




Dear readers,
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and start-ups over the last month. First up, a few updates:
To close out 2024, Nathan joined Daniel Bashir on The Gradient podcast to discuss highlights from the State of AI Report, while sharing some early takes on o3 and DeepSeek.
Congratulations to our friends at Sereact, who raised a €25M Series A led by Creandum, with backing from Air Street and Point Nine. You can read more about why we backed the team here.
Our events series is back for 2025. First up, we’ll be in Berlin and Munich in February, followed by Zurich in March. Subscribe to our events page to ensure you don’t miss out.
Our annual RAAIS conference is back on 13 June 2025, check it out.
Check out our latest writing on Air Street Press, where we’ve written about the vibe shift at Microsoft and Google on AI, the vibe shift on existential risk of AI, the Air Street 2024 Year in Review, and how NVIDIA dominates AI research.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
Pour one out for the Biden Administration’s executive order on AI safety. As was widely trailed before the election, the incoming Trump administration has scrapped it. Meanwhile, David Sacks has been tasked with developing a US AI action plan to remove the barriers to US companies, so they’re free to “develop AI systems that are free from ideological bias or engineered social agendas”. Beyond a mild weakening of frontier AI oversight and shouting about DEI, it’s yet unclear what this is likely to amount to practically.
That doesn’t mean big moves aren’t afoot elsewhere, especially around energy. Data center developers and tech companies will be pleased to see the new administration cut through a series of MIMBY-esque regulations, which allowed opponents of development to slow down proposals that obeyed every substantive environmental law with years of paperwork and legal battles. On the other hand, in a sign that US energy policy is the latest victim of the culture wars, new wind energy has faced a bunch of curbs, for reasons best understood by the new administration.
Elsewhere, President Trump signalled that tariffs of 25-100% were on their way for Taiwan-made chips to encourage the reshoring of production, despite having “a good meeting” with Jensen. In the same set of remarks, he suggested that the US would likely end subsidies for semiconductor fabs via the CHIPS Act, arguing that companies didn’t need it. Clearly he hasn’t been studying Intel’s balance sheet too closely… Maybe this is all part of a genius plan to force TSMC to announce more commitments to build out further US manufacturing capacity, but given the US demand for chips is relatively inelastic, the White House might be holding fewer cards than it thinks.
US tech, which seemed unassailable a few weeks ago, however, has suddenly found itself on the defensive. The late January DeepSeek panic - which saw the world finally wake up to the 2-year old Chinese quant-firm founded AI lab - has sent US tech stocks tumbling, launched a thousand different (generally poor) takes on the end of the US lead in AI, and has largely been used as an excuse by people to confirm their priors.
For us, DeepSeek R1 is an acceleration of a continuing trend, rather than something that’s come out of the blue. The DeepSeek team has already developed a track record of building highly capable, yet efficient, models and had demo-ed an early o1-style model towards the end of last year, R1-Lite-Preview, which we covered in the December issue of this newsletter. In fact, we first wrote about DeepSeek in December 2023 when they released their first LLM, DeepSeek 67B, which was better than Llama2 70B. For more, check out our State of Chinese AI essay from last year too. We’re now seeing the very same people whose AI bull case hinged on models becoming more efficient panicking … because models have become more efficient.
While people have mocked the likes of Satya Nadella for suddenly discovering the Wikipedia page for Jevons Paradox - the notion that improved efficiency leads to greater demand - we think it holds true here. Faster and cheaper AI will lead to more use of AI. Your take on whether or not NVIDIA is overvalued probably shouldn’t be affected by this news. Further, we politely remind naysayers that 91% of all AI research papers make use of NVIDIA hardware for their experiments:

If you want some cool-headed takes on DeepSeek, we enjoyed this interview on ChinaTalk from our friend Miles Brundage, who ran OpenAI’s policy research and AGI preparedness for several years. In it, he makes the case that sanctions are working and that if given the choice, DeepSeek would certainly rather have more, not fewer, top-range GPUs in its compute fleet.
While the US and China jostle for supremacy in the lab and X takes, the UK looks finally set to embrace AI action. Endorsing investor Matt Clifford’s AI Opportunities Plan, Prime Minister Keir Starmer vowed to “mainline AI into the veins” of the UK. The plan covers everything from plans to increase the UK’s compute capacity through to creating AI Growth Zones (think of them as designated geographical areas) that will feature reduced regulatory obstacles to new data center construction. The plan also covers off high-skilled immigration, procurement, and proposes the creation of UK Sovereign AI - a government-backed lab that will partner with the private sector to develop certain capabilities.
We commend the plan for its ambition, but given its scope and the limited time that Matt and team had to put it together, it remains top-level. The devil, as always, will be in its implementation. The UK has never lacked for consultations or units tasked with thinking about technology - they’ve usually withered on the vine due to a lack of interest from the top in taking action on the thinking. It’s up to the prime minister to decide if he’s serious about stabbing the AI needle into the patient. We can only hope that the Doctor is ready.
Note that the UK does have one thing going for it. It doesn’t suffer from the EU AI Act. The bill’s prohibition on certain high-risk AI systems comes into force from this weekend despite its original chief architect, Gabriele Mazzini, now feeling like it’s gone too far. Facepalm.
On the topic of Europe, the EU Commission led by Ursula von der Leyen announced “It is time to restart Europe’s innovation engine. We have the Compass. We have the political will. Now, what matters is speed and unity.” Interesting! The “Competitiveness Compass” is meant to drive “productivity through innovation”, increase “competitiveness with decarbonisation” (sounds a bit random, ngl), and “reduce dependencies, increasing resilience and security” (that’s worth a try). Let’s add some more detail into what this really means…ah, hang on, von der Leyen’s Competitiveness Compass is even more confusing, nonsensical, and certainly not how a compass works:

On the topic of AI, she went further: “Only 13.5% of EU businesses are using AI. This must change. This year we will launch a broad AI Strategy for our continent, including an ‘Apply AI' initiative to drive industrial adoption of Artificial Intelligence in key sectors." This is rather bizarre because a) the vast majority (if not all) serious AI vendors are US companies, b) several of them rate limit their best products from Europe due to the AI Act, and c) the fact that EU businesses will adopt US AI doesn’t solve the issue of “reducing excessive dependencies and increasing security”. So this whole plan seems to be backwards, which is rather unsurprising given how tone deaf and unplugged from reality European politicians are when it comes to enabling technology progress.
And to top it all off, our European notaries are back! Here, the Austrian notary association claims that notaries “contribute to simplifying and reducing bureaucracy in administrative processes”. Suggesting that Europe’s bureaucratic heritage and anti-innovation practices are an enabler of the EU Commission’s new pro-innovation agenda makes one feel that…it could be so over.
🍪 Hardware
Before the great DeepSeek panic, things were looking up for Team NVIDIA. The Trump Administration was quick to unveil Stargate, a joint venture tasked with building out $500B of infrastructure for OpenAI. SoftBank, OpenAI, Oracle, and MGX are the initial equity partners, with Microsoft, NVIDIA, Oracle, OpenAI, and Arm (note this is likely just because Arm CPUs feature in NVIDIA products) as the technology partners. While the White House fronted the launch, the government is not supplying any of the capital, and it’s unclear how much of a role it played in brokering the deal.
If you’re optimistic about AI (which the median reader of this newsletter probably is), it’s probably safe to ignore the various suggestions we’ve seen that the DeepSeek news makes Stargate redundant. It is fair, however, to express scepticism about how likely it is the deal will come together. While Elon Musk’s attacks on Stargate are in part motivated by his personal crusade against Sam Altman, it’s reasonable to ask where the money is coming from.
$500B over four years would require an average commitment of roughly $40B per equity partner per year. That’s more than the AUM of both Vision Funds combined and would burn through all of Oracle’s net tangible assets in under 18 months. This would come on top of SoftBank potentially investing $15-25B in OpenAI separately. This presumably isn’t what the Stargate consortium has in mind, but until they tell us, it’s fair to be sceptical.
But the question on everyone’s lips is whether Chinese chips are finally hitting the big leagues after a number of false dawns?
While DeepSeek’s R1 was trained on NVIDIA hardware, inference is (at least in part) being served by Huawei Ascend chips. Huawei has essentially acknowledged that it won’t be able to act as a serious NVIDIA competitor in the pre-training market for the foreseeable future, but is betting that inference will prove lucrative and that Chinese government pressure will drive it business. The logic is appealing for Huawei, but will involve the company resolving the production quality issues that have blighted Ascend manufacturing.
That said, NVIDIA’s China business looks healthy for some time to come. The company is set to be the primary beneficiary of ByteDance’s $12B AI hardware spending spree, scooping up $6.8B from cluster-building outside the US, along with a further chunk from buying sanctions-compliant chips for use in China.
🏭 Big tech start-ups
January hasn’t been all DeepSeek all the time. Some other things have happened around the world.
Now somewhat overshadowed, OpenAI has released its first browser agent - Operator. This follows in the footsteps of the Gemini team, who included one as part of their 2.0 release at the end of last year. Operator is currently in research preview, but is a computer-use agent that leverages 4o’s vision capabilities and RL-powered reasoning capabilities to interact with buttons, menus, and text fields.

It narrowly beats Claude’s Computer Use on computer and browser use benchmarks, but these aren’t the only differences. Computer Use is available via the API and can be deployed on any browser theoretically, whereas Operator is available via ChatGPT and boots up a virtual machine in the cloud.
As you’d expect, Operator is capable but far from perfect. As frontier labs continue creating … remarkably similar products, the battle to find an edge will only intensify.
On the subject of similar products, the catchily named Gemini 2.0 Flash Thinking Experimental - an early Gemini reasoning model was released this month. Thanks to the Gemini team’s frequently baffling approach to product comms, you’d likely only know this if you spend a lot of time on Google’s AI Studio or Vertex (why these are still separate confuses the hell out of everyone). This is not the way to bring about a vibe shift.
As well as releasing new products, OpenAI has been getting stuck into the DeepSeek discourse. While they publicly congratulated the DeepSeek team on reaching o1-levels of performance, they (and their major investors) also suggested that they used the outputs of OpenAI models as part of their training.
This would be a violation of OpenAI’s terms of service. OpenAI has not yet presented any evidence to support these claims. Further, it seems even slightly disingenuous to levy such claims when OpenAI itself hasn’t been entirely transparent with the sourcing of its own training data and relevant content use rights. In practise, TOS around distillation are very difficult to ever enforce, if it turned out that R1 did use the outputs of a significantly more expensive model at any scale, it would undermine claims about cost-efficiency slightly. But it would reinforce the arc of progress that models must become big before they can become smaller.
A day ago, a huge vibe shift went down on Reddit. OpenAI’s leadership team ran an AMA and what caught our eye was Sam’s response to a question about open source: “I personally think we have been on the wrong side of history here and need to figure out a different open source strategy.” He followed this up with saying that he expects OpenAI to continue to lead, but with “less of a lead than we did in previous years”.

Over in Europe, who remembers Mistral? France’s 2023 breakthrough company has seen the hype fade away, with reports of sluggish uptake and mounting investor skepticism. Its core differentiator around efficiency has also come under scrutiny in the light of DeepSeek-mania. But the team is continuing to ship, releasing Small 3, an open latency-optimized 24B model.
The instruction-tuned model performs competitively with significantly larger open and proprietary models. But one has to beg the question of whether this even matters anymore…The model has been released under an Apache 2.0 licence, rather than the more restrictive Mistral Research License, which forced users to negotiate commercial deployments separately.
Finally, to end this discussion, if the prevailing DeepSeek narrative is "look what can get created with talent density and limited resources", why is no one asking why Europe didn't produce a DeepSeek-grade model? It too has talent density and limited resources...but perhaps those stats are only to be used when they conveniently support the European bull case rather than question it.

🔬Research
Engineering of CRISPR-Cas PAM recognition using deep learning of vast evolutionary data, Profluent.
Introduces Protein2PAM, a deep learning model trained on a vast dataset of CRISPR-Cas systems to predict and engineer the recognition of protospacer-adjacent motifs (PAMs). PAMs are short DNA sequences that CRISPR-Cas enzymes must recognize to bind and edit genomic targets, but their specificity limits genome-editing applications. By training on over 45,000 PAM sequences from CRISPR systems, Protein2PAM accurately predicts PAM specificity based on protein sequences alone.

The researchers demonstrate Protein2PAM’s utility in protein engineering by using it to evolve variants of Nme1Cas9, a Cas9 enzyme with a strict PAM requirement. The model-guided mutations resulted in variants with expanded PAM compatibility and up to 50-fold improved cleavage rates. This marks the first successful application of machine learning in designing CRISPR enzymes with customized PAM recognition.
Beyond its predictive power, Protein2PAM provides insight into the biophysical principles of protein-DNA interactions. By way of in silico mutagenesis, the model identified amino acid substitutions that shift PAM preferences, confirming the role of specific residues in Cas9’s recognition mechanism. Experimental validation showed that engineered variants exhibited expected PAM shifts and enhanced activity. This is really exciting because it helps unlock the custom design of editors for target sequences.
A generative model for inorganic materials design, Microsoft Research.
Introduces MatterGen, a generative model designed to create stable and diverse inorganic materials by leveraging a diffusion-based approach. Unlike previous models, which struggle with stability and flexibility, MatterGen refines atom types, coordinates, and lattice structures in a controlled manner, significantly improving the likelihood of generating novel, synthesizable materials.
MatterGen outperforms existing generative models by doubling the success rate in producing stable, unique, and novel materials while generating structures that are significantly closer to their energy minima.
To validate MatterGen’s predictions, the researchers synthesized a generated material (TaCr₂O₆) and measured its bulk modulus, finding it within 20% of the predicted value. Additionally, the model re-discovered over 2,000 experimentally verified structures unseen during training. While MatterGen marks a significant advance in generative materials design, the study acknowledges areas for improvement, such as symmetry bias and broader property optimization.
De novo designed proteins neutralize lethal snake venom toxins, University of Washington, Technical University of Denmark.
Presents a novel approach to treating snakebite poison by designing de novo proteins that neutralize lethal three-finger toxins (3FTx) found in elapid snake venoms.
The study used RFdiffusion to create proteins that physically block snake venom toxins from binding to nerve receptors (nAChRs). They developed two main antitoxins - SHRT for short-chain toxins and LNG for long-chain toxins like α-cobratoxin - both achieving nanomolar binding strength. They also designed CYTX to target tissue-destroying toxins. Crystal structures confirmed the proteins matched their computer designs, and experiments showed they protected cells from toxin damage. In mice, both SHRT and LNG prevented death whether given before or after venom exposure.

These engineered proteins improve upon traditional antivenoms in several ways: they're more specific, maintain stability better, and can be produced cheaply in bacteria without animal immunization. Their compact structure may help them penetrate tissues better, and their stability could eliminate cold storage requirements, making them practical for remote areas.
Transformer2: Self-adaptive LLMs, Sakana AI.
Introduces Transformer2, a novel framework for creating self-adaptive large language models that can dynamically adjust to different tasks without extensive retraining. The core innovation is Singular Value Fine-tuning (SVF), which modifies only the singular values within a model's weight matrices to create specialized "expert vectors" for different capabilities like coding, math, and reasoning.
The framework employs a two-pass system during inference - first analyzing the input to determine required skills, then applying the appropriate combination of expert vectors to optimize performance. This approach requires significantly fewer parameters than existing methods like LoRA while achieving better results across multiple model architectures and tasks.

The researchers demonstrate Transformer2's effectiveness through extensive experiments with various LLMs including Llama3 and Mistral models. They show it can improve performance not just on tasks it was directly trained for, but also on entirely new tasks through intelligent adaptation of its expert vectors. This includes successfully transferring knowledge between different model architectures.
A particularly notable aspect is the framework's efficiency. It achieves these improvements while using only a fraction of the parameters required by other fine-tuning methods. The system also shows promising results in cross-model compatibility, suggesting potential for knowledge transfer between different LLMs, though this currently works best between architecturally similar models. It’s fun to see new architecture research gaining traction.
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, DeepSeek.
This work builds on DeepSeek’s strong base language model, V3, released in December 2024, to introduce the company’s first reasoning models, the R-series. In particular, they show that LLMs can develop reasoning capabilities without the use of any supervised finetuning (SFT) data, but with reinforcement learning instead. A few features of this paper are interesting:
The reward system that produces signals for the model to improve through RL is no longer a neural network, but is a simpler rule-based. It is composed of accuracy rewards (whether the response is correct) and format rewards (whether the model displays its thinking process correctly). The additional benefit here is that the RL step is less susceptible to reward hacking, doesn’t need to be trained and results in a simpler overall training pipeline.
The first model they produce, DeepSeek-R1-Zero, is built from V3-Base with RL applied as above directly with no SFT data. While R1-Zero starts out at 15.6% average pass@1 score on AIME 2024 mathematics benchmark, the model hits 71% after 8.5k RL training steps. This is better than OpenAI’s o1-mini and just shy of o1-0912’s score of 74.4%. With majority voting (cons@64), in which multiple outputs are aggregated to determine the most accurate response, R1-Zero outperforms o1-0912.

The learning process of R1-Zero is equally interesting. The model “naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time computation.” Indeed, as training steps increase, the average length of the model’s responses increases. Further, the authors observe the emergence of novel behaviors as test-time computation increases. This includes reflection, where a model reevaluates its reasoning steps, and exploration, by which it spontaneously decides to try other problem-solving approaches. Midway during its RL steps, the model finds an “aha moment” where it spontaneously “learns to allocate more thinking time to a problem by reevaluating its initial approach. This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes”.

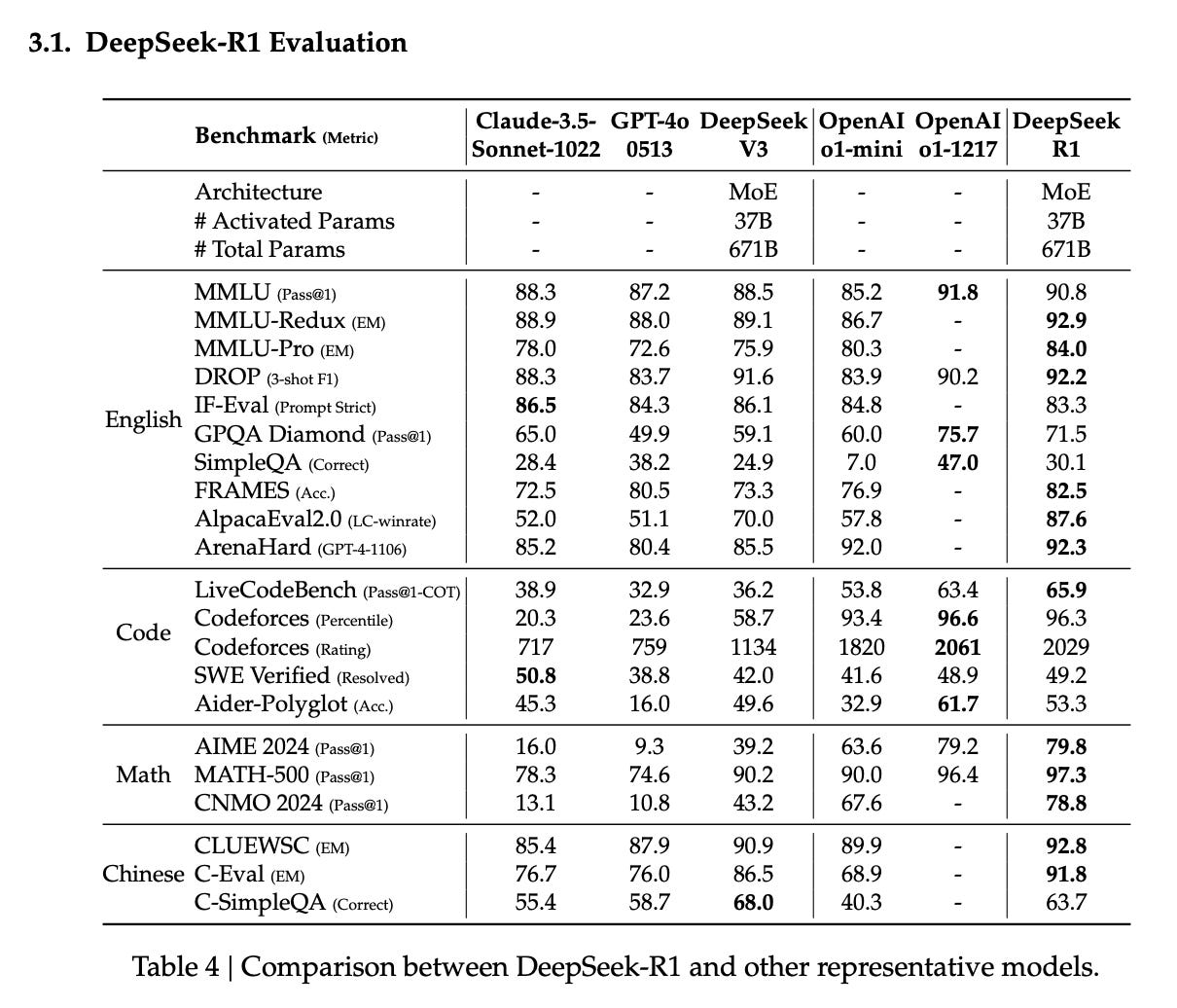
With the drawback of R1-Zero being poor readability and language mixing, the authors produce DeepSeek-R1, which applies RL starting from a V3-Base checkpoint that is fine-tuned with thousands of long CoT examples generated in different ways. They also introduce a language consistency reward during RL training to encourage the model to reason in the same language as the prompt. Once the RL stage is finished, they move onto finetuning the model with 800k samples of SFT data collected from other domains to enhance the model’s capabilities in writing, role-playing, and other general-purpose tasks. Finally, they implement a second round of RL to improve the model’s helpfulness and harmlessness while improving its reasoning. Here are R1’s evaluations, which are particularly strong vs. o1-1217, surpassing it at a number of evals.
Notable too is that the paper explored Monte Carlo Tree Search to enhance test-time compute scalability. However, they found that this approach doesn’t scale well during training because a) the search space of generated tokens is enormous and if the extension limit for each node is restricted, then the model tends to get stuck in local optima, and b) the complexities of token generation make the training of a value model inherently difficult. They also show that R-1 is a strong teacher model that, if tasked with generating 800k training samples, can be used to effectively fine-tune smaller dense models.
Also on our radar:
On the Feasibility of Using LLMs to Execute Multistage Network Attacks, Anthropic, Carnegie Mellon University. Introduces Incalmo, a high-level abstraction layer that significantly improves LLMs ability to execute complex multistage network attacks. While current LLMs struggle with these attacks (succeeding in only 1 out of 10 test environments), Incalmo enables them to succeed in 9 out of 10 environments. It does so by allowing LLMs to specify high-level tasks rather than low-level commands, providing an attack graph service to guide decision-making, and offering an environment state service to track network information. The research also shows that smaller LLMs using Incalmo outperform larger models without it.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents, ByteDance. Presents UI-TARS, a new type of graphical user interface agent model that uses screenshots as input and performs human-like interactions, such as keyboard and mouse operations. UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks, including OSWorld and AndroidWorld, surpassing Claude and GPT-4o respectively. Key innovations include enhanced perception, unified action modeling, system-2 reasoning, and iterative training with reflective online traces. UI-TARS leverages large-scale datasets for context-aware understanding, precise grounding, and deliberate reasoning. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations.
Humanity’s Last Exam, Center for AI Safety, Scale AI. Presents Humanity's Last Exam, a new frontier-level benchmark designed to test the limits of LLMs through 3,000 extremely challenging questions across dozens of academic subjects. Created by nearly 1,000 subject matter experts from over 500 institutions, the benchmark emphasizes mathematical reasoning and includes both text-only and multi-modal questions, with all questions being original, precise, unambiguous, and resistant to simple internet lookup. Unlike existing benchmarks that have been largely solved by current LLMs (with >90% accuracy) - even the best models achieve less than 10% accuracy and show poor calibration.
Evolving Deeper LLM Thinking, Google DeepMind. Introduces Mind Evolution, an evolutionary search strategy that helps LLMs solve complex natural language planning problems. The approach uses genetic algorithms where an LLM acts as both a generator of solutions and a refiner, iteratively improving solutions based on evaluator feedback. Unlike previous methods that require formalizing problems or rely on step-by-step verification, Mind Evolution operates directly in natural language space and only needs a global solution evaluator. The method achieved significant improvements over baseline approaches on travel planning and meeting scheduling tasks, reaching success rates over 95% on several benchmarks when using Gemini 1.5 Flash, and nearly 100% success with Gemini 1.5 Pro - all without requiring formal solvers. The authors also introduced a new benchmark called StegPoet to demonstrate the method's effectiveness beyond standard planning problems.
Trading inference-time computer for adversarial robustness, OpenAI. Explores a novel approach to improving the adversarial robustness of LLMs through increasing inference-time compute rather than traditional adversarial training. The researchers tested various models (specifically OpenAI's o1-preview and o1-mini) against different types of attacks, finding that simply allowing models to have more computation time during inference led to improved robustness across multiple attack types - from jailbreaks to adversarial images. Unlike adversarial training, which requires anticipating specific attack types, this approach improves robustness without requiring prior knowledge of potential attacks. This is intuitively like thinking a bit more before acting, it tends to give rise to better outcomes :-)
Inference-Time-Compute: More Faithful? A Research Note, Truthful AI. Examines whether AI models specifically trained to generate long chains of thought (called Inference-Time-Compute or ITC models) are more "faithful" in acknowledging factors that influence their decisions. The researchers tested two ITC models based on Qwen and Gemini against several non-ITC models by adding various cues to prompts (like "A Stanford Professor thinks the answer is D") and checking if the models would acknowledge these cues when they influenced their answers. The ITC models were significantly better at articulating when cues influenced their decisions - in some cases acknowledging cues over 50% of the time compared to under 15% for non-ITC models.
💰Startups
🚀 Funding highlight reel
Anthropic, makers of Claude, raised a further $1B from Google.
Bioptimus, building generative AI models for biotech, raised a $41M Series A, led by Cathay Innovation.
Collate, automating paperwork in biotech, raised a $30M seed, led by Redpoint.
Coram*, applying AI to physical security, raised a $30M Series A, led by Battery Ventures.
ElevenLabs*, the audio generation start-up, raised $180M Series C, led by a16z and ICONIQ Growth.
Eve, automating plaintiff legal services, raised a $47M Series A, led by a16z.
Hippocratic AI, handling non-diagnostic patient-facing tasks, raised a $141M Series B, led by Kleiner Perkins.
KoBold Metals, applying AI to mining for the energy transition, raised a $537M Series C, co-led by T Rowe Price and Durable Capital Partners.
Lindus Health, automating the clinical trials process, raised a $55M Series B, led by Balderton Capital.
NEURA Robotics, the humanoid company, raised a $125M Series B, led by Lingotto Investment Management.
Overland AI, developing software for autonomous ground vehicles, raised a $32M Series A, led by 8VC.
Raspberry AI, using AI for fashion design, raised a $24M Series A, led by a16z.
Sereact*, building AI-first software for robotics, has raised a $26M Series A, led by Creandum.
Slingshot, building a foundation model for psychology, raised a $40M Series A, led by a16z.
Synthesia*, the AI avatar generation platform, raised a $180M Series D, led by NEA.
ThreatMark, using AI to fight online fraud, raised a $23M funding round, led by Octopus Ventures.
* denotes companies in which the authors hold shares.
🤝 Exits
Flowrite, the email division of LLM evaluation company Flow AI, was acquired by Maestro Labs.
Signing off,
Nathan Benaich and Alex Chalmers on 2 February 2025
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | Events
Air Street Capital invests in AI-first entrepreneurs from the very beginning of your company-building journey.

"While people have mocked the likes of Satya Nadella for suddenly discovering the Wikipedia page for Jevons Paradox - the notion that improved efficiency leads to greater demand - we think it holds true here"
any evidence that there is latent demand that will adopt ai once it gets cheaper due to efficiency gains?
trying to understand why people are assuming generative ai has elastic demand as flexible as coal from jevons' time