




Prefer audio? Listen to this essay here.
Introduction
As we enter the State of AI Report writing season, we’re facing the same challenge that we’ve encountered in previous years: the pace of progress. Every slide we draft is a hostage to fortune, with a new release, a product launch, or an earnings report threatening to send us back to square one.
One such rewrite was prompted by the good folk at Meta, when Llama 3.1 landed on X feeds around the world.

Finally, an open model had caught up with the State of the Art. What had started as GPT-4 vs the rest, had already turned into GPT-4, Claude and Gemini, and even this tiering seemed to be breaking down.
Given our past advocacy for open source and skepticism of the ‘bigger is always better’ paradigm, we felt it worth asking if these breakthroughs mark a tipping point in AI research and commercialization. As ever, the answer is … complicated.
The erosion of openness
Eric Raymond, reflecting on his experiences developing open-source email client Fetchmail, wrote an influential essay in 1997 outlining two contrasting approaches to software development:
The Cathedral: traditional, centralized software development typically used in commercial software companies. Software is developed by an exclusive group of programmers working in relative isolation until the product is ready for release.
The Bazaar: open-source development model, exemplified back in the 1990s by Linux. Software is developed in full view of the public, with frequent releases and continuous feedback from a large community of developers and users.
Raymond became a prominent early open source advocate, throwing his intellectual weight behind the bazaar. He believed open source software was more stable, had fewer bugs, and by taking advantage of the perspectives of a large community who used the product, was more innovative and better adapted to their needs.
The core difference, he believed, was exemplified in the approach to bugs. For the cathedral-builder “bugs and development problems are tricky, insidious, deep phenomena. It takes months of scrutiny by a dedicated few to develop confidence that you've winkled them all out. Thus the long release intervals, and the inevitable disappointment when long-awaited releases are not perfect.”
Meanwhile, in the bazaar, “you assume that bugs are generally shallow phenomena—or, at least, that they turn shallow pretty quickly when exposed to a thousand eager co-developers pounding on every single new release. Accordingly you release often in order to get more corrections, and as a beneficial side effect you have less to lose if an occasional botch gets out the door.”
This is … not how ‘open source’ foundation models are developed.
They are developed centrally, typically within a single organization, using their proprietary data and compute. The core contributors are limited to a select group. Following the closed development process, the post-release community involvement isn’t the same. In traditional open source software development, anyone can submit a pull request to a project to recommend code changes, following community approval. This isn’t possible here. On top of this, the main ‘open’ models come with restrictive licenses that limit their commercial use.
The embodiment of all these behaviors is Meta’s Llama family. While an impressive technical feat, it is not open source by any real definition. Considering its training data, rather than its architecture, is the secret to its success, Meta have (understandably) decided that they don’t fancy sharing it with anyone. Beyond saying this data is ‘publicly available’, Meta provides no accompanying documentation.
If anyone creates a new model based on the Llama base model, Meta insists on a naming convention featuring the word ‘Llama’ and distributed under the same license. Meanwhile, its use is prohibited for any commercial service with over 700M users at the time of release.
Even if Meta didn’t adopt these counter-open practices, there would still be no way for the community to contribute to the model, beyond retraining or finetuning, potentially at great expense.
Of course, none of this stopped Mark Zuckerberg drawing an ambitious comparison between Meta’s approach to AI and the development of Linux in a recent essay.
Essentially, Meta has recreated the cathedral, it’s just made access free.
But Llama isn’t alone here. A recent paper comparing models on different metrics of open source found that only a small handful of models could have genuinely been called ‘open source’ versus ‘open weight’:
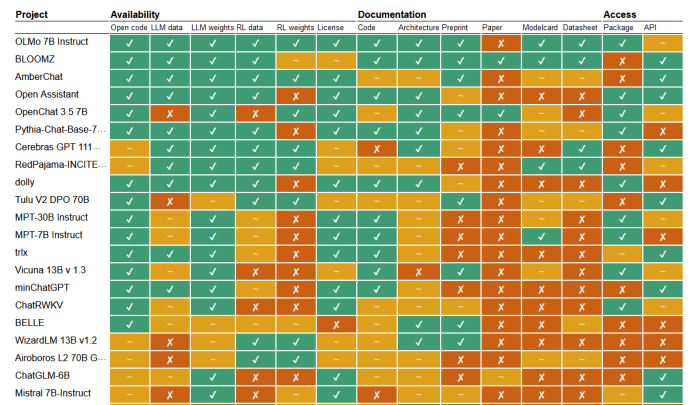
Many of these models are on the smaller side due to compute and data availability, as well as some of the potential legal issues around the release of huge datasets. They are also less popular among researchers. OLMo 7B Instruct, for example, was only downloaded approximately 1,500 times in the last month from Hugging Face.
But again, even when these models are more open in their distribution, they are still cathedral-like in their development. This even applies to a multi-team effort like Hugging Face’s BLOOM - they just have a bigger group of core contributors. There’s no way someone could theoretically submit some layers or weights to a model.
Meta and these other developers are, to an extent, simply acting rationally given the costs involved in model training. Imagine if compiling code in software engineering cost hundreds of millions of dollars instead of being essentially free.
In this scenario, you could theoretically open source everything, but the expense of running this compiler would act as a significant barrier to entry. This is the dynamic foundation model developers face. After all, there’s a reason the open source movement didn’t begin to gain real traction until the 1990s. This was partly due to the advent of internet communities, but also the ubiquity of the PC driving down costs.
But isn’t this just semantics?
Our intention here is not to engage in a philosophical exploration of ‘openness’ or pick on any developers.
Whether it’s been in our writing about non-consensus, or our trilogy on frontier model economics, our recent work has focused on trying to drive home the importance of pragmatism and commercial sense, along with technical brilliance.
While we are resolute in our support for people’s right to conduct and share work openly, we feel that there is also significant inefficiency in current open foundation model efforts. Large amounts of money, compute, time, data, and talent are being sunk into undifferentiated cathedral-type projects that will never find a commercial use or develop significant cut-through in research spaces.
This is the exact reverse of the original open source spirit, which was about the community reducing costs by contributing to something that everyone got to use. Sinking hundreds of millions of dollars into building differently-badged versions of increasingly commoditized piece of software does not fulfill the open source mission.

In a recent Guide to AI, we covered a paper that provided a quantitative analysis of Hugging Face usage. They found that activity was skewed, with 70% of models having never been downloaded, while 1% of models (primarily developed by big tech companies) account for 99% of downloads. This isn’t a comment on Hugging Face - it’s how almost every marketplace works.
Even highly popular models like the Llama family are likely to face significant roadblocks in achieving commercial adoption.
To understand why, it’s worth looking at some genuinely open source work that emerged from Meta.
The React story
React is a popular open-source Javascript library that allows developers to create reusable UI components and manage the state of these components efficiently. It reduced unnecessary re-rendering, improved performance, and is now one of the most widely used frameworks in the world for building web applications.
React started as a project within Meta (then Facebook), deployed on the News Feed in 2011 and Instagram in 2012, but the code was made publicly available on GitHub in 2013. Over time, Meta began to encourage and incorporate contributions from developers outside the company, building a diverse community of contributions. While React was not transferred to an independent foundation like Apache or Linux, Meta created a React Core team. Originally made up of only Meta employees, it has been expanded to include independent contributors. In 2017, following community pushback, Meta dropped React’s BSD + Patents license (where code was open but copyrighted) in favor of the permissive MIT license.
These steps didn’t just make React a better library, they crucially made it a trusted library. Updates are made by the community through a defined process. They can’t happen at the whim of one company. The community also uses React in their day jobs, often as part of their organization’s critical infrastructure, creating a mutual dependency. Everyone has skin in the game.
With PyTorch, Meta went even further, creating the independent PyTorch Foundation, whose governing board has representatives from most of the world’s most powerful technology companies.
This is different
None of these assurances exist for Llama.
Llama users have no input into the model, its training, or release timelines. They have the ability to finetune it, but in many cases, this will amount to the right to repaint the cathedral door. Moreover, there’s no contract, so users are somewhat vulnerable to any drastic changes.
Very few tech companies will use a tool developed on these lines for anything more than POC building, which is why so many are opting to build their own foundation models. We suspect Apple is partnering for a good time, not a long time, given that their researchers are working on a number of LLMs that seem suspiciously compatible with the company’s hardware.
Zuckerberg himself gets this, saying at a recent conference, on the thought of using someone else’s models for Meta, “fuck that”.
For companies that aren’t able to train their own models, closed alternatives at least provide the certainty of a long-term contract or enterprise agreement at the API level. Not only does this provide confidence, it has the added benefit of familiarity, operating like the licenses they use for Office or Exchange. While this does come with cost, it comes with convenience. Also, there are highly performant, relatively inexpensive options out there like Claude 3 Haiku at $0.25 per 1M input and $1.25 per 1M output tokens.
Should we all just give up?
Obviously, access to highly capable open weights models is not without value.
Firstly, in academic research. Not only are there the cost advantages, they bring additional transparency, allowing researchers to examine the architecture and parameters. They’re easy to customize or finetune for specific research-needs and by providing a consistent, examinable foundation for experimentation to enhance research reproducibility.
As well as research with models, it’s important for research on models. Llama has played an important role advancing research on safety and alignment. Meanwhile, as our recent essay on the state of Chinese AI pointed out, it can be a way of sharing potential architectural enhancements.
Secondly, for start-ups. Not only is their risk tolerance probably higher than that of a traditional enterprise (at least you’d hope), a technically talented team working in a streamlined organization can both easily handle implementing an open source model and swapping it out if they decide they need to change. After all, far less of a team’s skills, tooling, and codebase are tied to Llama than they would be to React. There are also the obvious cost advantages, especially when trying to work up an initial proof of concept to test hypotheses with customers.
More philosophically, the existence of at least one compelling open weight alternative plays an important role in keeping closed model providers honest. If they held the entire market in a chokehold, they’d be free to charge what they like. The only people who’d be able to avoid this extractive dystopia would be those with the resources and expertise to train their own models.
There is also a potential alternative route that takes advantage of LLMs power as data generators. Powerful small models like Gemma can now be trained off the output of their larger relatives. If the cost of compute fell sufficiently, there is a world in which a foundation like Apache, Common Crawl, or Mozilla could put out a GPT-4esque model once or twice a year. These models would then serve the same role for smaller models that CommonCrawl today serves for any model. While this would not be a perfect “bazaar”, it would still result in a community-maintained model that could serve as a foundation for more specialized, smaller models.
Closing thoughts
As we write this, there’s been (yet another) spate of commentary around AI, bubbles, and whether the sector is suffering from the effects of overinvestment. We’re not newcomers to this space, so we’re used to the AI optimism chart resembling a heart rate monitor - a wave of excitement followed by the realization that tech is hard.
Much of this difficulty stems from working out where value does and doesn’t lie. This is why, for example, we’ve seen enterprise companies seemingly pivot from helping customers build their own models or fine-tune them to releasing their own models (which they then often don’t use themselves). Again, while this work is impressive, it feels faintly gratuitous.
It’s our contention, however, that, while an incredible accelerant of progress, for many applications, the LLM future will more closely resemble Windows than Linux or Apache.
But this is a reason for optimism! It frees time and resources up to go after challenges where there’s a possibility of differentiation. Namely, in working out how to integrate the best technology into solving messy, real-world, often unglamorous problems. To build technology that genuinely moves the dial on real-world challenges. The reason we’re passionate about this space is not just the technology (however cool it may be), but ultimately what it can be used to achieve.
Thank you, I really enjoyed reading this.
One thought regarding this 'There is also a potential alternative route that takes advantage of LLMs power as data generators.'
A recent paper shows how training on synthetic data is problematic, because the tails of the distributions are distorted/disappear. https://www.nature.com/articles/s41586-024-07566-y
So there might be a natural limit on how useful LLMs are to create data for training purposes.