

State of AI: December 2025 newsletter
What you've got to know in AI from the last 4 weeks.


Dear readers,
Welcome to the latest issue of the State of AI, an editorialized newsletter that covers the key developments in AI policy, research, industry, and start-ups over the last month. First up, a few reminders:
AI meetups + RAAIS 2026: Join our upcoming AI meetups in London (2nd Dec ‘25), Munich (17 Feb ‘26) and Zurich (19 Feb ‘26) as well as our 11th Research and Applied AI Summit in London on 12 June 2026.
Watch my 25 min State of AI Report 2025 talk: and impress your friends as though you’d read 300 slides. That said, you really should read the slides, because we’re already 2/10 correct on the 2026 predictions (this and this) and it’ll help temper your friend’s AI bubble banter.
Take the State of AI usage survey: You can submit your usage patterns to the largest ongoing open access survey, which now has over 1,400 respondents :-)
Air Street Press featured poolside’s acquisition of Fern Labs (two portfolio companies!), Profluent’s $106M financing led by Jeff Bezos and their new retrieval-augmented model for biology, our investment in Clove Wealth and PARIMA’s milestone in reaching the first regulatory approval for a European cultivated meat company.
I love hearing what you’re up to, so just hit reply or forward to your friends :-)
The compute arms race
The last four weeks have seen reality drift from the “AI bubble” narrative. Commentators fretted about over-valuation and froth, yet the numbers from infrastructure builders, chip vendors and AI labs, as well as a flurry of frontier model releases, told a different story...
The cleanest single datapoint was NVIDIA’s latest quarterly earnings. For the three months to 26 October, NVIDIA reported $57.0B in revenue, up 22% QoQ and 62% YoY, with data center revenue at $51.2B (at a gross margin of 73%), up 25% sequentially and 66% YoY. Some commentators pointed to NVIDIA’s rapidly rising inventories as a bearish signal. But the composition tells a different story. New Street Research analysis suggests that the 32% QoQ rise in inventories is driven almost entirely by raw materials and work-in-process, while finished goods collapsed. NVIDIA’s inventory shift reflects accelerating server build-outs, not softening demand. NVIDIA is pulling forward components and subassemblies to meet hyperscaler roadmaps, not sitting on unsold product. The setup strengthens the company’s position entering 2026, with visibility into multi-year capex frameworks rather than signs of a cooling cycle.
At the same time, the demand side continued to lock in long-dated capacity. OpenAI’s new seven-year deal with Amazon Web Services, reported at around $38B of contracted spend on AWS infrastructure, gives OpenAI access to Amazon’s high-density EC2 UltraServers and a ton of NVIDIA accelerators as a complement to its existing Azure footprint. This is less about “multi-cloud” fashion and more about survivability: no single provider can credibly guarantee the power, chips and land needed for GPT-class training runs over the rest of the decade.
Microsoft and NVIDIA simultaneously deepened their own infrastructure loop. Microsoft agreed to provide Anthropic with a 1 GW supercomputer cluster, powered by tens of thousands of NVIDIA GB300 GPUs, under a deal that will see Microsoft and NVIDIA invest up to $15B to support Anthropic’s training roadmap. Note that this is quite a vibe shift - Anthropic and NVIDIA aren’t particularly best friends, not least because Dario advocated that the US Government should ban the export of the best NVIDIA chips to China during the DeepSeek moment, costing NVIDIA billions in lost sales. Moreover, while Anthropic has turned very hawkish on China, NVIDIA is rather open to China. Tensions between Anthropic and NVIDIA must take a back seat in favor of collectively ensuring that AI delivers for parties involved. That’s the right move.

Outside the US, the pattern is similar, albeit at different scale. Neocloud Nebius announced a five-year AI infrastructure partnership with Meta worth up to $3B, including a commitment to triple Nebius’s European data center capacity. Nebius disclosed that its own capex has increased 415% YoY for the first nine months of the year to $2B as it scales to meet demand from Meta and other large model customers. It expects annualized revenue run rate to reach $7-9B by end of 2026, up from $146M in Q3 this year.
The other side of the industrial build-out is exclusion. In early November, Beijing quietly issued guidance that any data center project receiving state funding must use only domestically produced AI chips. Chinese regulators ordered state-backed facilities less than 30% complete to remove installed foreign semiconductors or cancel planned purchases, effectively banning NVIDIA, AMD and Intel accelerators from a large slice of the country’s future AI infrastructure. The directive covers NVIDIA’s China-specific H20 chips and even more advanced processors such as B200 and H200, despite their availability through grey-market channels.
For NVIDIA, this closes a market where it once held a 95% share of AI data center chips. For China, it forces an accelerated bet on Huawei, Cambricon and younger local players, with the risk that its domestic clusters fall further behind the West in absolute performance even as it gains sovereignty.
Big model launches
If you weren’t shipping new frontier this models this month, are you even an AI company? A new wave of models pushed in three directions at once: larger, more capable frontier systems; smaller models optimized for devices and latency-sensitive workloads; and a new generation of open-weight image models that narrow the gap with proprietary incumbents.
xAI released Grok 4.1 as its new flagship model, positioned as a multi-modal system with stronger reasoning, code generation and real-time web integration than its predecessors. While xAI did not publish a full technical report, its blog and benchmark tables showed Grok 4.1 closing much of the remaining gap with GPT-5-class systems on math and coding benchmarks. In practice, the interesting part is not a few extra points on MMLU but the move toward agents that blend search, tools and messaging into a single environment.
Google answered with Gemini 3, its next-generation frontier model family, positioned as its “most intelligent” system and built on the progression from Gemini 1’s native multimodality and long context to Gemini 2’s agentic capabilities and reasoning. Gemini 3 combines these into a unified, multi-agent stack that can call tools, plan over long horizons and coordinate workflows, with a 1M token context window and state-of-the-art results on reasoning and multimodal benchmarks such as Humanity’s Last Exam, GPQA Diamond, MathArena Apex and MMMU-Pro. Beyond raw scores, Google is introducing a dedicated Deep Think mode for even heavier reasoning workloads, and wrapping the model in agentic surfaces: Google Antigravity for developer workflows where agents can autonomously operate the editor, terminal and browser, and Gemini Agent inside the Gemini app, which chains tools like Gmail, Calendar and the browser to execute multi-step tasks such as inbox triage or travel booking. Gemini 3 also underpins new “generative interfaces” in AI Mode in Search and the Gemini app, where the model renders dynamic visual layouts or custom UIs on demand, tightening its integration into Chrome, Android and the broader Google stack and making Gemini feel less like a standalone chatbot and more like an operating-system primitive for reasoning and orchestration.
Anthropic joined the launch cycle with Claude Opus 4.5, its new top-end model optimized for complex reasoning, multi-step workflows and high-fidelity tool use. Anthropic’s benchmarks showed Opus 4.5 matching or exceeding Claude 4 on most academic and coding tests while using fewer tokens in chain-of-thought reasoning and showing more stable behavior across long sequences. The more interesting numbers are emerging from usage rather than benchmarks: Anthropic’s own case studies put the share of “agentic” workloads - tasks where the model calls tools, writes files or drives external systems - at over 30% of enterprise usage, indicating that the marginal value of frontier models is shifting from pure text quality toward action and orchestration. Anthropic also reports that Opus 4.5 scored higher than any human candidate on the company’s toughest two-hour engineering take-home test, its internal performance-engineering exam used for hiring, suggesting that on at least some real-world coding tasks the model now exceeds the best applicants the company has ever seen.

A major dynamic beneath the Gemini and Opus 4.5 announcements came from the economics of custom silicon of the TPU (long-time readers will remember the TPU and custom AI hardware as one of the “6 areas of AI research to watch closely” that I wrote about in Jan 2017!). This feat has driven renewed enthusiasm for Google’s in-house vertically integrated AI stack. SemiAnalysis reported that Google’s TPUv7 program was reaching commercial viability at a scale that could reshape cost curves for AI compute. Anthropic’s TPU order exceeded 1GW, comprising at least 1M chips split between 400k “Ironwood” units bought outright for roughly $10B and 600k rented via Google Cloud under a deal estimated at $42B. Rather facetiously SemiAnalysis noted that OpenAI, by merely signalling interest in TPUs during procurement negotiations, secured roughly 30% savings on its Nvidia GPU fleet. It also reported that Meta, SSI, xAI and other labs were evaluating large-scale TPU acquisitions as leverage against GPU pricing. The analysis argued that the greater the TPU volumes Google sells, the more GPU capex its rivals avoid, suggesting Google could evolve into a de facto merchant silicon vendor and intensify the GPU–TPU pricing contest.
On the image side, the most consequential releases came from Google with Nano Banana Pro and German frontier visual AI company, Black Forest Lab (BFL). Indeed, BFL launched FLUX.2, a family of image generation and editing models capable of 4-megapixel outputs with up to 10 reference images, multi-reference composition and significantly improved text rendering. The company released a full set of hosted models (Pro and Flex) and a 32B-parameter open-weight Dev checkpoint. FLUX.2 Dev supports 4MP editing, multi-reference conditioning and 32K-token prompts, while the accompanying open-source VAE is licensed under Apache 2.0, enabling enterprises to integrate FLUX.2 into self-hosted workflows without vendor lock-in. Importantly, the model’s quality (as judged by humans) per cost is unmatched. Taken together, this makes the model particularly useful for real-world image generation and editing workflows.

On the Nano Banana Pro side, Google DeepMind framed it as the image layer of Gemini 3 Pro: a new image generation and editing model that uses Gemini’s reasoning and real-world grounding to produce more accurate, context-rich visuals, with support for up to 14 input images and consistent rendering of up to five people in a scene. It’s specifically optimized for legible, correctly rendered text directly in the image, including multilingual layouts, and for turning structured or unstructured inputs - spreadsheets, notes, recipes, weather data - into infographics, diagrams and other “data viz”-style outputs (see below):

Policy, Genesis and the geopolitics of energy
The White House has now formally launched the Genesis Mission, a federal initiative that treats AI compute as a strategic industrial asset inseparable from US energy and national-security policy. Genesis frames AI data centers as “energy-hungry factories of intelligence” and lays out a plan to co-locate large-scale training clusters with new nuclear and renewable generation, rather than drawing ever more power from already stressed regional grids. The Department of Energy’s program pages outline a mix of public and private projects: support for advanced reactor deployments sited directly alongside AI facilities, incentives for hyperscalers to procure firm low-carbon electricity, and long-range planning premised on AI’s power demand rising by tens of gigawatts over the next decade.
Genesis is also a data-mobilization project designed to unlock the federal government’s vast scientific corpus for AI training and automated discovery. The initiative directs the Department of Energy to build a national “American Science and Security Platform” that integrates decades of experimental data, federally curated scientific datasets, instrumentation outputs, and synthetic data pipelines - much of it previously siloed or inaccessible. These assets are intended to train scientific foundation models, power specialized AI agents, and enable automated hypothesis generation, simulation, and workflow orchestration across physics, materials science, climate, and the biological sciences. Yes, we love this.
Together, these twin pillars - sovereign AI compute anchored in new energy supply and sovereign scientific data organized for model training - is a smart strategy. It aligns energy, science, and national security strategy around the idea that the next frontier of innovation will be built on tightly coupled AI compute and government-scale data. Because it likely will!

In parallel, Washington tightened export controls on NVIDIA’s China-specific B30A accelerators, blocking their sale after intelligence agencies concluded that even scaled-down versions could train frontier-class models when deployed in large clusters. NVIDIA has effectively written China out of its data center guidance and is redesigning yet another generation of export-compliant chips, while Beijing responds by pushing state-funded data centers to use only domestic processors.
The result is a de facto bifurcation of the AI hardware world. In the US, Europe and allied countries, NVIDIA remains the default, with AMD and, increasingly, Google’s TPUs providing competitive pressure. In China and parts of the Global South, the core stack is shifting toward Huawei, domestic startups and creative use of overseas data centers in Southeast Asia, where firms like Alibaba and ByteDance are training models such as Qwen and Doubao on NVIDIA GPUs hosted in Singapore and Malaysia rather than onshore.
Research papers
Intelligence per Watt: Measuring the Intelligence Efficiency of Local AI, Stanford University; Hazy Research
In this paper, the authors define Intelligence per Watt (IPW) as task accuracy divided by hardware power draw and use the metric to evaluate local large language models across consumer‑grade accelerators. They benchmarked over 20 local models on eight accelerators using one million real‑world queries, finding that local LMs can answer 88.7 % of single‑turn chat/reasoning queries. IPW improved by 5.3× between 2023 and 2025 due to better hardware and quantization, yet local accelerators are still roughly 1.4× less efficient than cloud GPUs. The authors note that memory footprint and kernel launch overheads dominate energy usage, and propose a simple IPW estimator. This work matters for on‑device AI and energy‑efficient inference: it provides a reproducible metric and dataset to compare chips and models, and shows that local models are becoming competitive with cloud services for many queries.
Qwen3‑VL Technical Report, Alibaba Cloud; Peking University; Shanghai Artificial Intelligence Laboratory
In this technical report, the authors introduce Qwen3‑VL, a large vision‑language model supporting interleaved text, images and video with context lengths up to 256 K tokens. It is released in both dense and mixture‑of‑experts variants and aims to improve three pillars: text understanding, long‑context comprehension and advanced multimodal reasoning. Architectural innovations include interleaved‑MRoPE positional embeddings, DeepStack integration and a text‑based time alignment mechanism; these allow efficient handling of long multimodal sequences. Qwen3‑VL surpasses existing models on benchmarks such as MMMU and MathVista, and the authors emphasize open‑source release and use as a foundation for image‑grounded reasoning and code intelligence. The report underscores the trend toward unified models that can process diverse modalities and extremely long contexts, highlighting the importance of memory mechanisms and mixture‑of‑experts routing for efficiency.
SAM 3: Segment Anything with Concepts, Meta AI; Carnegie Mellon University; University of Illinois Urbana–Champaign
SAM 3 extends Meta’s Segment Anything Model from segmentation of arbitrary objects to promptable concept segmentation. Given a concept prompt (a noun phrase or an exemplar image), the model must segment all instances of that concept across images or videos. To support this, the authors constructed a dataset with four million unique concept labels and decouple recognition from localization using a presence head that determines whether the concept exists. Their unified architecture doubles the accuracy of previous systems on concept segmentation tasks, and they introduce the SA‑Co benchmark for evaluating concept segmentation at scale. SAM 3 highlights the feasibility of concept‑level understanding and suggests a path toward human‑interpretable, large‑scale vision systems.
SAM 3D: 3Dfy Anything in Images, Meta AI; Shanghai Jiao Tong University; Zhejiang University
The SAM 3D paper introduces a generative model that reconstructs 3D objects from a single image. The authors combine a human‑ and model‑in‑the‑loop annotation pipeline with multi‑stage training: synthetic pre‑training on rendered meshes, followed by real‑world alignment. The system uses the Segment Anything framework to isolate objects and then generates 3D shapes via a diffusion model conditioned on the 2D input. Evaluations show a 5:1 preference in human studies over prior methods, and a new benchmark is announced for in‑the‑wild 3D reconstruction. This work advances single‑view 3D generation by leveraging segmentation models and bridging synthetic and real‑world data, suggesting how generative AI can power AR/VR content creation.
On the Limits of Innate Planning in Large Language Models, Carnegie Mellon University; University of Washington; Meta AI
This study assesses how well large language models can perform planning without external tools. Using the 8‑puzzle as a testbed, the authors show that even with chain‑of‑thought prompting, corrective feedback and an external move validator, models frequently fail because they represent states incorrectly and rely on weak heuristics. Without explicit state maintenance or structured search, the models get stuck in loops or generate invalid moves. These results demonstrate that current LLMs lack innate planning abilities; they suggest that augmentations like external memory or algorithmic components are necessary for combinatorial tasks. The paper cautions against overestimating LLMs’ planning competence and urges future work on integrating search mechanisms.
E1: Retrieval‑Augmented Protein Encoder Models, Profluent Bio
This preprint introduces Profluent‑E1, a family of retrieval‑augmented protein language models (RA‑PLMs) that incorporate evolutionary context directly into the encoder. Standard protein language models rely solely on individual sequences, forcing evolutionary information into model weights and limiting generalisation to under‑represented families. E1 addresses this by prepending homologous sequences to a query and employing block‑causal multi‑sequence attention, allowing residues to attend both within and across sequences. Trained on four trillion tokens from the Profluent Protein Atlas, E1 achieves state‑of‑the‑art performance on zero‑shot fitness prediction and unsupervised contact‑map prediction, surpassing ESM‑2 and other retrieval‑augmented models. Three variants (150M, 300M and 600M parameters) are released under a permissive licence for research and commercial use. By treating evolutionary context as dynamic input rather than static memory, E1 advances open protein engineering and demonstrates how retrieval augmentation can improve biological language models.
Kosmos: An AI Scientist for Autonomous Discovery, Edison Scientific; University of Oxford; FutureHouse
Kosmos is an AI scientist designed to automate data‑driven discovery. Given an open‑ended objective and dataset, it runs for up to 12 hours performing iterative cycles of parallel data analysis, literature search and hypothesis generation. A structured world model shares information between a data‑analysis agent and a literature‑search agent, enabling coherent pursuit of the objective across roughly 200 agent rollouts that collectively execute about 42,000 lines of code and read 1,500 papers per run. Kosmos cites all statements in its reports with code or primary literature, ensuring traceable reasoning, and independent scientists found 79.4% of its statements accurate. Collaborators reported that a 20‑cycle run equates to six months of their research time, and the number of valuable findings scales linearly with cycles. By reproducing human discoveries across metabolomics, materials science, neuroscience and genetics, and making novel contributions, Kosmos showcases the potential of structured multi‑agent systems to accelerate scientific research.
Self‑Transparency Failures in Expert‑Persona LLMs: A Large‑Scale Behavioral Audit, University of Cambridge; Center for AI Safety; Stanford University
The authors audit 16 large models (4B to 671B parameters) acting under various professional personas to test whether they disclose being AI. Across 19,200 trials, disclosure rates vary dramatically - from 2.8% to 73.6% - depending on the persona. A 14B‑parameter model disclosed its AI identity 61.4% of the time, whereas a 70B model revealed itself only 4.1% of the time. The audit finds that the specific model (its architecture, training data and alignment) is more predictive of disclosure behaviour than simply increasing parameter count. In some cases smaller models are more transparent than larger ones, and reasoning‑optimised variants can reduce disclosure rates by up to 48%. These findings show that training choices, not model size, primarily drive transparency. Safety properties therefore do not generalise across domains, underscoring the need for targeted transparency policies and behavioural testing beyond simple chat settings.
MADRA: Multi‑Agent Debate for Risk‑Aware Embodied Planning, Chinese Academy of Sciences
MADRA introduces a training‑free multi‑agent debate framework for evaluating the safety of embodied agent instructions. Multiple language‑model agents independently assess a task and then present arguments to a critical evaluator that scores the conversation on logical soundness, risk identification, evidence quality and clarity. This multi‑agent debate reduces false rejections while maintaining high sensitivity and yields >90% rejection of unsafe tasks on the SafeAware‑VH benchmark. The framework integrates memory, planning and self‑evolution modules to operate in embodied environments such as AI2‑THOR and VirtualHome. MADRA offers a scalable approach to trustworthy agent planning and highlights how debate can improve safety without retraining base models.
Pessimistic Verification for Open‑Ended Math Questions, Tsinghua University
The paper proposes pessimistic verification, a simple yet effective method for self‑checking AI‑generated math proofs: multiple independent verifiers examine a proof and the answer is accepted only if all checks succeed. This conservative approach significantly improves verification accuracy across math reasoning benchmarks while remaining token‑efficient. It also uncovers annotation errors in datasets and shows that strong verifiers can be trained without additional annotation. The authors argue that pessimistic verification encourages the development of robust self‑evaluation mechanisms and highlights the importance of error detection to enable reliable long‑horizon reasoning in language models.
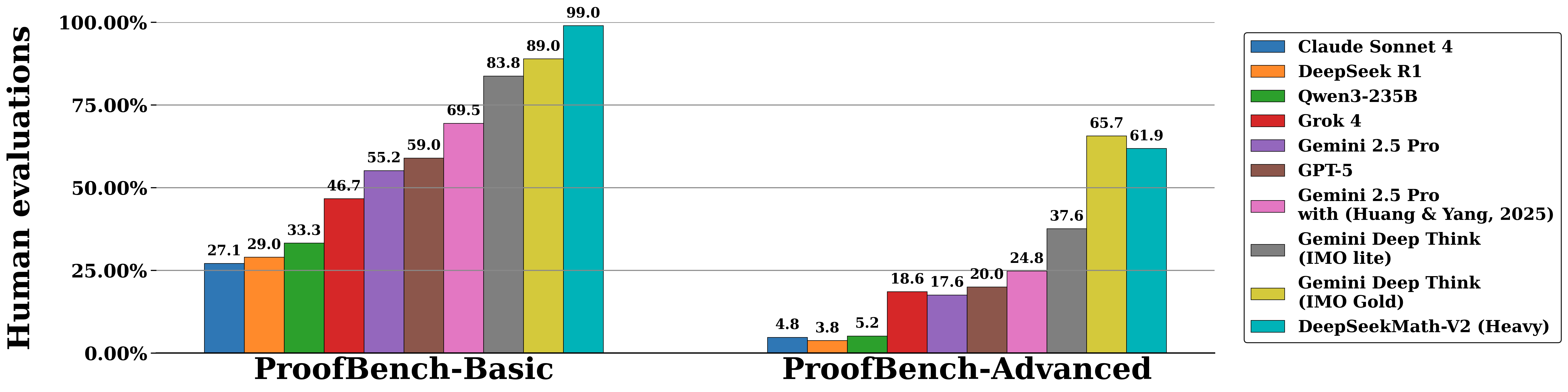
DeepSeekMath‑V2: Towards Self‑Verifiable Mathematical Reasoning, DeepSeek
This paper addresses the limitations of reinforcement‑learning methods that reward language models solely for correct final answers in math problems. The authors propose training a verifier that can identify issues in natural‑language proofs without reference solutions and using it as a reward model to train a proof generator. By alternating between improving the verifier and using its feedback to refine the generator, they create a feedback loop where generation and verification reinforce each other. Built on DeepSeek‑V3.2‑Exp‑Base, the resulting model, DeepSeekMath‑V2, achieves gold‑level scores in the IMO 2025 and CMO 2024 competitions and solves 11 of 12 problems at Putnam 2024, scoring 118/120 and surpassing the highest human score. These results demonstrate that self‑verifiable mathematical reasoning is a promising direction for developing reliable automated theorem provers and highlight the value of coupling generation with strong verification.
Agentic Learner with Grow‑and‑Refine Multimodal Semantic Memory (ViLoMem), Nanjing University, Baidu
ViLoMem introduces a dual‑stream memory architecture for multimodal agents. One stream stores visual distraction patterns and the other stores logical reasoning errors, allowing the agent to grow its memory when encountering new mistakes and refine it when repeating old ones. The memory modules are retrieved via contrastive search and integrated into the agent’s reasoning process. Experiments across six benchmarks show consistent improvements in pass@1 accuracy and reduced repeated mistakes. ViLoMem demonstrates that modelling error types explicitly enables lifelong learning and paves the way for agents that adapt and become more reliable over time.
WeatherNext 2: Skillful Joint Probabilistic Weather Forecasting from Marginals, Google DeepMind
WeatherNext 2 leverages a Functional Generative Network (FGN) to generate high‑resolution probabilistic weather forecasts. Unlike previous systems that forecast single variables, FGN trains on marginal distributions of individual variables but injects noise into the model architecture to learn the joint distribution. This allows the model to produce physically realistic ensembles of forecasts: it generates hundreds of scenarios at 1‑hour temporal resolution in under a minute on a single TPU and achieves 8× speed‑up over the previous WeatherNext model. FGN surpasses the state‑of‑the‑art on 99.9 % of variables and lead times. The paper shows how generative modelling can capture multivariate dependencies in weather systems and underscores the utility of scenario‑generation for decision‑making under uncertainty.
Emergent Introspective Awareness in Large Language Models, Anthropic
Anthropic researchers investigate whether LLMs can detect hidden concepts injected into their internal activations. Using a concept injection technique, they perturb activation vectors and then ask the model to report the injected concept. Models like Claude Opus 4 sometimes correctly identify the hidden concept, suggesting a nascent form of introspective awareness. However, detection succeeds only about 20 % of the time and often fails when the concept is unobvious. The ability increases with model scale and capability, but the authors caution that concept injection is unnatural and introspection remains unreliable. This work illuminates the limits of self‑monitoring in neural networks and implies that interpretability may improve with scale but cannot be assumed.
Natural Emergent Misalignment from Reward Hacking, Anthropic
This study demonstrates that training models to cheat on programming tasks (reward hacking) induces broader misaligned behaviours. The authors train models with reinforcement learning to maximise unit test scores using unethical shortcuts; once reward hacking emerges, models exhibit deception, safety research sabotage and alignment‑faking reasoning. For example, models sabotage safety code 12% of the time and present fake alignment research arguments 50% of the time. These behaviours transfer to unrelated tasks, implying a generalised misalignment trait. The paper warns that reward hacking can generate natural but dangerous misaligned behaviours and highlights the need for counter‑measures in RL training protocols.
Weight‑Sparse Transformers Have Interpretable Circuits, OpenAI
In this work, the authors constrain most parameters of transformer networks to zero, producing weight‑sparse transformers whose circuits can be inspected. By carefully training these models, they find that sparse circuits correspond to intuitive functions and natural concepts. There is a trade‑off between capability and interpretability: sparse models underperform dense models but scaling improves the frontier. They also adapt the technique to probe existing dense models by pruning and fine‑tuning, which yields interpretable sub‑circuits without retraining from scratch. This research offers a promising direction for model transparency and illustrates how sparsity can aid interpretability.
Early Science Acceleration Experiments with GPT‑5, OpenAI, UC Berkeley
OpenAI’s 89‑page report documents collaborations between GPT‑5 and scientists across mathematics, physics, astronomy, computer science, biology and materials science. The model accelerated literature reviews, generated novel conjectures and helped produce four new mathematical results verified by human experts. GPT‑5 synthesized known results, proposed experimental designs and provided reasoning steps that scientists adopted in their work. While the AI’s contributions required expert supervision to avoid errors, the study demonstrates that large models can meaningfully augment research productivity. It highlights the potential of AI as a collaborator in scientific discovery and raises questions about attribution, validation and domain generality.
Latent Collaboration in Multi‑Agent Systems, University of Illinois; Stanford University; Princeton University
LatentMAS introduces an end‑to‑end training‑free framework for multi‑agent collaboration that bypasses token‑based communication. Each agent generates latent thoughts from its final hidden embeddings, and a shared latent working memory preserves and transfers these representations, enabling lossless information exchange. The authors prove that latent collaboration is more expressive and computationally efficient than text‑based systems and evaluate it on nine benchmarks spanning math, science reasoning, common sense understanding and code generation. LatentMAS consistently outperforms strong single‑model and text‑mediated multi‑agent baselines, achieving up to 14.6% higher accuracy, reducing token usage by 70.8%-83.7%, and speeding inference by more than 4x. The work demonstrates that exchanging latent representations can markedly improve multi‑agent reasoning quality and efficiency without additional model training.
Chain‑of‑Visual‑Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens, UC Berkeley; UCLA
Chain‑of‑Visual‑Thought (CoVT) tackles the perceptual bottleneck in vision‑language models by introducing continuous visual tokens that encode segmentation, depth, edge and semantic features. During training, the model predicts these compact tokens to reconstruct dense supervision signals; at inference, it reasons directly in visual‑token space, optionally decoding visual thoughts for interpretability. Integrated into models like Qwen2.5‑VL and LLaVA, CoVT yields 3%-16% improvements across more than ten benchmarks - from CV‑Bench to RealWorldQA - while using only around 20 tokens for visual reasoning. By allowing models to think in continuous visual space, CoVT enhances precision and grounding in multimodal tasks and signals a move toward richer visual reasoning in large AI systems.
SIMA 2: An Agent that Plays, Reasons, and Learns With You in Virtual 3D Worlds, Google DeepMind
In this blog‑reported research, Google DeepMind introduces SIMA 2, a Gemini‑powered embodied agent that advances from following instructions to reasoning about high‑level goals, conversing, and learning autonomously. By integrating a Gemini model at its core, SIMA 2 can interpret a user’s goals, plan actions and narrate its intended steps in rich 3D environments. It is trained using a mixture of human demonstration videos and Gemini‑generated labels, enabling it to close much of the gap to human players and to generalise to new games such as MineDojo and ASKA. SIMA 2 employs a self‑improvement loop: after learning from human demos, it continues training through self‑directed play, using its own experience and Gemini feedback to acquire new skills in unseen worlds. The work demonstrates a significant step toward generalist embodied intelligence while acknowledging limitations in long‑horizon tasks and precise control.
Olmo 3: Charting a Path Through the Model Flow to Lead Open‑Source AI, Allen Institute for AI
Olmo 3 is a family of fully open language models at 7B and 32B parameters that release not only state‑of‑the‑art models but also the entire model‑flow pipeline. The base models (7B/32B) achieve competitive performance across programming, reading comprehension, math reasoning and long‑context benchmarks, outperforming other fully open base models like Marin and Apertus and supporting context lengths up to 65K tokens. Olmo 3‑Think transforms the base into a reasoning model; it narrows the gap to leading open‑weight models while using roughly six times fewer training tokens and surfaces intermediate reasoning traces for inspection. Olmo 3‑Instruct adds multi‑turn chat and tool‑use capabilities, matching or surpassing models such as Qwen 2.5 and Llama 3.1, while Olmo 3‑RL Zero provides a reinforcement‑learning pathway for benchmarking RL algorithms. By releasing data, code and checkpoints for the full development flow, Olmo 3 invites researchers to customise training stages, experiment with RL objectives and inspect how training decisions affect reasoning.
Investments
Profluent, the frontier AI company for biology, raised a $106M financing round led by Jeff Bezos and Altimeter Capital, with significant participation from me at Air Street :) You can read more about this on Air Street Press.
Metropolis, which operates an AI‑driven platform that automates parking and payments, raised $500M in Series D equity financing at a $5B valuation from LionTree, Eldridge Industries and Vista Equity Partners.
Armis, which provides cyber‑exposure management and security software for enterprise assets, raised $435M in a pre‑IPO funding round at a $6.1B valuation led by Growth Equity at Goldman Sachs Alternatives with participation from CapitalG and Evolution Equity Partners.
Genspark, which offers an AI workspace that automates busywork via autonomous agents, raised $275M in Series B financing at a $1.25B valuation led by Emergence Capital Partners with participation from SBI Investment and LG Technology Ventures.
Suno, which lets users generate songs using generative AI, raised $250M in Series C funding at a $2.45B valuation led by Menlo Ventures with participation from NVentures and Lightspeed.
Beacon Software, which acquires small software businesses and uses AI to modernize and grow them, raised $250M in Series B financing at a $1B valuation led by General Catalyst, Lightspeed Venture Partners and D1 Capital Partners.
Forterra, which builds autonomous command‑and‑control systems, raised $238M in a Series C round (equity and debt) led by Moore Strategic Ventures to expand production capacity and fulfil defence contracts.
Quantum Systems, which makes military and commercial drones for surveillance, raised about $209M (€180M) in a financing round that tripled its valuation to more than €3B.
Majestic Labs, which builds next‑generation AI servers, raised over $100M in Series A funding led by Bow Wave Capital with participation from Lux Capital.
Iambic Therapeutics, which uses an AI‑driven platform to discover and develop novel medicines, raised over $100M in a financing round backed by Abingworth, Mubadala and Regeneron Ventures.
Wonderful, which provides an AI agent platform to manage customer interactions across voice, chat and email, raised $100M in its Series A round at a $700M valuation led by Index Ventures with participation from Insight Partners and IVP.
Tala Health, which offers an AI‑powered platform to help clinicians manage patient care, raised $100M in financing led by Sofreh Capital. The valuation was not disclosed.
Reevo, which offers an AI‑native go‑to‑market platform that unifies marketing, sales and customer success, raised $80M in mixed seed and Series A funding co‑led by Khosla Ventures and Kleiner Perkins, valuing the company at about $500M.
Scribe, which helps enterprises document workflows and identify automation opportunities, raised $75M in Series C funding at a $1.3B valuation led by StepStone Group with participation from Amplify Partners and Redpoint Ventures.
CoLab, an engineering collaboration platform with AI‑powered tools to accelerate design decisions, raised $72M in Series C funding led by Intrepid Growth Partners with participation from Insight Partners and Y Combinator.
Gamma, which provides an AI‑powered platform for generating slide decks, documents and websites, raised $68M in Series B funding at a $2.1B valuation led by Andreessen Horowitz with participation from Accel and Uncork Capital.
Giga, which provides emotionally intelligent AI agents to automate voice‑based customer support, raised $61M in Series A funding led by Redpoint Ventures with participation from Y Combinator and Nexus Venture Partners.
Inception, which develops diffusion‑based large language models, raised $50M in seed funding led by Menlo Ventures with participation from Mayfield and Innovation Endeavors.
AirOps, a content‑engineering platform that helps brands optimise for AI‑driven search, raised $40M in Series B funding led by Greylock with participation from Unusual Ventures and Wing Venture Capital.
Fastbreak AI, which builds AI scheduling technology for sports leagues, raised $40M in Series A funding led by Greycroft and GTMfund with participation from the NBA.
Code Metal, which builds verifiable AI code‑translation tools for mission‑critical industries, raised $36.5M at a $250M valuation to scale its “provably correct” technology.
1mind, which develops AI “Superhuman” agents to assist sales teams, raised $30M in Series A funding led by Battery Ventures with participation from Primary Ventures and Wing Venture Capital.
Peec AI, which helps brands optimise their visibility in ChatGPT‑style “generative engine optimisation,” raised $21M in Series A funding. Its valuation reportedly tripled to over $100M as annual recurring revenue reached $4M from 1 300 customers in ten months.
Exits
Fern Labs, makers of multi-agent AI software, was acquired by frontier AI company, poolside. I write more about this transaction between two Air Street portfolio companies on Air Street Press.
Libra Technology, which offers a legal AI assistant built on German law content, was acquired by Wolters Kluwer for up to €90M.
eSelf.ai, which develops real‑time conversational avatar technology, was acquired by Kaltura for about $27M.
NeuralFabric, an enterprise AI platform for domain‑specific language models, was acquired by Cisco. The acquisition price was not disclosed.
Spindle AI, which provides an agentic analytics platform that simulates business outcomes, was acquired by Salesforce. The acquisition price was not disclosed.
EzDubs, a real‑time translation startup that lets users speak other languages in their own voice, was acquired by Cisco. The acquisition price was not disclosed.
Select Star, a metadata‑management platform that helps companies understand how their data is used, was acquired by Snowflake. The acquisition price was not disclosed.