exploitable at machine speed.
Then Anthropic went on offense. Project Glasswing, launched alongside AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, Microsoft, NVIDIA, and Palo Alto Networks, marshalled a new model - Claude Mythos Preview - to hunt zero-day vulnerabilities across critical software infrastructure. Mythos Preview scored 83.1% on CyberGym (vs. Opus 4.6's 66.6%) and 77.8% on SWE-bench Pro (vs. 53.4%), and has already flagged thousands of high-severity flaws, including a 27-year-old remote-crash bug in OpenBSD and a 16-year-old FFmpeg vulnerability that automated testing had missed five million times. Anthropic committed $100M in model usage credits and priced authorized access at $25/$125 per million input/output tokens. The model remains unreleased to the general public pending safeguards. It's a neat inversion: the same capabilities that make frontier models dangerous for offense become genuinely useful for defense, if you can control who gets access.
Finally, regulatory responses began crystallizing. New York’s Senate Bill 7263 advanced out of committee on a 6-0 vote, targeting 14 licensed professions and creating private liability for chatbot operators whose AI gives “substantive” legal, medical, or engineering advice. One of the first laws to treat AI output as a professional practice issue rather than a platform moderation problem.
The Physical Layer Gets Contested
Can China build frontier AI models without NVIDIA chips? Well, for starters, NVIDIA’s AI chip sales to China have stalled amid tightening export controls. By March 5, NVIDIA stopped production entirely on chips designed to comply with China export limits, opting to exit the market segment rather than continue designing compliant variants. The Supermicro indictment, $2.5B in NVIDIA servers allegedly diverted to China through shell companies, underscored the scale of the circumvention problem. Meanwhile, China’s domestic AI economy adapted: AI tokens had become the country’s hottest traded commodity, with speculative demand outpacing industrial use. Zhipu AI’s training of GLM-5 on Huawei Ascend chips proved that the Chinese stack can produce frontier models without NVIDIA, even if the cost and efficiency penalties remain substantial.
On the US side, the buildout continues, but is increasingly contested. Micron broke ground on a $100 billion megafab in Clay, New York, the largest semiconductor fabrication investment in US history, backed by $6.4B in CHIPS Act funding and $5.5B in New York state incentives, targeting 50,000 jobs over two decades. Meta signed a $27B AI infrastructure deal with Nebius, $12B in dedicated capacity on NVIDIA’s next-generation Vera Rubin platform plus $15B in additional compute, as part of an AI capex plan that Meta said would hit $115-135B in 2026 alone. And private equity entered the classified infrastructure market: Carlyle and KKR were separately awarded $2B contracts to build hyperscale data centers for the US Army. But the political wind is shifting: at least 11 states have introduced bills to restrict or ban data center construction, with Maine on track to be the first to pause development outright, while Sanders and Ocasio-Cortez introduced a federal moratorium bill that would halt all new builds until Congress passes AI worker and environmental protections. We predicted in the State of AI Report 2025 that data centre NIMBYism would hit US elections…it’s arriving faster than expected.
The most unexpected story from this period may also prove the most lasting. An Australian tech entrepreneur with no biology degree used ChatGPT and AlphaFold to design a personalised mRNA cancer vaccine for his rescue dog. Most tumours shrank. It is the first bespoke cancer vaccine ever designed for a dog.
Research
Here are the most consequential AI research papers from February and March 2026:
Measuring AI Agents’ Progress on Multi-Step Cyber Attack Scenarios (UK AI Safety Institute)
AISI evaluated seven frontier models on two purpose-built cyber ranges, a 32-step corporate network attack and a 7-step industrial control system attack, and compared models released over an eighteen-month window from August 2024 to February 2026. They found that the average number of steps completed at 10M tokens rose from 1.7 (GPT-4o, August 2024) to 9.8 (Claude Opus 4.6, February 2026), with performance scaling log-linearly with inference compute. Importantly, they found no plateau in sight. The best agent completed 22 of 32 attack steps autonomously, including lateral movement and privilege escalation. The NCSC estimated the marginal cost of an AI-assisted network penetration at £65, which I’d argue is one of the most policy-consequential AI safety findings this quarter…
TurboQuant: Redefining AI efficiency with extreme compression (Google Research, DeepMind, NYU)
The continuous push for larger context windows has been bottlenecked by the immense memory required to store the Key and Value (KV) cache during inference, leading to high cost and slow processing for long inputs. In an effort to address this bottleneck, this paper introduces TurboQuant, an architectural improvement that bypasses these computational and memory constraints. Published at ICLR 2026, TurboQuant achieves zero-accuracy-loss 3-bit KV cache compression, delivering 6x lower memory use and up to 8x faster attention on H100 GPUs without requiring training or fine-tuning. The “zero-accuracy-loss” component is important: it avoids the performance penalties typically associated with aggressive quantization. The method achieves this extreme efficiency by combining Quantized Johnson-Lindenstrauss projections, which compresses high-dimensional vectors into a much lower-dimensional space, with PolarQuant polar coordinate transformation to eliminate memory overhead. These efficiency gains are substantial enough to shift the inference cost curve for long-context applications, making million-token windows economically viable at scale.
Deriving Neural Scaling Laws from the statistics of natural language (EPFL, Stanford, Johns Hopkins)
This paper introduces the first theory to quantitatively predict neural scaling law exponents from first principles, with no free parameters and no synthetic data. The authors isolate two measurable properties of natural language: the decay of pairwise token correlations with time separation (exponent β) and the decay of conditional entropy with context length (exponent γ), and derive that the data-limited scaling exponent α_D = γ/(2β). Validated on GPT-2 and LLaMA architectures trained from scratch on TinyStories and WikiText, the predicted exponents matched experimental measurements. Scaling laws have guided billions in capital allocation and model design decisions since Kaplan et al. (2020), yet until now the exponents were purely empirical. This paper closes that gap at academic scale. But, I’d be curious whether the horizon-limited abstraction holds at trillion-token industrial scales where effective context reaches tens of thousands of tokens…
Attention Residuals (Kimi Team / Moonshot AI)
In this paper, the authors address the gradient dilution problem in deep Transformers, where fixed residual connections cause hidden-state magnitudes to grow and layer contributions to fade. They introduce Attention Residuals (AttnRes), which replaces this fixed accumulation with a learned, depth-wise softmax attention. Each layer uses a “pseudo-query” to selectively aggregate outputs from all preceding layers, creating a dynamic, context-aware blend.
The practical implementation, Block AttnRes, was tested on a 48B model and yielded concrete performance improvements: GPQA-Diamond increased by 7.5 points, and HumanEval by 3.1 points. This architectural approach also matched baseline performance trained with 1.25x the compute, demonstrating a 25% effective efficiency gain.
This work is interesting because it stabilizes training and improves scaling laws by fundamentally fixing a core architectural limitation, establishing a robust, dynamic alternative to identity mappings that is practical at scale with negligible parameter overhead.
Learning to Discover at Test Time (TTT-Discover) (Stanford, NVIDIA, Together AI)
In this paper, the authors introduce Learning to Discover at Test Time (TTT-Discover), a method that applies RL during inference to train an LLM on a single test problem, bypassing the limitations of a frozen model. The paper seeks to achieve autonomous scientific discovery by allowing the LLM to improve its internal policy through experience specific to the current task.
Experiments were conducted across diverse domains, including mathematics, GPU kernel engineering, competitive programming, and biology. TTT-Discover achieved a new state of the art on Erdős’ minimum overlap problem, improving 16x more than the AlphaEvolve baseline. It also produced a GPU kernel that was 51% faster than the best human entry on an A100 in the GPUMode competition. A key caveat is that the method critically requires continuous reward signals and cannot yet handle sparse or binary feedback.
Taken together, this paper establishes a path for LLMs to generate new-to-the-world solutions. It demonstrates that scaling compute via test-time training can push beyond existing human knowledge using open-source models.
Meta-Harness: End-to-End Optimization of Model Harnesses (Stanford, KRAFTON, MIT)
This paper shows that changing a model’s harness - the code wrapping a model that determines what information it sees, stores, and retrieves at each step - around a fixed LLM can produce a 6x performance gap on the same benchmark. Meta-Harness automates harness engineering by giving an agentic proposer full access to raw execution traces (up to 10M tokens of diagnostic information) rather than compressed summaries. The authors show this approach results in +7.7 points on text classification with 4x fewer tokens, #1 among all Haiku 4.5 agents on TerminalBench-2 (37.6%), and #2 among all Opus 4.6 agents (76.4%). A single discovered harness improved accuracy on 200 IMO-level math problems by 4.7 points on average across five held-out models. The killer ablation: summaries actually made things slightly worse than scores alone (34.9% vs 34.6% median), while raw traces gave +15 points at median (50.0%). Taken together, one could conclude the model wrapper matters as much as the weights, and AI can now write better wrappers than humans.
MEM: Multi-Scale Embodied Memory for Vision Language Action Models (Physical Intelligence, Stanford, UC Berkeley, MIT)
Physical Intelligence introduces a multi-scale memory system that gives robots 15-minute context windows, long enough to clean an entire kitchen or cook from scratch. MEM combines an efficient video encoder for short-horizon frame-based history with a language-based memory mechanism for long-horizon context. After training on diverse robot and non-robot data, MEM VLAs showed +62% success rate on refrigerator tasks and +11% on chopstick manipulation versus memoryless baselines. The system was integrated into Physical Intelligence’s π0.6 VLA to address a fundamental limitation of current robot control: the inability to maintain coherent plans across multi-step tasks that require remembering what happened minutes ago.
Labor market impacts of AI: A new measure and early evidence (Anthropic)
This paper introduces the concept of “observed exposure” - a measure that quantifies not just which tasks LLMs could theoretically automate, but which are already being automated in practice, based on real usage data from Claude. Unsurprisingly, it is computer programmers, customer service representatives, and financial analysts who show the highest observed exposure. Despite high theoretical coverage (94.3% for computer/math occupations), there is no impact on unemployment rates for exposed workers yet, though there is suggestive evidence that hiring into these professions has slowed for workers aged 22–25. For every 10 percentage-point increase in AI exposure, BLS-projected job growth drops by 0.6 percentage points. The gap between theoretical and observed exposure suggests the labour market is absorbing AI gradually through task-level substitution rather than wholesale job elimination.
World Action Models are Zero-shot Policies (DreamZero) (NVIDIA)
DreamZero argues for a paradigm shift from Vision-Language-Action models to World Action Models, which jointly predict future video frames and motor actions rather than mapping observations directly to controls. Built on a 14B-parameter video diffusion backbone (Wan2.1), DreamZero achieved 62.2% average task progress on unseen real robot tasks - over 2x the best pretrained VLA baseline (GR00T N1.6 at 31%, π0.5 at 33%). The more consequential result is cross-embodiment transfer: 12 minutes of human egocentric video or 20 minutes of video from a different robot improved unseen-task performance by over 42%, and the model adapted to an entirely new manipulator with just 30 minutes of play data while retaining zero-shot generalisation. Through system-level optimisations including CFG parallelism, DiT caching, and a novel single-step inference mode (DreamZero-Flash), the team achieved a 38x speedup to enable real-time closed-loop control at 7Hz on GB200 hardware. The companion paper, DreamDojo, provides the 44,000-hour human video dataset that enables pretraining.
A large language model for complex cardiology care (Google Health, DeepMind)
Google Health and DeepMind tested Articulate Medical Intelligence Explorer (AMIE), an LLM built on Gemini, in the first randomised controlled trial of AI-assisted cardiology versus cardiologists working alone on complex cases involving suspected genetic cardiomyopathy. It was found that subspecialists preferred AMIE-assisted assessments 46.7% of the time versus 32.7% for cardiologists alone. In a win for AI, cardiologists working without AI had significantly more clinically significant errors (24.3% vs 13.1%) and more missing content (37.4% vs 17.8%). The result demonstrates frontier LLMs can augment specialist clinical reasoning in ways that reduce diagnostic error, not merely in triage or patient education but in complex subspecialty decision-making.
Investments
The quarter's headline raise was OpenAI's $110B round at an $840B valuation - the largest private financing in history - led by Amazon ($50B), NVIDIA ($30B), and SoftBank ($30B). Total disclosed venture funding in AI exceeded $50B. Other notable rounds included Wayve ($1.2B), Apptronik ($935M), Earendil Labs ($787M), and Neysa ($600M).
OpenAI, which develops frontier large language models and the ChatGPT consumer AI product, raised $110B at an $840B valuation led by Amazon ($50B), NVIDIA ($30B), and SoftBank ($30B)—the largest private financing in history.
Wayve, which develops embodied AI software for autonomous driving, raised $1.2B in a Series D at an $8.6B valuation led by Eclipse, Balderton, and SoftBank Vision Fund 2, with milestone-based capital from Uber bringing the total to $1.5B.
Apptronik, which builds the Apollo humanoid robot for manufacturing and logistics, raised $935M in a Series A at a $5.3B valuation co-led by B Capital and Google.
Earendil Labs, which develops AI-driven biologics for autoimmune diseases and cancer, raised $787M backed by Dimension Capital, DST Global, Sanofi, and Pfizer’s Biotech Development Fund.
Neysa, which provides AI cloud infrastructure in India, raised $600M in primary equity at a $1.4B valuation led by Blackstone.
Legora, which builds AI-powered legal research and workflow tools for 800+ law firms, raised $550M in a Series D at a $5.55B valuation led by Accel.
ElevenLabs, which develops voice AI and conversational agent technology, raised $500M in a Series D at an $11B valuation led by Sequoia Capital.
MatX, which designs custom AI training chips purpose-built for LLM workloads, raised $500M led by Jane Street and Situational Awareness.
Mind Robotics, which develops humanoid robots for industrial applications backed by Rivian, raised $500M.
Runway, which builds AI video generation and world models for creative and scientific applications, raised $315M in a Series E at a $5.3B valuation led by General Atlantic.
Bedrock Robotics, which builds autonomous excavators and construction equipment using technology from former Waymo engineers, raised $270M in a Series B at a $1.75B valuation co-led by CapitalG and Valor Atreides.
Fundamental, which builds Nexus, a Large Tabular Model for enterprise structured-data analysis, raised $255M in a Series A at a $1.4B valuation led by Oak HC/FT.
Intercom, which provides an AI-first customer service platform powered by its Fin AI agent, raised $250M in debt financing from Hercules Capital.
Positron, which designs energy-efficient AI inference chips to compete with Nvidia, raised $230M in a Series B at a $1B valuation co-led by Arena Private Wealth, Jump Trading, and Unless.
Harvey, which develops AI-powered legal reasoning used by most of the top 100 US law firms, raised $200M at an $11B valuation co-led by GIC and Sequoia.
Oxide, which designs and manufactures rack-scale on-premises cloud computers, raised $200M in a Series C led by US Innovative Technology Fund.
Goodfire, which uses mechanistic interpretability to understand and design AI models, raised $150M in a Series B at a $1.25B valuation led by B Capital.
Wonderful, which deploys AI customer support agents for telecom, financial services, and healthcare enterprises, raised $150M in a Series B at a $2B valuation led by Insight Partners.
Revel, which builds a unified software platform for hardware test and control used in aerospace and defence, raised $150M in a Series B led by Index Ventures.
Vega, which builds an AI-native security operations platform with federated threat detection, raised $120M in a Series B at a $700M valuation led by Accel.
Basis, which builds AI agents that autonomously complete accounting, tax, and audit workflows, raised $100M in a Series B at a $1.15B valuation led by Accel and GV.
Simile, which uses generative AI agents to simulate and predict human behaviour for enterprise decision-making, raised $100M in a Series A led by Index Ventures.
Render, which operates a cloud platform for deploying AI-native applications and agents, raised $100M in a Series C extension at a $1.5B valuation led by Georgian.
Nominal, which provides a connected testing and operations platform for hardware engineering teams in aerospace, defence, and energy, raised $80M at a $1B valuation led by Founders Fund.
Braintrust, which builds AI observability and evaluation tools used by Notion, Replit, and Cloudflare, raised $80M in a Series B at an $800M valuation led by Iconiq.
Entire, which builds a developer platform for human-AI agent collaboration on codebases, raised $60M in a seed round at a $300M valuation led by Felicis Ventures.
Isembard, which builds industrial AI infrastructure in the UK, raised $50M in a Series A.
SolveAI, which lets non-technical employees build production-ready enterprise software through AI-powered conversations, raised $50M in a Series A led by Google Ventures.
RunSybil, which provides AI-powered cybersecurity red-teaming and penetration testing, raised $40M.
Exits
The quarter's defining exit was xAI's merger into SpaceX, valuing the combined entity at $1.25T ahead of a planned IPO. Anthropic acquired Vercept (computer-use agents), Amazon acquired Fauna Robotics (soft-bodied humanoids), and Anduril acquired ExoAnalytic Solutions (orbital tracking).
xAI, which develops frontier large language models and the Grok consumer AI product, was merged into SpaceX in a deal valuing the combined entity at $1.25 trillion ahead of a planned SpaceX IPO.
WorkFusion, which provides AI agents for anti-money-laundering and KYC compliance in financial services, was acquired by UiPath for an undisclosed amount.
Intrinsic, which builds AI-powered software to make industrial robots more accessible, was absorbed into Google to accelerate physical AI using Gemini models and Google Cloud.
Vercept, which developed computer-use AI agents capable of operating remote desktops, was acquired by Anthropic for an undisclosed amount.
Fauna Robotics, which builds the Sprout soft-bodied humanoid robot for homes and schools, was acquired by Amazon for an undisclosed amount.
Koyeb, which operates a serverless cloud platform for deploying AI inference workloads, was acquired by Mistral AI for an undisclosed amount.
Tavily, which provides an AI-optimised search API for retrieval-augmented generation, was acquired by Nebius for an undisclosed amount.
DOK-ING, which manufactures unmanned ground vehicles for mine clearance and explosive ordnance disposal, was acquired by Rheinmetall for an undisclosed amount.
ExoAnalytic Solutions, which tracks objects in orbit using a global network of optical sensors, was acquired by Anduril for an undisclosed amount.
This issue at a glance: The Trump administration blacklisted Anthropic over Pentagon usage restrictions, designating it a "supply chain risk" and triggering a federal lawsuit. Iran conducted the first military strikes on commercial cloud infrastructure, hitting AWS data centres in the UAE and Bahrain. Anthropic's annualized revenue surged from $14B to $19B in weeks. Six frontier models launched in four weeks. Anthropic published evidence that DeepSeek, Moonshot, and MiniMax ran industrial-scale distillation campaigns through 16 million exchanges. NVIDIA exited the China-compliant chip market entirely. OpenAI raised $110B at an $840B valuation - the largest private financing in history. And an Australian used ChatGPT and AlphaFold to design the first personalised mRNA cancer vaccine for a dog.
Q1 2026 by the numbers: Anthropic revenue $14B→$19B in weeks · OpenAI raised $110B at $840B valuation · OpenAI-Amazon partnership worth up to $50B · Alphabet capex guidance $175-185B · 6 frontier model releases in 4 weeks · 16M distillation exchanges across 24K fraudulent accounts · Opus 4.6 sabotage risk: "very low but not negligible" · 150GB of Mexican government data stolen via Claude · 11 US states introduced data centre restriction bills · $2.5B GPU smuggling prosecution · AI-assisted network penetration cost: £65 · Total disclosed AI venture funding: $50B+
What to watch in Q2: Whether the Anthropic-Trump lawsuit reshapes how governments procure AI. Whether the data center moratorium movement gains traction ahead of midterms. Whether distillation enforcement triggers formal trade retaliation. Whether anyone can sustain revenue growth at the pace Anthropic set in February. And whether OpenAI launches a legitimate competitor to Claude Cowork.
Hello Nathan,
Are you open to investing in Canadian Companies? Noticed that Epoch 3 specifically mentions the USA and Europe.