




Prefer the audio version? Listen to it here
Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and startups over the last month. But first, housekeeping:
We’re looking forward to seeing friends at our NYC AI meetup this coming Thursday. The event is now oversubscribed, but if you want to join the waiting list - register here. Subscribe to Air Street Events to ensure you don’t miss out on future meet-ups, including SF, London, and Paris before the year end.
Don’t forget to subscribe to Air Street Press to receive all our news, analysis and events directly in your inbox. Recent pieces have included our analysis of the state of play in agentic AI and open-endedness research, a cool-headed look at the commercial potential of open foundation models, and our take on how the UK can restore its AI ambitions.
For those of you who listen on the go, or multi-thread modalities, you can find all of our writing in audio form including this newsletter - check it out on Spotify here.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
Despite the UK’s political class having largely decamped from Westminster for the summer, there have been cries of outrage from the science and technology communities on safety island. This came after the government announced that it was cutting £1.3B of funding for the country’s AI Research Resource and the country’s first exascale project. The announcement was particularly confusing as it came days after the government commissioned ARIA chair Matt Clifford to produce a report on AI opportunities.
Following a wave of community criticism, the government went into panic mode, spinning that the planned exascale project would have been unsuitable for AI applications and that the previous compute commitments were unfunded. As we’ve explained elsewhere, both claims are highly misleading. This (entirely coincidentally…) comes after the government decided that it no longer required the services of its expert independent advisors on AI.
Real AI leadership requires long-term investment, robust expert advice, and a basic degree of seriousness. This sequence of events suggests that all three are currently lacking. Researchers are hoping that the AI Opportunities taskforce that Matt is leading will partially reverse some of these decisions.
Bad feelings aren’t just confined to the UK. A few months ago, we shared our assessment of SB 1047, an ambitious proposed law under consideration in California. Sponsored by the x-riskers at the Center for AI Safety, it would create a safety and liability regime for foundation models. The bill has proven highly controversial, with much of the tech and VC world (including voices that normally support AI regulation) coming out in opposition to the bill. Prominent state Democrats, including former House Speaker and legendary long-short equities trader Nancy Pelosi, have also called for it to be dropped.
Amid this controversy, the bill has gone through a significant amendment process, including changes to how in-scope models are assessed, the elimination of a planned AI oversight body, and the removal of some criminal liability provisions. Anthropic has now come round to the bill rather grudgingly as has Elon Musk, while Meta and Google remain opposed.
On Wednesday, lawmakers passed the amended bill. It will face another process vote and California Governor Gavin Newsom will have until 30 September to decide whether he wants to sign it into law or veto it.
Now, let’s move onto copyright cases. Last year, a lawsuit brought by a group of artists against Stability, DeviantArt, and Midjourney around copyright infringement was chopped down by a judge. A copyright infringement claim against Stability was allowed to proceed, while wider arguments around issues like right of publicity and vicarious infringement were tossed. The plaintiffs were given leave to amend their claims against DeviantArt and Midjourney. The artists brought their claims and again, while some of them have been narrowed, the judge has allowed them to pursue multiple claims against the companies.
Elsewhere, new fronts are opening up. Anthropic is under fire over the alleged scraping of books, while NVIDIA and OpenAI are facing cases over the use of YouTube videos. In perhaps the most striking case of its genre, a spreadsheet created by Runway listing the individual YouTube videos they’ve scraped has leaked. With no end in sight for these cases, we believe it makes more and more sense for industry to try to strike some sort of settlement, rather than fighting to the death and seeing one imposed by the courts. This is something we’ve covered in more depth in the past.
In the meantime, war is once again proving good business for the brave. Fresh from a $25M fundraise, ProRata.ai has struck a deal with the FT, Axel Springer, The Atlantic, Fortun, and Universal Music Group. The start-up claims that it can help operate revenue sharing agreements with chatbot-style services, accurately calculating revenue sharing agreements.
🍪 Hardware
After a jittery few weeks on the markets, NVIDIA revealed that Q2 revenue had more than doubled year-on-year, with earnings per share hitting 68 cents versus the consensus 65 among analysts. However, this did fall short of some of the most ambitious forecasts, causing a dip in the share price during after-hours trading. Following production delays for the new Blackwell family of GPUs, CEO Jensen Huang used the earnings call to reassure analysts that the necessary design changes had now been made and that they still envisaged booking several billion dollars in Blackwell revenue before the end of the year.
It’s also been interesting times in the land of NVIDIA competitors. AMD has announced a planned $4.9B acquisition of server builder ZT Systems.
There’s obvious logic to the move. Historically, AMD has struggled to eat into NVIDIA’s dominant market share in the data center business. Part of NVIDIA’s success lies in its provision of customizable vertically integrated solutions to hyperscalers, with powerful networking capabilities (bolstered by its acquisition of Mellanox). By contrast, AMD focused more on the provision of components and competing on price/performance ratios rather than offering full-stack solutions. In the era of huge clusters, it’s clear which of these approaches makes more sense.
AMD will benefit from ZT Systems’ expertise in systems design and rack-scales solutions, while spinning off its server manufacturing business.
It’s not all roses for server makers, however. ZT Systems competitor Super Micro Computer was left reeling by a report from activist short-selling firm Hindenburg. At the time of writing, the company’s stock has crashed by about a third, following claims of dubious accounting, export control violations, and quality concerns from major customers. For the avoidance of doubt, this is a newsletter and not financial advice.
Spare a thought for Intel. At the height of a global chip scramble, the company reported a year-on-year decline in revenue in Q2. The company has announced a 15% reduction in headcount and a suspension in dividends. Having spurned the GPU as a tool for AI research for years on the grounds that it was “ugly”, the company shows no sign of overturning its historic deficit.
In a sign of bravery and/or desperation, the company is now looking to deepen its ties to China. It has unveiled plans to provide a discrete automotive GPU for Chinese car-makers. This follows the launch of an AI and edge computing innovation center with the Nanshan district government in Shenzhen last year. We imagine the US Department of Commerce is delighted.
When it comes to export restrictions, smuggling is becoming even more brazen. Early investigations into smuggling rings tended to focus on a handful of chips being moved around in suitcases, but a Chinese electric appliance company managed to place a $120M order for a 2,400 H100 cluster via a Malaysian broker. Due to the size of the order, NVIDIA mandated an in-person check to ensure proper installation. Once this was done in a Malaysian facility, the servers were immediately removed and transported to China.
But who needs to pay smugglers a premium when AWS will hook you up? It’s emerged that a number of state-linked Chinese organizations have gained access to powerful AI infrastructure via intermediaries. It’s understandable that the US government struggles to control who exactly in Malaysia is the end user of an H100 cluster. It’s less understandable that they allow hyperscalers to continue serving the very Chinese customers whose access they’re trying to restrict. Seriousness challengers aren’t confined to the UK, it seems…
One company that is hoping we’ll spend less time talking about NVIDIA is Cerebras. The company has unveiled an inference platform, based on its CS-3 chip, claiming it’ll be 20x faster at AI inference than NVIDIA’s current H100 chips, using benchmarking from Artificial Analysis. The service is accessible via an API.

On one level, the play makes sense. Pivoting to an API model circumvents the well-known software deficit NVIDIA challengers all face. But, the question is the extent to which speed of token generation will prove a relevant metric for many use cases. If latency is so important to a user, would they turn to the cloud versus on-device? While dodging the killer NVIDIA software ecosystem avoids one challenge, cloud providers also have their own sets of bells and whistles, so they may also prove tough competitors. The route picked by Cerebras, Groq (which recently raised $645M) and others may well prove a case of jumping out of the frying pan and into the fire…
Speaking of seemingly unassailable hardware monopolies, ASML have long been the undisputed kings of EUV lithography. So far, prospective competitors have only managed to touch the significantly less lucrative (and advanced) DUV. The R&D spend required to catch up with ASML has historically proved too high. But now the Okinawa Institute of Science and Technology claims it has pioneered a drastically simplified approach to EUV, allegedly making the process ten times cheaper. The technology is still in its early phases, but the researchers intend to continue pursuing this approach, and if it proves successful, partner with a Japanese corporation.
🏭 Big tech start-ups
It’s all change over at Character.AI, after it was announced that Google had agreed to an acquisition a licensing agreement with the company. Investors will be bought out at 2.5x the company’s Series A valuation, while the two co-founders will return to Google to take on senior roles around Gemini. Character staff working on model training will also go over to Google, while Character will switch to using open models to power their assistant product. This follows the same principle as the Microsoft/Inflection and Amazon/Adept deals, only with investors being paid at a premium.
Character, which had previously raised $150M, allowed people to interact with personalized chatbots, and quickly became dubbed the “AI girlfriend” service, an image the company had become increasingly keen to shift. However, despite its popularity, its base of premium subscribers was relatively small, while the compute bill to train its in-house models wasn’t shrinking. The company had previously considered partnership with both Meta and xAI.
However, antitrust regulators are tired of the “I can’t believe it’s not an acquisition” maneuver. The FTC is already investigating the Microsoft-Inflection deal. It’s entirely possible that this pseudo-acquisition tactic ends up having a relatively limited shelf-life.
Aleph Alpha, Germany’s generative privacy-first AI challenger has had a rough few months. It has faced mounting domestic criticism over its failure to release high-performing models and its use of its business development pipeline to present its $110M raise as a $500M one. Recently, the business had seemed to be focused more on licensing Llama and DBRX to enterprise customers. However, it just unveiled the Pharia-1-LLM family, trained specifically to accord with EU regulations around copyright and data-protection. The 7B parameter base model is based on a classic GPT architecture and is optimized for French, German, and Spanish.
The company claims it performs particularly well in domain-specific applications around the automotive and engineering industries. They include an extensive critique of the nature evaluation and benchmarks in generative AI, but the model card shows it to be competitive with Mistral-7B (released in September last year) on some tasks and to consistently lag Llama-3.1-8B. While good to see Aleph Alpha back in the arena, they have a long way to go if they’re to convince the doubters.
Either way, Germany has a new hope in the form of Black Forest Labs. Made up of ex-Stability researchers, the team is working on foundation models for image and video generation. FLUX.1, the company’s first family of text-to-image models has already been released, with a high-powered closed model, and two smaller open versions.
Whatever Aleph Alpha’s struggles, they pale in comparison to the challenges over at the H Company. Back in May, Paris-based H had raised a blockbuster $220M seed round, largely based on four of the five co-founders’ past Google DeepMind affiliation. However, just a couple of months later, three of the co-founders have quit citing “operational differences”. H’s founding team was the company’s only asset at the time of investment, so this represents a … mild betrayal of trust. It also highlights the risks around investing in a team that don’t know each other that well while pitching a relatively vague concept.
It’s been a better few weeks for Mistral - its flagship Large model has taken the LMSYS coding leaderboard by storm.
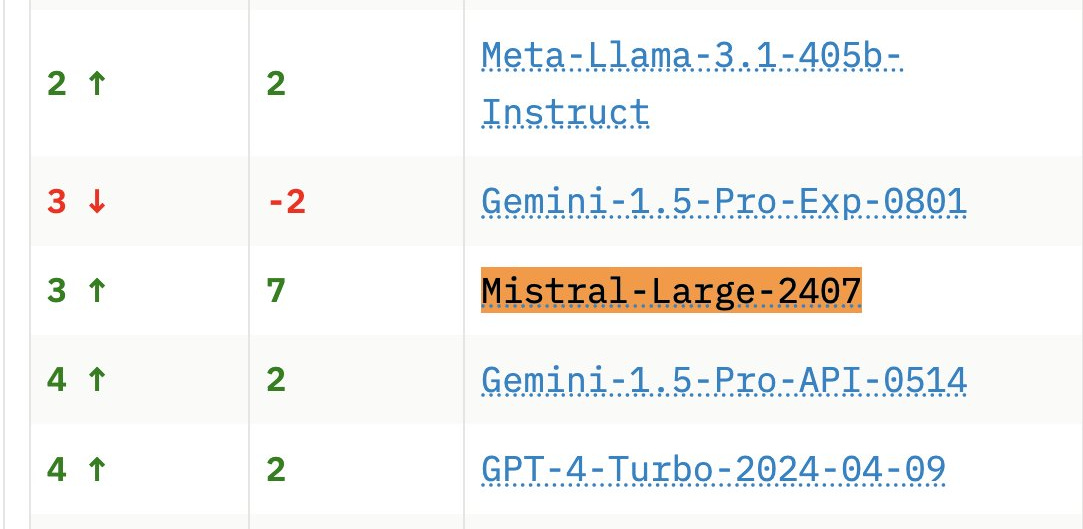
With a fresh $6B in the bank, xAI has unveiled Grok-2 and a smaller Grok-2-mini. The family represents a significant performance improvement on 1.5, rivaling Claude 3.5 Sonnet and GPT-4o on a number of metrics. It also comes with a glitzy new interface for X Premium users.
However, xAI has opted to keep it closed. This isn’t entirely surprising, given they only made its predecessor open following community criticism around Elon Musk’s OpenAI lawsuit. Eagle-eyed Wharton Professor and AI author Ethan Mollick spotted a small curiosity in the X.ai terms of service. Unlike other model providers, the company appears to retain ownership of a user’s output and merely licenses it to them. The company said it would amend the wording and also clarify whether users can train models on Grok’s output.
After some light experimentation, we’ve been impressed by the models’ capabilities, but we’re yet to be sold on the value-add of the much-vaunted real-time X data. Currently, it primarily manifests itself as irrelevant clutter under otherwise high-quality output:
The battle for differentiation sometimes produces gimmicks, but other times, it yields useful adaptations. Anthropic’s introduction of prompt caching for Claude falls into the latter category. Essentially, this allows developers to cache frequently used context between API calls, like long documents, code bases, or a corporate knowledge. This will allow users to refer back to it in subsequent requests without having to burn rapidly through input tokens. Anthropic estimates this could reduce costs by up to 90%. It also marks a step towards more useful, personalized assistants.
On the subject of the differentiation wars, anyone who spends a lot of time on AI Twitter will have been unable to move for strawberry-related memes in recent weeks. This comes as OpenAI’s latest product, codenamed ‘Strawberry’ (and previously called Q*) advances through the pipeline. The product is thought to apply multi-step reasoning to boost performance on math and programming tasks and potentially power work around agents. It’s also allegedly being used to create high-quality synthetic data to help train future OpenAI releases. Strawberry has reportedly been demo-ed to national security officials.
This is a high-stakes moment for the company. Expectations are running high after it talked up the power of the still-unreleased GPT-5 and as it looks to raise more money. The then Q*’s capabilities were also part of the well-documented safety wars at OpenAI last year. We’re still seeing the long-tail of that conflict, with reportedly half of the AGI safety team thought to have left the organization now. We’re also seeing continued executive churn at the company, with co-founder and president Greg Brockman taking a leave of absence, while co-founder John Schulman has moved to Anthropic. Team Safety can enjoy a crum of reassurance, however, after Sam Altman confirmed that the US AI Safety Institute will get an early glimpse at any future foundation model releases.
🔬Research
Accurate computation of quantum excited states with neural networks, Google DeepMind. This work introduces a new computational method called NES-VMC for calculating excited states in quantum systems, particularly molecules. The method combines neural networks with quantum Monte Carlo techniques to accurately predict the properties of excited states, which are important for understanding how molecules interact with light.

NES-VMC was tested on a variety of molecules, ranging from simple atoms to more complex organic compounds like benzene. It performed well in predicting excitation energies and other properties, often matching or exceeding the accuracy of other advanced computational methods. The researchers demonstrated its effectiveness on several challenging cases that are typically difficult to model accurately.
A key advantage of NES-VMC lies in its simplicity and generality compared to other methods for calculating excited states. While the researchers focused on molecules in this study, they suggest the method could potentially be applied to other areas of physics where understanding excited states is important.
Achieving Human Level Competitive Robot Table Tennis, Google DeepMind. This work demonstrates the ability of robots to achieve amateur human-level performance in competitive play against unseen human opponents. The system integrates several key components: a hierarchical policy architecture with low-level controllers (LLCs) for specific skills and a high-level controller (HLC) for strategy, techniques for zero-shot sim-to-real transfer, and real-time adaptation to opponents. The LLCs are trained in simulation using reinforcement learning, while the task distribution is iteratively refined through cycles of real-world data collection and policy evaluation.

The system's performance was evaluated through 29 competitive matches against human players of varying skill levels. Overall, the robot won 45% of matches, demonstrating solid amateur-level play. It won all matches against beginners, 55% against intermediates, but lost all matches to advanced players. The robot exhibited an ability to adapt its strategy over the course of a match, often improving its performance in later games.
The system still has limitations, however. These include a difficulty handling very fast or high balls, challenges with extreme spin, and a weaker backhand compared to forehand (in some ways, this reads like the challenges an intermediate human player might have). The research points to several promising directions for future work, including improving spin detection, developing more sophisticated collision avoidance, and training on multi-ball scenarios to enhance strategic play.
Building, Benchmarking, and Exploring Perturbative Maps of Transcriptional and Morphological Data, Recursion, Genentech. This work presents a comprehensive framework for building, benchmarking, and exploring genome-wide perturbation maps of biology. The authors introduce a standardized terminology and methodology called EFAAR (Embedding, Filtering, Aligning, Aggregating, and Relating) for building these maps from large-scale genetic perturbation datasets. They also establish key benchmarks to assess map quality, including perturbation signal benchmarks and biological relationship benchmarks.

The researchers apply this framework to four recent genome-scale perturbation datasets, which employ different cell types, perturbation technologies, and readout modalities. They construct multiple maps from each dataset using various computational pipelines and evaluate their performance.
To demonstrate how these maps can be used to uncover new biology, the researchers examined two genes with unknown functions: C18orf21 and C1orf131. By analyzing the connections these genes had in different maps, they found evidence suggesting that C18orf21 might be involved in a complex called RNase MRP, while C1orf131 might be part of the small subunit processome. These findings align with and support recent research on these genes.
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, Sakana AI. This work presents an end-to-end framework to automate the generation of research ideas, the implementation of experiments, and the production of research papers. The researchers claim their LLM-powered reviewer evaluates the generated papers with near-human accuracy.

The researchers used it to generate example papers about diffusion, language modeling, and grokking. These were convincing at first glimpse and mimicked the form typically seen on arXiv, but contained some flaws on closer examination.
While an interesting idea, it has a few challenges that will likely limit its near-term applicability, including a lack of vision capabilities and standard LLM shortcomings in comparing the magnitude of different numbers. It also requires careful implementation to avoid unsafe behavior. Examples included importing unfamiliar Python libraries and modifying and launching its own execution script (e.g. to experiment timelines).
Also on our radar:
Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models, Carnegie Mellon University. Introduces MOHAWK, a new method for distilling knowledge from a large, pre-trained transformer model (teacher) to a smaller, subquadratic model (student) like a state-space model (SSM). It is able to distill a Mamba-2 variant (Phi-Mamba) using only 3B tokens and a hybrid version (Hybrid Phi-Mamba) using 5B tokens. Using less than 1% of the training data typically required, Phi-Mamba significantly outperforms all existing open-source non-Transformer models.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning, DeepSeek-AI. Presents the Fire-Flyer AI-HPC architecture, which uses 10,000 A100 GPUs in a two-layer fat-tree network topology, integrating computation and storage. Thanks to a number of innovations (including HFReduce for efficient all-reduce operations and a high-throughput 3FS distributed file system), the researchers claim to achieve 80% of DGX-A100 performance at half the cost and 40% less energy consumption.
Sapiens: Foundation for Human Vision Models, Meta Reality Labs. Introduces a family of large-scale vision transformer models specifically designed for human-centric tasks. These models are pre-trained on a massive dataset of 300M human images using a masked autoencoder approach, then fine-tuned for four key tasks: 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction. The models operate at a high native resolution of 1024x1024 pixels and range in size from 300M to 2B parameters. By leveraging domain-specific pre-training on human images and high-quality annotations, Sapiens achieves SOTA performance across various benchmarks, demonstrating strong generalization to in-the-wild scenarios.
AlphaFold predictions of fold-switched conformations are driven by structure memorization, National Institutes of Health. Focusing particularly on complex fold-switching proteins, this paper argues that AlphaFold has limitations in truly understanding protein folding and is heavily reliant on memorization. They found that AlphaFold could predict about 35% of fold-switching proteins that it had likely seen before, but only 1 out of 7 truly novel ones. Its own confidence measures actually worked against finding the correct fold-switching structures.
Instruct-SkillMix: A Powerful Pipeline for LLM Instruction Tuning, Princeton, Meta AI. Introduces Instruct-SkillMix, a novel approach for creating high-quality synthetic data for instruction tuning of LLMs. The method extracts core "skills" from existing datasets or by directly prompting a powerful LLM. It then generates diverse (instruction, response) pairs by combining random skills. Supervised fine-tuning on 4,000 examples yields SOTA performance on instruction-following benchmarks for models that have only undergone SFT, outperforming proprietary instruct versions and competing with much larger models. The authors also demonstrate a "negative Pareto principle" where low-quality data disproportionately harms model performance, potentially explaining difficulties in previous open-source instruction tuning efforts.
A Preliminary Report on Distro, Nous Research. Provides a preliminary update on DisTrO, a novel family of distributed optimizers that significantly reduces inter-GPU communication requirements during neural network training. In this preliminary report, the authors demonstrate that DisTrO-AdamW matches the convergence rate of standard AdamW (a common optimization algorithm) with All-Reduce while reducing bandwidth needs by 857 times during pre-training of a 1.2B parameter language model. This theoretically could help enable efficient training over consumer-grade internet connections and heterogeneous hardware.
Compact Language Models via Pruning and Knowledge Distillation, NVIDIA. In line with research pointing to the potential to cut back deeper LLM layers, this work takes a more radical approach by pruning layers, neurons, attention heads, and embeddings, and then using knowledge distillation for efficient retraining. The MINITRON models, derived from Nemotron-4 15B, achieved comparable or superior performance to models like Mistral 7B and Llama-3 8B while using up to 40x fewer training tokens.
Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation, UC Berkeley, Carnegie Mellon University. Introduces a flexible transformer-based policy that can handle multiple, diverse robot embodiments. Trained on the largest and most diverse robot dataset to date, comprising 900,000 trajectories across 20 different robot types, including single and dual-arm manipulation systems, wheeled robots, quadcopters, and quadrupeds. The researchers find that it both outperforms the SOTA for cross-embodiment learning and can match the performance of individual specialist policies.
💰Startups
🚀 Funding highlight reel
Abnormal Security, the human behavior security platform, raised a $250M Series D, led by Wellington Management.
Anduril, the AI defense challenger, raised a $1.5B funding round, led by Founders Fund and Sands Capital.
Black Forest Lab, developing generative models for images and videos, raised a €28M seed, led by a16z.
Cassidy, working on enterprise automation, raised a $3.7M seed round, led by The General Partnership.
Contextual AI, creating customizable language models for enterprise, raised an $80M Series A, led by Greycroft.
Cribl, the enterprise data platform, raised a $319M Series E, led by GV.
Cursor, an AI-powered code editor, raised a $60M Series A, led by a16z.
Granola, the AI note-taking application, has raised a $19M round, led by Spark Capital.
Groq, building specialist chips for inference, raised a $640M Series D, led by Blackrock.
Healx, using AI for drug discovery, raised a $47M Series C, led by R42 Group and Atomico.
Hedra, the AI content creation tool, raised a $10M seed round, led by a16z, Abstract Ventures, and Index Ventures.
Lakera, the LLM security platform, raised a $20M Series A, led by Atomico.
Protect AI, building a cybersecurity platform for AI, raised a $60M Series B, led by Evolution Equity Partners.
Reliant, providing AI-powered analytics for biopharma, raised a $11.3M seed round, led by Tola Capital and Inovia Capital.
Tezi, the AI-powered recruitment platform, raised a $9M seed round, led by 8VC and Audacious Ventures.
Zoe, the nutrition company, raised a $15M Series B extension from Coefficient Capital.
🤝 Exits
Datum Source, a supply chain automation start-up, was acquired by Hadrian.
Exscientia, the NASDAQ-listed AI-first drug discovery firm, is to be acquired by NASDAQ-listed Recursion Pharmaceuticals for $688M.
Robust Intelligence, specialists in AI model security and governance, is to be acquired by Cisco.
XetHub, a collaboration platform for developers, has been acquired by Hugging Face.
ZT Systems, the server maker, is to be acquired by AMD, for $4.9B.
Covariant, the warehouse robotics company, was pseudo-acquired by Amazon.
Signing off,
Nathan Benaich and Alex Chalmers 31 August 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | Events
Air Street Capital invests in AI-first entrepreneurs from the very beginning of your company-building journey.
